
지난 21일부터 23일까지 미국 실리콘밸리에서 열린 '핫칩스34' 행사는 인텔, AMD, NVIDIA 등 주요 반도체 기업의 향후 전략을 엿볼 수 있는 자리였다. 이들은 조만간 출시할 예정인 반도체 차기작과 함께 새로운 생산전략을 공개했다.
인텔은 내년에 출시할 예정인 3D 적층 구조 프로세서 '메테오레이크(Meteor Lake)'를 공개하면서 그동안과는 전혀 다른 생산 전략을 내놓았다.
핵심 제품(CPU 타일)은 내부에서 만들지만 일부 제품은 외부 파운드리를 활용해 생산해 결합한다는 내용이다.
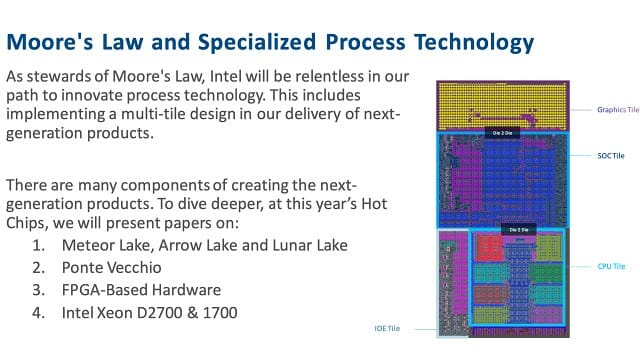
인텔은 이를 위해 서로 다른 공정에서 생산한 타일 단위 반도체를 그릇 역할을 하는 '베이스 타일' 위에 얹어 완성하는 새로운 형태의 제조 방식을 선보였다. 그동안에는
CPU와 내장 그래픽칩셋 및 입출력 관련 다이를 한 데 넣은 모놀리식(Monolithic) 방식으로 제조해 왔다.
이는 필요하다면 파운드리 시장에서 경쟁을 벌이고 있는 삼성전자나 TSMC 등 외부 파운드리를 적극 이용하겠다는 펫 겔싱어 CEO의 'IDM 2.0' 전략을 실행에 옮긴 것으로 보인다. 펫 겔싱어는 지난해 취임한 직후 이같은 내용을 핵심으로 하는 전략을 공개했다.
인텔은 컴퓨트 타일(CPU)과 GPU 타일, 입출력을 담당하는 I/O 타일과 AI 가속을 담당하는 SoC(시스템 반도체) 타일 등은 모두 자체 설계하지만 컴퓨트 타일 이외의 모든 타일은 외부에서 조달할 계획이다. 대만 TSMC가 가장 유력한 외부 파운드리로 꼽히고 있다.
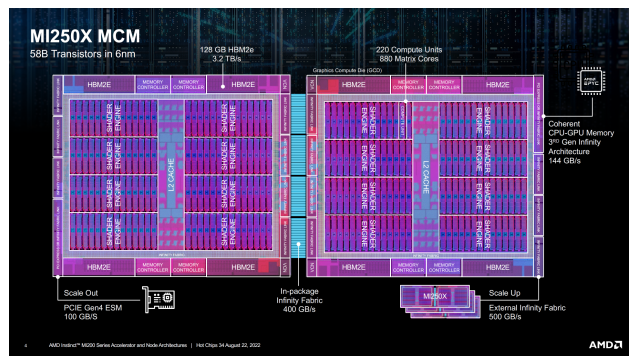
AMD도 조만간 출시할 MI250X MCM GPU 설계 전략을 자세하게 공개했다. MI250X는 현존하는 최상위 엑사스케일 슈퍼컴퓨터에 탑재할 목적으로 성능을 극대화한 새로운 아키텍처다. TSMC 6nm 공정에서 생산할 계획이다.
MI250X MCM GPU는 기존 MI100 GPU와 비교해 FP64 Matrix 성능이 3.8배 증가하고 FP32 및 FP16 성능은 2.1배 증가한 것이 특징이다. 총 580억개의 트랜지스터를 2개의 GPU에 탑재했다. 128GB 용량의 HBM2e 메모리와 3.2TB/s급 메모리 대역폭을 제공한다.
AMD는 MI250X GPU를 구성하는 10개의 칩을 보유하고 있다. GPU 다이와 HBM2 메모리 다이가 혼합돼 있는데, 각 GPU 다이는 110개의 컴퓨팅 유닛으로 구성됐다. MCM GPU에는 총 220개의 컴퓨팅 유닛이 있다. GPU당 7168개의 스트림 프로세서로 분할해 총14080개의 스트림 프로세서를 제공한다.

