
'챗GPT'나 '제미나이' '그록'과 같은 챗봇과 실시간으로 대화할 수 있게 만드는 새로운 인공지능(AI) 추론 칩이 화제다. 비싸고 구하기 어려운 엔비디아의 GPU보다 빠른 응답 속도를 제공한다는 평가다.
뉴아틀라스는 20일(현지시간) 스타트업 그로크(Groq)가 대형언어모델(LLM)과 같은 컴퓨팅 집약적인 애플리케이션의 처리 속도를 높이기 위해 최적화한 AI 칩 ‘언어 처리 장치(LPU)’를 출시했다고 보도했다.
그로크는 구글의 기계 학습용 칩 엔지니어였던 조나단 로스를 비롯한 구글 엔지니어 출신들이 2016년 창업한 반도체 설계 회사다.
이에 따르면 LPU는 5120개의 벡터 ALU(산술 논리 장치) 외에 320 x 320 행렬 곱셈을 통해 INT8에서 750TOPS(1초당 1조번의 AI 연산), FP16에서 188TFLOPS를 달성하는 TSP(Tensor-Streaming Processor) 아키텍처를 기반으로 하는 단일 코어 장치이며, 초당 80TB의 대역폭을 갖춘 230MB의 로컬 SRAM를 제공한다.
특히 LPU는 챗GPT, 제미나이, 그록, 라마와 같은 LLM의 실행 속도를 높인 추론에 특화된 칩으로, 사용자의 질문에 대해 순식간에 수백단어의 사실적인 답변을 생성한다.
지난주 발표된 벤치마크 테스트에서 그로크는 다른 8개 클라우드 기반 추론 제공업체의 성능을 앞질렀다. 테스트에서 그로크는 메타의 700억 매개변수 LLM ‘라마 2’에 대해 초당 241개의 토큰을 생성하는 반면, MS 애저 클라우드는 초당 19개의 토큰을 생성했다. 이는 챗GPT가 그로크의 LPU 칩에서 실행될 경우 13배 이상 빠르게 실행될 수 있음을 의미한다.
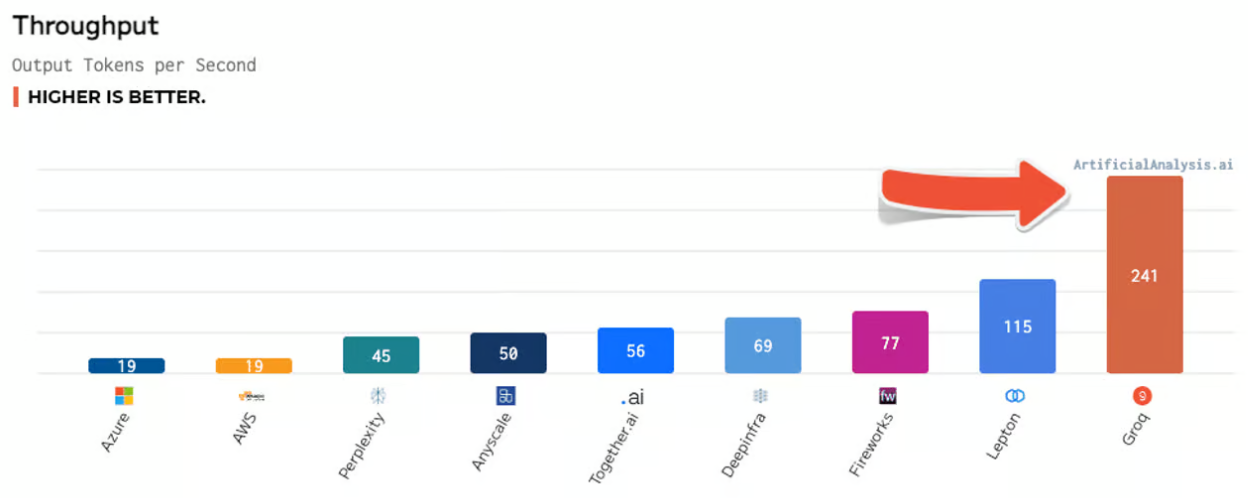
또 100개의 토큰을 생성하는데 그로크는 불과 0.8초가 걸린 반면, MS는 10.1초가 걸렸다. 이는 그로크가 AI 챗봇과 실시간으로 대화할 수 있을 만큼 빠른 응답 시간을 제공한다는 의미다.
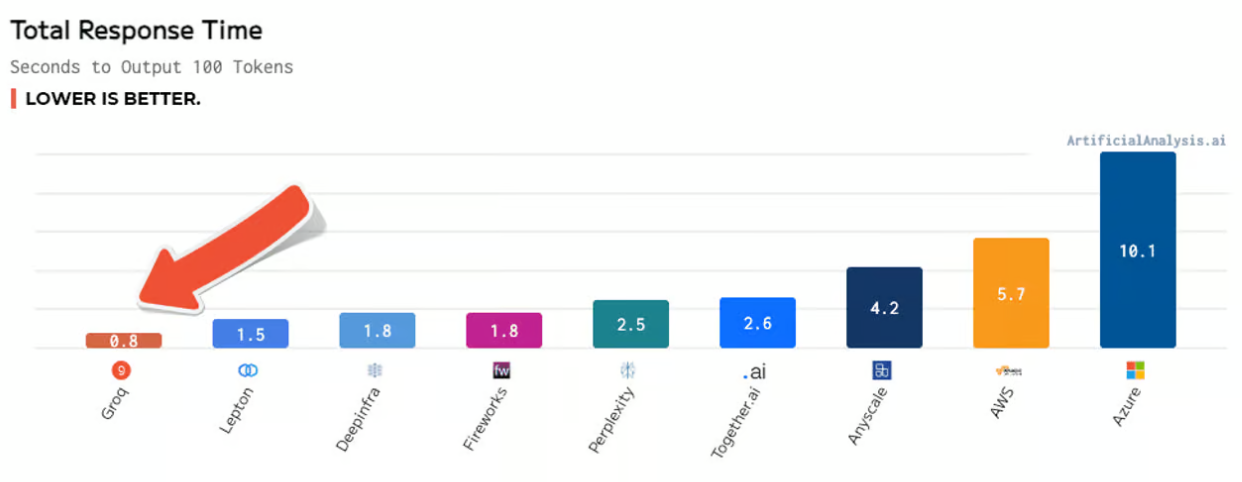
이외에도 그로크 LPU 추론 엔진은 시간 경과에 따른 처리량, 처리량 차이, 대기 시간 대 처리량 등의 항목에서도 가장 높은 점수를 얻었다.
조나단 로스 그로크 CEO는 "속도는 개발자의 아이디어를 비즈니스 솔루션과 삶을 변화시키는 애플리케이션으로 바꾸는 것이기 때문에 추론은 해당 목표를 달성하는 데 매우 중요하다”라고 말했다.
현재 그로크챗 인터페이스를 통해 LPU 추론 엔진을 직접 사용해 볼 수 있으며, 승인된 사용자에 한해서 라마 2, 미스트랄, 팰컨 등을 통해 엔진을 시험해 볼 수 있도록 그로크 API에 대한 조기 액세스도 제공된다.
박찬 기자 cpark@aitimes.com
