
사람이 넘어지지 않고 자전거 타는 법을 배우는 것과 유사하게 로봇이 넘어지지 않고 이동하는 법을 자율적으로 배우게 하는 기술이 나왔다. 구글은 훈련 과정에서 로봇의 안전 조건을 충족하면서 다리 보행 기술을 학습하기 위한 안전 강화학습(RL, Reinforcement Learning) 프레임워크를 블로그에 소개했다.
복잡하고 고차원적인 문제를 자율적으로 해결하기 위한 심층 강화학습은 로봇, 게임, 자율주행 자동차와 같은 분야에서 많은 관심을 불러일으켰다. 그러나 효과적으로 강화학습을 하려면 로봇에 안전하지 않은 조건들을 파악해야 한다. 예를 들어 다리가 있는 로봇을 훈련할 때 상당한 위험이 있다. 이런 로봇은 본질적으로 불안정하기 때문에 학습 중에 로봇이 넘어져 손상을 입을 가능성이 높다.
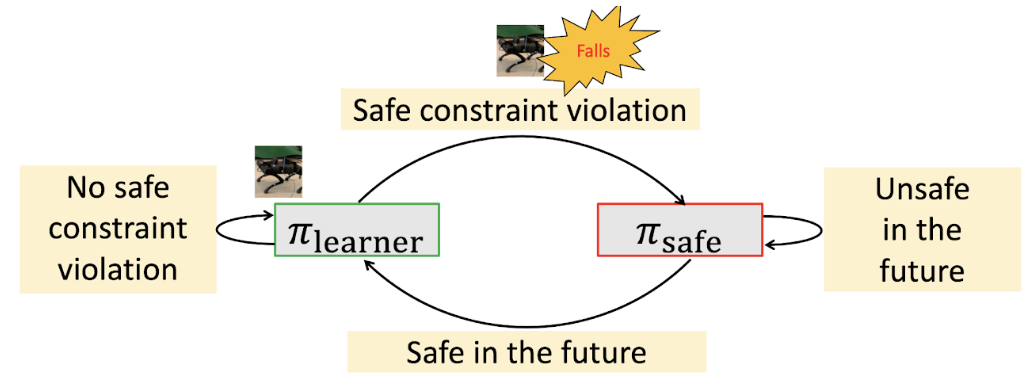
구글의 안전 RL 프레임워크는 전체 학습 과정에서 로봇이 넘어지지 않고 실제 세계에서 자율적으로 이동 기술을 배우는 것을 목표로 한다. 이 프레임워크는 넘어질 가능성이 높은 상태에서 로봇을 안전한 상태로 복구하는 ‘안전 복구 정책(safe recovery policy)’과 로봇이 주어진 작업을 안전하게 수행할 수 있는 상태를 유지하는 ‘학습자 정책(learner policy)’을 채택한다. 프레임워크 내에서 로봇의 안전 상태에 따라 안전 복구 정책과 학습자 정책 사이를 전환하면서 로봇이 새롭고 민첩한 운동 기술을 안전하게 습득할 수 있도록 한다.
먼저 로봇이 넘어질 가능성이 있지만 안전 복구 정책에 의해 넘어지지 않고 복구될 수 있는 ‘안전 트리거 세트(safe trigger set)’를 정의한다. 안전 트리거 세트는 로봇의 높이나 기울어진 각도 등의 값을 이용해 정의할 수 있다. 학습자 정책 내에서 로봇이 안전 트리거 세트에 있는 경우(즉, 넘어질 가능성이 있는 위치) 로봇을 안전한 상태로 되돌리기 위해 안전 복구 정책으로 전환한다.
그런 다음 로봇의 움직임에 대한 역학 모델을 활용해 로봇 궤적을 미리 예측하고 언제 학습자 정책으로 다시 전환할지 결정한다. 예를 들어 로봇 다리의 위치와 롤(roll), 피치(pitch), 기울기(yaw) 센서를 이용해 로봇이 넘어질 가능성이 있는지를 예측하고, 예측된 상태가 안전하면 제어를 학습자 정책에 다시 넘기고 그렇지 않으면 안전 복구 정책을 계속 사용한다.
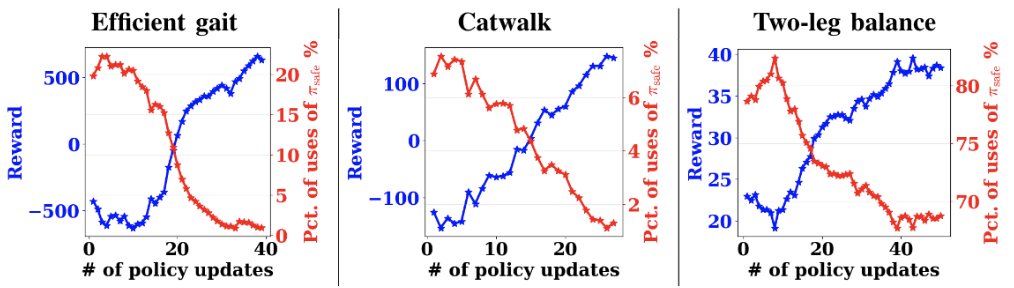
안전 RL 프레임워크는 알고리즘의 효율성을 입증하기 위해 세 가지 다리 이동 작업 ▲효율적인 보행(Efficient Gait) ▲캣워크(Catwalk) ▲두 다리 균형(Two-leg Balance) 을 훈련한다.
효율적인 보행에서 로봇은 낮은 에너지 소비로 걷는 방법을 배우고 에너지 소비가 적으면 보상(reward)을 받는다. 캣워크에서 로봇은 왼쪽과 오른쪽의 두 발이 서로 가까이 있는 캣워크 보행 패턴을 학습한다. 로봇은 4개의 발로 구성되는 지지 다각형(support polygon)을 좁히면 보상을 받는다. 두 다리 균형에서 로봇은 전방 우측발과 후방 좌측발이 제 위치에 있고 나머지 두 발은 들어올리는 균형 작업을 학습한다. 로봇은 땅에 접촉하는 지지 다각형이 선으로 바뀌기 때문에 섬세한 균형 제어가 없으면 쉽게 넘어질 수 있다. 로봇이 두 발로 서서 특정 높이 이상 유지하면 보상을 받는다.
로봇은 학습자 정책 내에서 각 훈련의 기준을 만족하면 보상을 받지만 안전 트리거 세트에 의해 안전 복구 정책을 트리거하게 되면 패널티를 받게 된다.

