
인공지능(AI)의 이미지 인식·처리 능력이 날로 발전하고 있다. 라벨링 등 사람의 도움이 없어도 스스로 객체를 분류하며, 추상적 이미지를 떠올리는 '연상' 능력까지 갖춰나가고 있는 모습이다.
4일(현지시간) 페이스북과 오픈AI는 각각 개발하고 있는 이미지 인식 AI에 대한 새 소식을 전했다. 페이스북은 자기지도학습법으로 스스로 이미지 인식법을 배우는 AI 모델 SEER(Self-supERvised)를 공개했다.
오픈AI는 앞서 발표했던 CLIP(Contrastive Language-Image Pre-Training)이 다중양식 신경세포(Multimodal Neuron) 방식을 통해 추상적 이미지 인식이 가능하다는 걸 발견했다고 전했다.
◆페이스북 ‘SEER’, 자기지도학습으로 이미지 인식 방법까지 익혀

페이스북 AI 연구소(FAIR, Facebook AI Research)가 이번에 공개한 SEER는 라벨링된 데이터가 없어도 이미지를 인식할 수 있다. 자기지도학습을 통해 이미지를 스스로 분류·인식하는 딥러닝 모델이다. 자기지도학습은 스스로 학습 데이터를 수집하고 만들어내는 학습 방식을 말한다. 사람이 지정해준 데이터 레이블을 학습하는 지도학습과 다른 점이다.
SEER는 인스타그램 10억 개 사진을 사전 학습해 이미지를 스스로 인지하는 방법을 익혔다. 하단에서 올려다보며 찍은 로우샷(Low-Shot) 사진 등 다소 다양한 각도의 이미지까지 인식 가능하다. 여러 이미지를 하나의 카테고리로 스스로 분류하고, 한 이미지 속 여러 객체를 세분화하는 것도 가능하다.
이미지 인식 정확도는 84.2%에 달한다. 페이스북은 이미지넷(ImageNet) 데이터 세트를 기반으로 SEER 능력을 평가했다. 이미지넷은 1400만 개 이미지를 보유하고 있는 데이터베이스 세트다. 인스타그램 사진이 아닌 이미지넷 데이터의 10%를 가지고 훈련했을 때도 SEER는 77.9% 정확도로 이미지를 인식했다. 약 140만 장의 사전학습만으로도 80%에 육박하는 정확도를 갖추는 모습이다.
◆인간처럼 이미지 ‘연상’... 라벨링 데이터 없어도 다양한 이미지 인식·처리
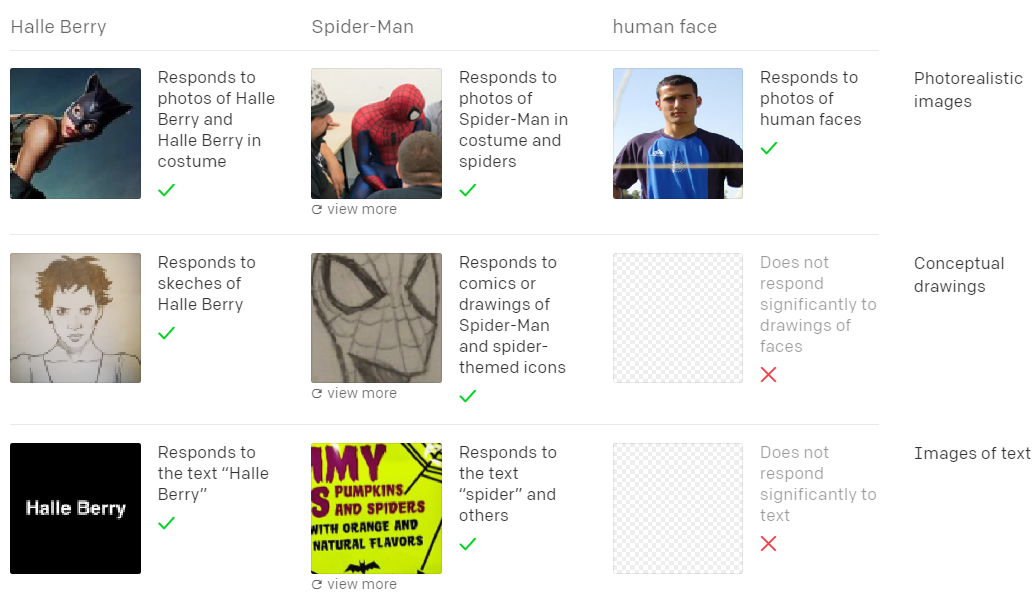
오픈AI는 CLIP이 다중양식 신경세포(Multimodal Neuron) 방식을 통해 추상적 이미지 인식이 가능하다는 걸 발견했다고 전했다.
CLIP은 언어를 이미지로, 이미지를 언어로 이해할 수 있도록 일종의 ‘다리’를 놓아주는 딥러닝 모델이다. 지난 1월 오픈 AI가 블로그를 통해 공개했다.
