
'AI 4대 구루'중 한 사람으로 널리 알려진 제프리 힌튼 토론토 대학 컴퓨터 과학 교수는 이미지 분석에 있어 3D 포인트 클라우드를 위한 '비지도 캡슐 아키텍처' 기술을 제시했다.
인공지능(AI)과 IT 정보 매체 씽크드(Synced)는 제프리 힌튼(Geoffrey Hinton) 교수의 트위터를 언급하며 힌튼 교수가 이미지 분석에 있어 포인트 클라우드 기술을 위한 기술 개념을 제시했다고 18일(현지시간) 보도했다.
힌튼 교수는 11일 자신의 트위터를 통해 "비지도 방법으로 객체의 자연스러운 부분과 본질적 좌표 프레임을 찾는 것은 이미지 분석 방법을 학습하는 데 중요한 단계"라며 "포인트 클라우드로 이것을 가능하게 할 것"이라고 언급했다
매체는 힌튼 교수의 트위터가 그의 새로운 논문 내용에 따른 언급이라고 설명했다.
그는 캐나다 브리티시컬럼비아 대학, 토론토 대학, 빅토리아 대학, 구글 리서치팀 등과 공동 연구를 수행해 '표준 캡슐 : 표준 포즈에서 비지도 캡슐(Canonical Capsules: Unsupervised Capsules in Canonical Pose)' 보고서를 지난 8일 발표했다.
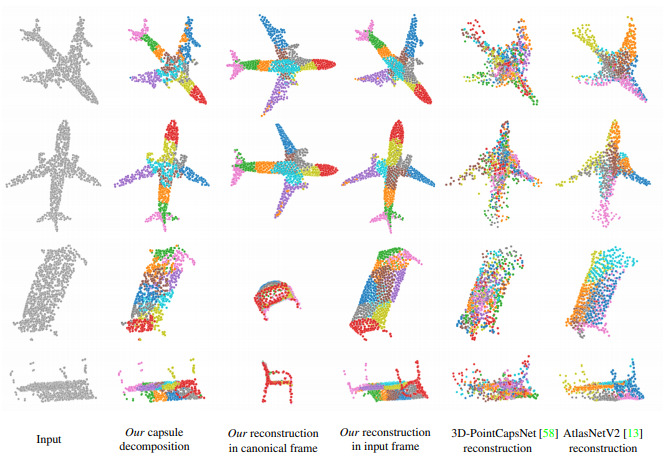
연구팀은 이 보고서에서 캡슐을 바탕으로 3D 포인트 클라우드와 함께 비지도 학습을 위한 아키텍처를 제안했다.
자율주행 기술기업 OxTS에 따르면, 포인트 클라우드는 3D 공간 점(Point)들의 집합으로 각 점들은 다른 특징을 갖는다. 데이터 수집하는 측량 장치로 각 점이 갖고 있는 위치의 강도와 오차 등을 포함할 수 있다. 3D 사진을 만드는 데 사진 측량 기술을 활용해 포인트 클라우드에 사진을 오버레이할 수 있다.
포인트 클라우드 데이터를 수집하는 주요 방법은 라이다(LiDAR)를 사용하는 것이다. 라이다 장치는 고정적인 수직 각도를 갖지만 수평면에서 회전하는 레이저를 포함한다. 이에 장치 내부에서 레이저가 어떤 각도로 수직을 가리키는 지 알고 있다. 이는 3D 구형 좌표에서 객체별 점의 위치를 라이다 장치에게 제공한다.
캡슐은 2011년 힌튼 교수가 ‘자동 인코더 변환(Transforming Auto-encoders)’ 논문을 통해 제시한 개념이다.
이 연구에서 힌튼 교수는 컨볼루션 신경망(CNN)이 컴퓨터 비전에서 이미지를 인식하는 데 잘못 이해할 수 있다며, 이를 위한 입력에 복잡한 내부 계산을 수행한 뒤 유익한 출력으로 캡슐화할 수 있는 로컬 캡슐의 사용을 제안했다.
캡슐은 이미지 분석에 있어 미묘한 차이를 인코딩하고 이해하는 데 훌륭한 능력을 보인다. 이에 인간 두뇌의 모듈과 유사하다. 캡슐 네트워크는 상호 연관된 부분의 조직화한 집합을 기하학적으로 해석해 물체를 이해한다.
예를 들어, 사람의 얼굴은 눈이 두 개 있으며 코와 입이 하나씩 있다. 기존 CNN은 눈ㆍ코ㆍ입의 방향, 위치, 구조 등과 관계없이 눈ㆍ코ㆍ입을 가진 물체라면 인간의 얼굴이라고 판단하는 경우가 간혹 있었다. 하지만 캡슐을 활용할 경우 이 같은 문제를 해결할 수 있다.
이번에 발표한 논문에서 연구팀은 캡슐 네트워크로 3D 심층 표현을 훈련할 때 장면을 부분 계층 구조로 분해해 인식한다고 설명했다. 이어 동일한 객체의 무작위로 순환하는 3D 포인트 클라우드 쌍(Pair)을 관찰함으로써 비지도 방식으로 훈련한 캡슐 아키텍처를 제안했다.
이 논문에 참여한 안드레아 탈리아사치(Andrea Tagliasacchi) 구글 브레인 리서치 과학자는 "이 개념이 비지도된 3D 딥러닝을 위한 '정신적 그림'의 개념을 실현하고 있다"고 말했다. 이어 자신의 트위터를 통해 "이 표현은 정규화, 재구성, 비지도 분류 등 여러 애플리케이션에 걸쳐 최신 결과를 가능하게 한다"고 언급했다.
AI타임스 김재호 기자 jhk6047@aitimes.com
