알리바바가 사진 한장으로 실감 나게 말하고 노래하는 영상을 생성하는 인공지능(AI) 시스템을 선보였다. 지난해 12월 공개해 극찬받았던 캐릭터 애니메이션 생성 AI의 후속작이다.
벤처비트는 28일(현지시간) 알리바바 지능형 컴퓨팅 연구소가 'EMO(Emote Portrait Alive)'라는 새 AI 프레임워크를 공개했다고 보도했다.
온라인 아카이브에 게재된 논문에 따르면 이 모델은 주어진 음성에 맞춰 정확한 입 모양을 생성하는 것은 물론 표정이나 머리 움직임 등까지 생성할 수 있다. 셀피는 물론 연예인 사진이나 만화, 그림 등 모든 사람 이미지를 원하는 언어나 노래에 맞춰 말하는 영상으로 바꿀 수 있다.
이와 관련, 전날에는 피카랩스가 동영상 생성 AI에 음성까지 추가할 수 있는 '립 싱크'라는 도구를 내놓았다. 이는 피카랩이 오픈AI '소라'에 대응해 내놓은 기능이다.
하지만 관련 커뮤니티에서는 EMO와 립 싱크를 비교하며 어느 쪽이 더 정교한지 비교하는 영상이 퍼져나가고 있다. EMO의 손을 들어주는 경우가 더 많을 정도로 반응이 뜨겁다.
또 연구진이 공개한 영상 중 소라가 생성한 비디오에 등장한 '도쿄 거리를 걷는 여성'과 똑같은 샘플이 포함된 것도 눈길을 끈다. 선글라스와 큰 귀걸이, 빨간 셔츠, 코트 등이 모두 일치한다.
앞서 알리바바는 지난해 12월 역시 사진 한장으로 풀모션 동영상을 생성하는 ‘애니메이트 애니원(Animate Anyone)’이라는 모델을 선보여 호평받았다. 이 모델은 기존 영상에서 인간의 몸짓과 움직임을 추출, 확산 모델(Diffusion Model)을 활용해 사진을 영상으로 만드는 방식으로, 기존의 사진-영상 변환 기술을 끌어올렸다는 평가를 받았다.
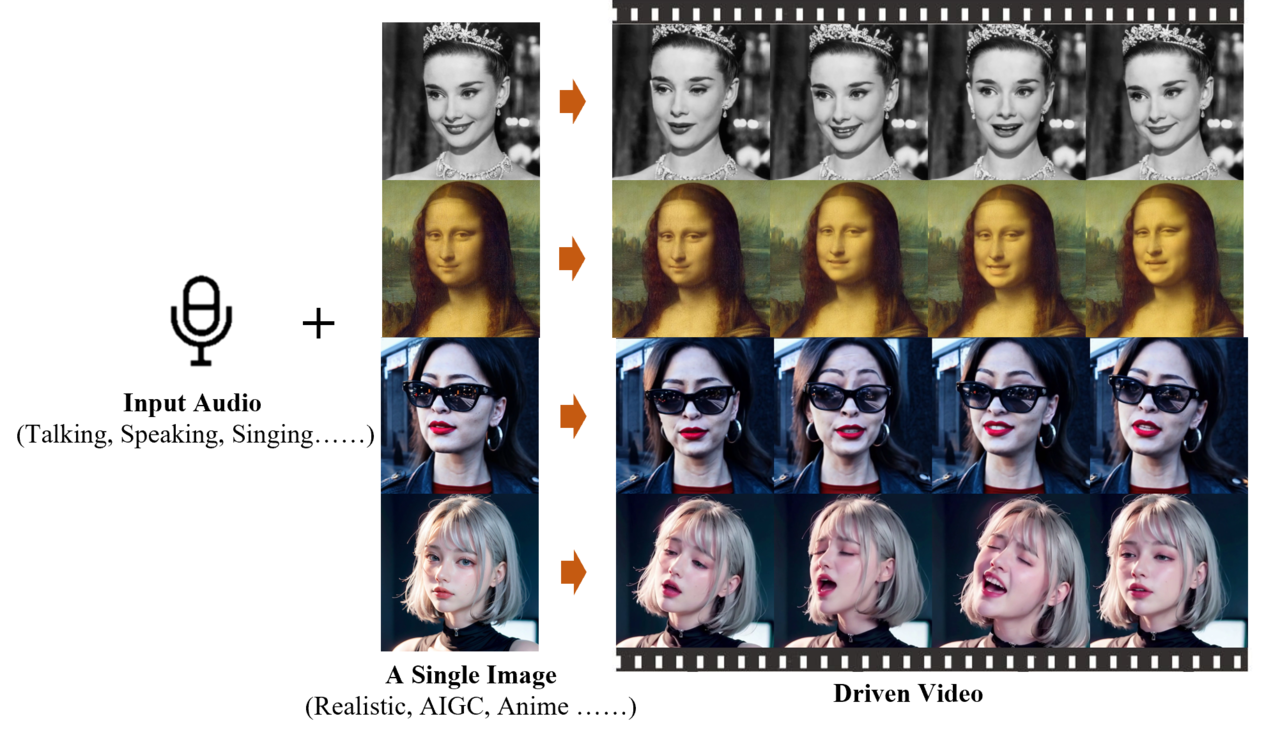
EMO도 확산 모델을 사용했다. 또 영화나 TV 프로그램, 공연 등 250시간이 넘는 대화형 비디오 데이터셋으로 학습했다.
특히 3D 얼굴 모델 등을 사용해 얼굴 움직임을 대략 표현하는 이전 방법과 달리, EMO는 오디오 파형을 비디오 프레임으로 직접 변환해 미묘한 동작과 특징을 포착할 수 있다고 설명했다.
연구진은 실험을 통해 EMO가 기존의 최첨단 방법보다 훨씬 뛰어난 성능을 발휘했다고 전했다. 또 사용자 평가를 통해 다른 모델에서 생성된 비디오보다 더 자연스러운 입 모양을 연출했다고 밝혔다.
대화뿐 아니라 노래를 부르는 모습이 강점이라고 소개했다. 노래를 부를 때는 입 모양뿐 아니라 표정과 머리의 움직임 등이 가장 잘 드러난다는 설명이다. 특히 입력한 오디오의 길이에 맞춰 비디오 생성을 지원한다고 밝혔다.
연구진은 이런 특징으로 인해 EMO가 “다양한 스타일로 제작할 수 있어 표현력과 사실성 측면에서 기존의 최첨단 방법론을 훨씬 능가한다”라고 강조했다.
이 모델은 깃허브를 통해 공개됐다.
임대준 기자 ydj@aitimes.com
- 알리바바, 사진 한장으로 풀모션 영상 생성하는 AI 공개
- '소라' 공개 2주 만에 경쟁사 반격...피카랩, 영상에 음성 기능 추가
- 사진 한장으로 원본에 충실한 딥페이크 생성..."로라보다 뛰어난 성능"
- 표정을 완벽 묘사... 이거 ‘끝판왕’ 아니야?
- 피카, 동영상 생성 AI에 음성 이어 사운드 효과 추가
- 구글, 얼굴 사진 움직이는 AI '브이로거' 공개
- 구글, 업무용 동영상 제작 AI 앱 ‘비드’ 공개..."완벽한 편집 가능"
- MS, 사진 한장으로 말하고 노래하는 영상 만드는 ‘바사-1’ 공개
- 인간 동작 생성·편집하는 AI 모델 등장…"애니메이션·게임 제작 혁신 예고"
- 알리바바, 이미지-동영상 모델 출시..."사진·음성으로 영화급 아바타 영상 제작"
