
AMD와 엔비디아(NVIDIA) 간의 고성능 GPU 영역 싸움에 중국 스타트업 바이렌 테크놀로지(Biren Technology)가 끼어들었다.
HPCwire는 22일(현지시간) 중국 상하이에 위치한 바이렌 테크놀로지가 가상공간에서 열린 핫칩스(HC34) 컨퍼런스에서 범용 GPU(GPGPU) 'BR100'을 선보이며 GPU 시장에 참여를 선언했다고 보도했다.
바이렌의 첫 제품인 'BR100'은 1074㎟ 면적에 770개 트랜지스터를 집적한 것과 같은 효과를 내는 제품이다. FP32(32비트 부동소수점) 기준 256 테라플롭스(TFLOPS)에 달하는 성능을 낼 수 있다. 다이 간 상호 연결은 초당 896GB 대역폭을 제공한다. 대만 TSMC의 7나노(nm) 공정에서 제조한다.
BR100은 최대 64GB의 HBM2E 메모리(4개의 스택에 걸쳐)와 함께 제공되며 8중 BLink 연결 중 외부 I/O 대역폭에서 최대 2.3TB/s를 관리할 수 있다. 이 모든 것이 550W의 최대 TDP(Thermal Design Power)와 1GHz의 목표 클록 주파수에 추가된다.
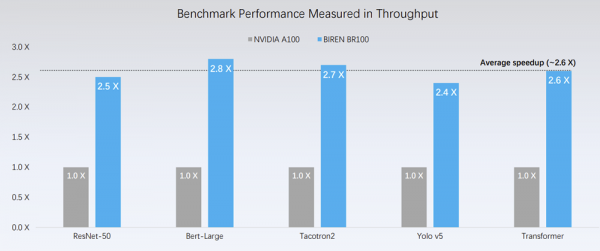
가속기 분야의 기준이 되는 엔비디아의 A100 GPU와 비교할 때, BR100의 최고 테라플롭은 A100과 비교할 수 없을 정도로 유리하다. A100의 경우 19.5, BR100의 경우 256이다. BR100은 세계에서 가장 빠른 GPU 가운데 하나다.
링지 시우(Lingjie Xu) 바이렌 공동설립자 겸 CEO는 "현재 단계에서 엔비디아 A100과 비교해 컴퓨터 비전, 자연어 처리 및 대화형 AI를 포함한 다양한 영역의 광범위한 벤치마크에서 평균 2.6배의 속도 향상을 보고 있다"며 "우리가 하드웨어와 소프트웨어를 계속 최적화함에 따라 앞으로 몇 개월 동안 성능이 계속 향상될 것"이라고 주장했다.
바이렌은 PCIe 카드에 사용하도록 설계된 단일 다이 변형인 BR104도 제공한다. 칩은 이미 실리콘에서 테스트했다. 지금은 참조 클러스터 디자인을 구축하기 위해 제조업체와도 협력하고 있다.
바이렌은 인스퍼(Inspur)와 손잡고 8웨이 하튼(hearten) OAM 서버를 공동 출시했다. 양사는 올해 4분기부터 하드웨어 샘플링을 시작할 것으로 예상하고 있다.
장치는 바이렌수파(BIRENSUPA)라고 하는 바이렌의 자체 소프트웨어 플랫폼 및 프로그래밍 모델과 함께 제공된다. 바이렌의 CTO인 마이크 홍(Mike Hong)은 "엔비디아의 CUDA에 익숙한 개발자는 SUPA용 코드를 쉽게 작성할 수 있다"라고 말했다. 지원되는 AI 프레임워크에는 파이토치(PyTorch), 텐서플로우(TensorFlow) 및 패들패들(PaddlePaddle)이 포함되며, OpenCL 컴파일러도 제공한다. 이중 다이 BR100은 소프트웨어 계층에 하나의 GPU로 나타난다.
AI타임스 박찬 위원 cpark@aitimes.com
