
메타가 사람처럼 추론할 수 있는 새로운 이미지 생성 인공지능(AI) 모델을 공개했다.
이 모델은 사람이 기존에 학습한 배경지식을 통해 새로운 환경을 이해하듯 기존 배경 지식을 활용해 주어진 이미지를 분석, 이미지 전체에 어떤 것들이 담겨 있는지 사람처럼 이해하는 것이 특징이다.
이를 통해 기존 이미지 생성 AI에서 자주 보였던 손가락 수가 적거나 많은 이미지를 생성하는 오류를 더이상 범하지 않는다.
메타는 13일(현지시간) 블로그를 통해 이미지의 배경 지식을 추론할 수 있는 ‘I-제파(I-JEPA)’ 모델을 오픈소스로 공개했다.
I-제파는 '인간과 유사한(human-like)' 방식으로 미완성 이미지를 더 정확하게 분석하고 완성할 수 있도록 설계된 AI 모델이다.
이 접근방식은 얀 르쿤 메타 수석 AI 과학자가 고안한 새로운 AI 추론 방식을 기반으로 만들어졌다. AI 시스템이 동물과 인간처럼 학습하고 추론할 수 있도록 하겠다는 것이 특징이다.
기존 이미지 생성 AI 모델은 주어진 이미지의 주변 픽셀을 분석해 새로운 이미지를 만들어낸다. 모델에 대한 입력의 일부를 제거하거나 왜곡하여 학습한다.
예를 들어 사진의 일부를 지우거나 텍스트 구절에서 일부 단어를 숨긴다. 그런 다음 손상되거나 누락된 픽셀이나 단어를 예측하려고 한다. 그러나 세상이 본질적으로 예측 불가능함에도 불구하고 모델이 누락된 정보를 모두 채우려고 한다는 것이 단점이다.
결과적으로 기존 생성 모델들은 높은 수준의 예측 가능한 개념을 캡처하는 대신 관련 없는 세부 사항에 너무 집중하기 때문에 사람이 절대 하지 않을 실수를 하기 쉽다. 예를 들어 생성 모델이 사람의 손을 정확하게 생성하는 것은 매우 어렵다.
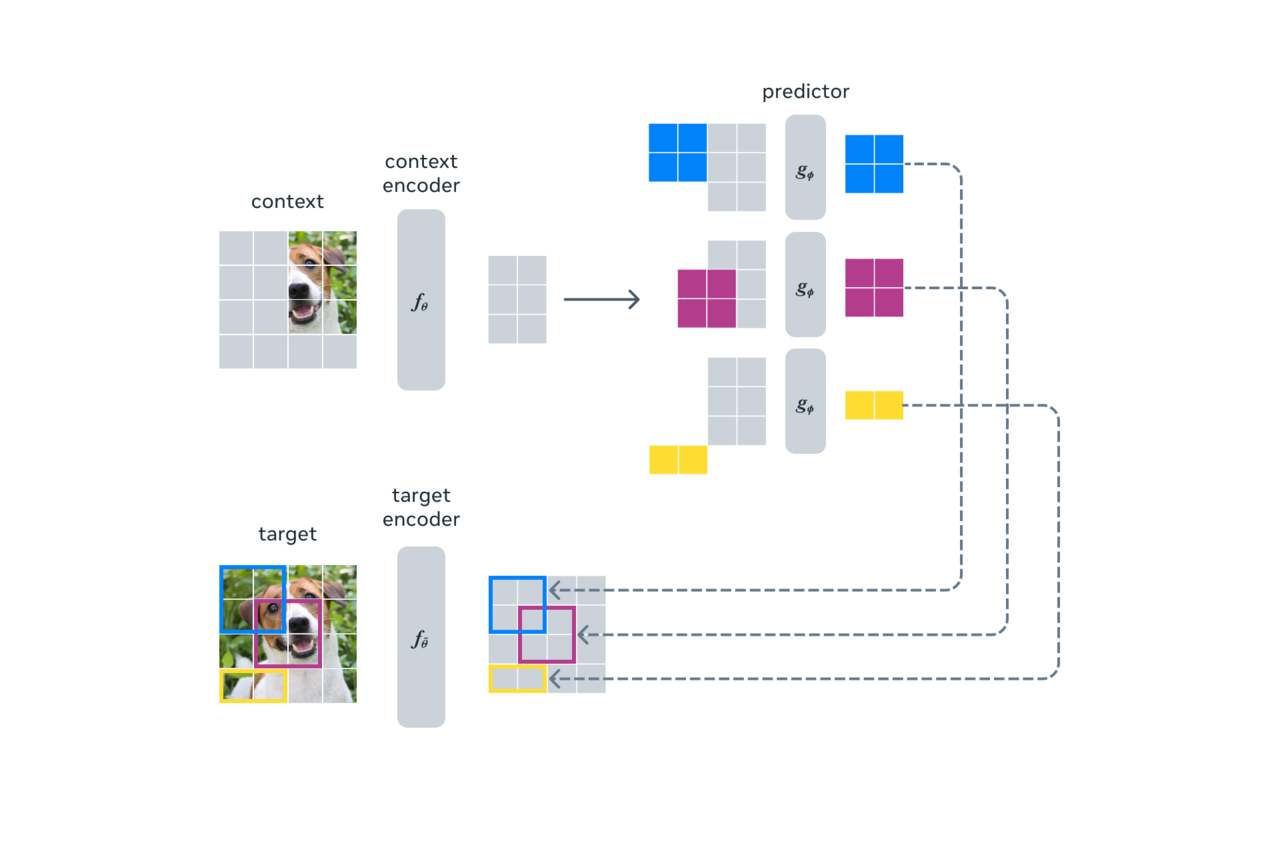