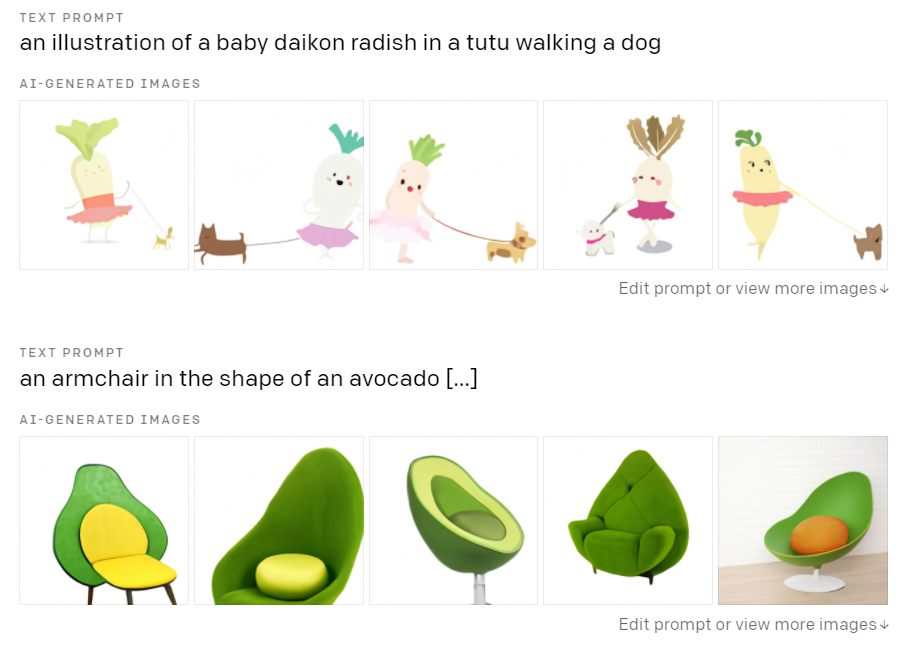
언어를 입력하면 이미지를 구현하는 AI 모델 DALL-E에게도 CLIP은 중요한 역할을 담당한다.
‘개를 산책시키는 무’라는 얼토당토않는 언어 명령을 입력하면 DALL-E는 여러 장의 이미지를 생성한다. 이때 CLIP은 DALL-E가 만든 이미지가 명령 언어를 잘 수행했는지 검사한다. 사진마다 정확도로 점수를 매겨 정교하게 구현된 이미지를 선별하는 식이다.
DALL-E가 추상적이고 엉뚱한 명령에도 이미지를 생성할 수 있는 이유는 CLIP이 다중양식 신경세포 능력을 갖추고 있기 때문이다. 다중양식 신경세포란 하나 이상의 감각에 반응하는 신경세포다.
‘거미’라는 텍스트를 입력할 경우 CLIP은 거미와 관련된 만화 캐릭터 ‘스파이더맨’을 떠올리는 게 가능하다. 그동안 AI에게는 거미를 입력하면 ‘거미’라고 라벨링된 이미지만을 불러올 수 있었다.
이는 AI가 인간의 ‘연상’ 능력을 갖췄다는 것을 뜻한다. 인간의 경우 거미라는 말을 들었을 때, 거미와 관련된 경험 등 추상적 이미지를 연달아 떠올릴 수 있다.
CLIP이 다중양식 신경세포 방식으로 작동한다는 것은 AI에게 따로 라벨링된 정보를 주지 않아도 다양한 이미지를 인식·처리할 수 있다는 것을 뜻한다.
◆연상하고 스스로 배우고... AI의 ‘눈’ 발달하고 있지만 아직 한계점도
CLIP이 다중양식 신경세포 방식을 통해 다양한 이미지를 떠올릴 수 있다는 발표는 획기적이었다. 하지만 오픈AI는 CLIP이 너무 허술한 약점을 지니고 있다는 내용도 함께 공개했다.
‘타이포그래피 공격(Typography Attack)’ 이라고 불리는 오류가 그렇다. 사과 사진에 ‘iPOD’이라는 문구를 적어 넣으면 CLIP은 사과 이미지를 무시하고 글자를 우선 인식했다. 이는 CLIP이 자연어처리 기술을 기반으로 하기 있기 때문이다.

SEER의 경우 성능을 유지하기 위해서는 수조 단위 단어와 함께 방대한 매개 변수를 주기적으로 학습해야 한다. ‘고양이’ 이미지는 고양이의 자세와 사진을 찍은 각도에 따라 다양하기 때문이다. 이에 엄청난 컴퓨팅 능력이 필요하다.
페이스북의 경우 이를 극복하기 위해 SwAV 알고리즘을 활용한다. 온라인 데이터를 군집화해 유사한 시각 이미지를 효율적으로 처리하는 알고리즘이다. 이에 SEER의 학습 시간을 1/6로 단축했다.
챗봇 코리아 리더 우종하는 "CLIP을 통해 딥러닝에서도 실제 뇌와 마찬가지로 '할리 배리 뉴런(특정 대상을 보고 반응하는 신경세포)'이 있다는 것을 확인했다"라며 "이는 단순히 이미지가 아니라 개념 자체를 추상화한다고 볼 수 있다"고 말했다.
덧붙여 "CLIP은 ImageNet처럼 사람이 라벨링하지 않는다. 인터넷에서 사진과 그 설명을 수집해 학습한다"라며 "이게 가능한 이유는 사진과 라벨을 1:1로 매칭하지 않기 때문이다. 사진의 개념과 텍스트의 개념을 별도의 인코더로 추상화한 후 이 둘을 비교한다"라고 설명했다.
이어 "요즘 추세가 자기지도학습으로 라벨링에 들어가는 수고를 줄이고 있다"라고 말했다.
AI타임스 장희수 기자 heehee2157@aitimes.com