전반적으로 이러한 작업에서는 보상이 증가하고 안전 복구 정책의 사용 비율이 감소하는 것을 알 수 있다. 예를 들어 효율적인 보행 훈련에서 안전 복구 정책의 사용 비율은 20%에서 거의 0%로 감소한다. 두 다리 균형 작업의 경우 82.5%에서 67.5%로 감소하지만 다른 두 훈련보다 훨씬 더 어렵다는 것을 보여준다. 그래도 정책은 보상을 향상시킨다. 이 관찰은 로봇이 안전 복구 정책을 트리거할 필요를 피하면서 점차적으로 작업을 학습할 수 있음을 의미한다. 또한 이는 성능이 증가함에 따라 작업을 방해하지 않는 안전 트리거 세트 및 안전 복구 정책을 설계할 수 있음을 시사한다.
다음 영상은 학습자 정책과 안전 복구 정책의 상호작용, 복구 종료 시 초기 위치로 재설정하는 등 두 다리 균형 작업에 대한 정책 학습 과정을 보여준다. 로봇이 넘어질 때 들어올린 다리(전방 좌측 및 후방 우측)를 바깥쪽으로 내려 지지 다각형을 만들어 로봇이 스스로 균형을 잡으려고 하는 것을 볼 수 있다. 복구가 끝나면 로봇은 자동으로 재설정 위치로 돌아간다. 이를 통해 사람의 감독 없이 자율적으로 안전하게 정책을 학습할 수 있다.



마지막으로 정책 학습이 완료된 영상을 보여준다. 캣워크 작업에서 다리의 두 측면 사이의 거리는 0.09m로 정상적인 거리보다 40.9% 작다. 특히 두 다리 균형 작업에서 로봇은 두 다리를 이용해 최대 4번까지 점프하여 균형을 유지할 수 있다.

구글은 안전한 RL 프레임워크를 제시하고 효율적인 보행 및 캣워크 작업을 위한 전체 학습 프로세스 동안 넘어짐이나 수동 재설정 없이 로봇 정책을 훈련하는 데 사용할 수 있는 방법을 시연했다. 이 접근 방식을 사용하면 단 4번의 넘어짐으로 두 다리 균형 작업을 훈련할 수도 있다. 안전 복구 정책은 필요할 때만 트리거되어 로봇이 환경을 보다 완벽하게 탐색할 수 있다. 결과는 다리 보행 기술을 자율적이고 안전하게 학습하는 것이 현실 세계에서 가능하다는 것을 시사한다.
또한 안전 복구 정책을 통합할 때 적절한 보상을 설계하면 학습 성과에 영향을 미칠 수 있다. 다시 말해 로봇에게 당근을 주면 더 빨리 길들일 수 있다.
AI타임스 박찬 위원 cpark@aitimes.com
