KAIST는 전산학부 이재길 교수 연구팀이 인공지능(AI) 딥러닝 훈련 데이터 구축 비용을 최소화할 수 있는 새로운 데이터 동시 정제 및 선택 기술을 개발했다고 12일 밝혔다.
AI 딥러닝 기술로 서비스를 구축하는 과정에서 가장 높은 비용이 소요되는 분야는 라벨링이다. 이 과정은 확보한 데이터에 정답지 혹은 이름을 붙이는 작업이라고 할 수 있다.
문제는 라벨링 작업이 수작업으로 이뤄진다는 점이다. 라벨링에 드는 노동력과 시간 소요에 따른 비용이 클 수밖에 없고, 이를 최소화하는 것이 AI 딥러닝 기술 확산의 주요 과제 중 하나다.
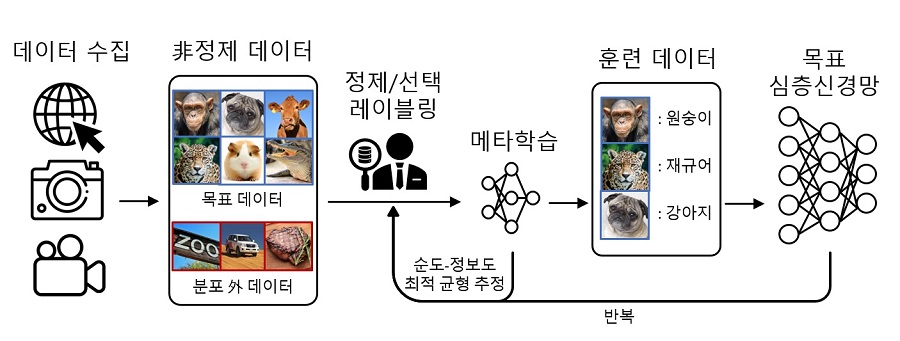
딥러닝 훈련 데이터 구축 과정은 수집, 정제, 선택 및 라벨링 단계로 이뤄진다. 이 교수 연구팀은 이중 정제 단계와 중요 데이터 선택을 동시에 진행해 비용을 줄이는 방법을 개발했다. 최적 균형을 찾아내기 위해 추가 신경망 모델을 도입한 것.
이 방법은 기존 최신 방법 대비 최대 20% 향상된 최종 예측 정확도를 보였고, 모든 범위의 분포 외 데이터 비율에서 일관적으로 최고 성능을 나타냈다.
연구팀은 "이 방법이 목표 심층 신경망의 성능 향상을 위해 추가적인 상위 레벨의 신경망을 사용했다는 점에서 메타학습의 일종으로 보고 `메타 질의 네트워크'라고 이름 붙였다"고 설명했다.
또 메타 질의 네트워크의 최적 균형 분석을 통해, 분포 외 데이터의 비율이 낮고 현재 심층신경망의 성능이 높을수록 정보도에 높은 가중치를 둬야한다는 사실도 추가로 밝혀냈다고 덧붙였다.
이번 연구는 최고권위 국제학술대회 `신경정보처리시스템학회 2022'에서 올 12월 발표될 예정이다.
제1 저자인 박동민 박사과정은 "실생활의 기계 학습 문제에 폭넓게 적용할 수 있어 심층 학습의 훈련 데이터 준비 비용 절감에 기여할 것ˮ이라고 밝혔다. 연구팀을 지도한 이재길 교수는 "이 기술이 텐서플로우나 파이토치와 같은 기존의 심층 학습 라이브러리에 추가되면 기계 학습 및 심층 학습 학계에 큰 파급 효과를 낼 수 있을 것ˮ이라고 말했다.
한편 이번 연구는 과학기술정보통신부 재원으로 정보통신기획평가원의 지원을 받아 SW컴퓨팅산업원천기술개발사업 과제로 개발한 것으로, 데이터사이언스대학원 박사과정 박동민이 제1 저자, 신유주와 이영준이 제2, 제4 저자로 참가했다.
이성관 기자 busylife12@aitimes.com
[관련 기사] 카이스트 정유성 연구팀, AI로 화학반응 결과물 예측 정확도 높여
[관련 기사] KAIST, 네트워크 패킷 적용 SSD 시스템 개발
[관련 기사] KAIST·NYU 공동캠퍼스 구축...AI 등 6개 분야 공동연구