엔비디아는 ARM 인수 실패 후 자체 인력으로 개발하고 있는 서버용 프로세서 '그레이스(Grace)'를 발표했다. 장치 및 시스템 수준에서 전력 소비와 성능을 최적화하면서 데이터 센터 컴퓨팅, 특히 AI 처리를 위해 설계한 CPU다.
엔비디아의 전략은 이를 통해 Arm IP를 기반으로 GPU와 CPU를 결합한 아키텍처를 설계, 대규모 AI와 HPC(고성능 컴퓨팅)를 실현하겠다는 전략이다.
Grace CPU는 엔비디아 패브릭과 분산 캐시 설계를 연결하는 메시 상호 연결 아키텍처인 SCF(Scalable Coherency Fabric)를 사용한다.
SCF는 메모리, CPU 코어 및 I/O를 포함해 Grace CPU 내의 다양한 내부 하위 시스템을 연결하기 위한 것이다. 최대 117MB의 L3 캐시를 지원하고, 최대 72개 이상의 코어까지 확장 가능한 2,335.6GB/s의 이중 섹션 대역폭을 제공할 수 있다.
SCF는 또 시스템 리소스 분할을 위한 Arm 표준을 제공하는 등 여러 가지 유용한 기능을 제공한다. 이 표준을 통해 Grace CPU는 메모리를 요청하는 각 엔터티에 파티션 ID를 할당할 수 있다. SCF 캐시 리소스는 서로 다른 ID 간에 분할될 수 있다. 특히 SCF는 캐시 용량과 메모리 대역폭을 분할할 수 있으며 성능 모니터 그룹은 리소스 사용량을 모니터링한다.
Grace CPU는 2개의 프로세서를 NVLink-C2C로 결합한 총 144개의 Arm Neoverse 코어로 구성된다. NVLink-C2C 비트당 1.3피코줄을 소비하는 데이터 전송 덕분에 기존 PCIe Gen 5 표준의 5배 에너지 효율성으로 900Gb/s의 속도로 프로세서와 그래픽 카드를 연결한다.
Grace CPU는 최대 효율성을 위해 LPDDR5X 메모리를 사용한다. 이 칩은 메모리에서 초당 테라바이트의 대역폭을 가능하게 하는 동시에 전체 전력 소비를 500와트로 유지한다.
테슬라, 바이렌, 언테더 AI 등도 각자 독자적인 특성을 갖춴 칩을 선보였다.

테슬라는 자체 설계한 칩을 사용한 '도조' AI 슈퍼컴퓨터를 공개했다. 도조는 기존 슈퍼컴퓨터와 달리 특정 머신러닝 알고리즘을 대규모로 실행할 목적으로 컴퓨팅, 네트워킹 및 I/O(입/출력) 실리콘에서 ISA(명령 세트 아키텍처), 전력 공급, 포장 및 냉각까지 포괄하는 맞춤형 아키텍처로 구축한 것이 특징이다.
테슬라는 먼저 15kW 수냉식 패키지에서 FP32(32비트 부동소수점) 성능에서 556 TFLOPS를 처리할 수 있는 반 입방 피트의 독립형 컴퓨팅 클러스터인 도조 훈련 타일(training tile)을 개발했다. 각 타일에는 11GB SRAM을 장착하고, 맞춤형 전송 프로토콜을 사용했다.
훈련 타일의 핵심은 TSMC의 7nm 공정을 기반으로 하는 500억개의 트랜지스터 다이(die)인 테슬라의 D1이다. 각 D1이 400W의 TDP(Thermal Design Power)에서 22 TFLOPS의 FP32 성능을 낼 수 있다.

중국의 스타트업 바이렌(Biren)은 범용 GPU(GPGPU) 'BR100'으로 고성능 GPU 시장에 출사표를 던졌다. 'BR100'은 1074㎟ 면적에 770개 트랜지스터를 집적한 것과 같은 성능을 지닌 제품이다. FP32(32비트 부동소수점) 기준 256 테라플롭스(TFLOPS) 성능을 자랑한다. 세계에서 가장 빠른 GPU 가운데 하나다. 대만 TSMC의 7나노(nm) 공정에서 제조한다.

캐나다 스타트업 언테더(Untether) AI는 FP8(8비트 부동 소수점) 연산에서 2페타플롭(초당 2억개의 연산)으로 최고의 AI 추론 성능을 기록한 RISC-V 아키텍처 기반 '보케리아(Boqueria)' 칩을 발표했다. 기존 CPU의 추가 AI 가속기 역할을 하도록 설계한 제품이다.
AI타임스 박찬 위원 cpark@aitimes.com
[관련기사]인텔 가우디2 프로세서, 엔비디아 A100 성능 뛰어넘어
[관련기사]인텔, 차세대 인텔 4 공정 기술 공개