I-제파는 이와 전혀 다른 방식을 사용한다. 이 모델은 픽셀 자체를 비교하는 것이 아니라 이미지의 추상적 표현을 비교하는 방식으로 학습해 동일한 이미지내의 다른 부분의 표현으로부터 누락된 이미지 또는 텍스트 조각의 표현을 예측하는 것을 목표로 한다.
I-제파의 기본 아이디어는 사람들이 일반적으로 이해하는 것과 유사한 추상적 표현으로 누락된 정보를 예측하는 것이다.
픽셀이나 토큰 단위로 예측하는 기존 생성 모델과 달리 이미지를 큰 블록 단위로 나누고 블록 간의 의미론적(semantic) 특징을 학습함으로써 동일한 이미지에서 발생하는 다양한 블록의 표현을 예측한다.
예를 들어 새의 다리 부분이 누락된 사진을 보고 모델은 새를 인식하고 새의 다리를 채워야 한다는 것을 의미론적으로 인식한다.

I-제파는 여러 컴퓨터 비전 작업에서 강력한 성능을 제공하며, 다른 컴퓨터 비전 모델보다 훨씬 더 계산 효율적이다. 또한 I-제파로 학습한 표현은 미세조정 없이도 다양한 애플리케이션에 사용할 수 있다.
예를 들어, 16개의 A100 GPU를 사용하여 6억3200만 매개변수의 시각적 트랜스포머(visual transformer) 모델을 72시간 이내에 훈련한 결과, 클래스당 12개의 라벨링된 예제만으로 이미지넷(ImageNet)에서 로우샷 분류를 위한 최첨단 성능을 달성했다. 다른 방법은 일반적으로 같은 양의 데이터로 학습할 때 2~10배 더 많은 GPU 시간이 소요되고 오류율도 훨씬 높다.
한편, I-제파에 대한 논문 '조인트 임베딩 예측 아키텍처를 사용한 이미지의 자기 지도 학습'은 오는 18일부터 22일까지 캐나다 밴쿠버에서 열리는 '컴퓨터비전과 패턴인식 학술대회(CVPR 2023)'에서 발표할 예정이다. 학습 코드와 모델 체크포인트는 현재 깃허브를 통해 오픈 소싱하고 있다.
박찬 기자 cpark@aitimes.com
