
국내 연구진이 차세대 인터페이스 기술인 'CXL(Compute Express Link)'을 활성화한 고용량·고성능 인공지능(AI) 가속기를 개발했다.
한국과학기술원(KAIST, 총장 이광형)는 정명수 전기및전자공학부 교수 연구팀이 CXL를 활성화한 고용량 GPU 장치의 메모리 읽기·쓰기 성능 최적화 기술을 개발했다고 8일 밝혔다.
기존 GPU 병렬 연결 방식은 학습 비용이 크다는 문제가 있었다. 이에 차세대 연결기술인 CXL을 활용, 대용량 메모리를 GPU 장치에 연결하는‘CXL-GPU’구조 기술이 대안으로 떠올랐다.
CXL-GPU는 연결된 장치의 메모리 공간을 GPU 메모리 공간에 통합, 고용량을 지원하는 방식이다.
기존 메모리 용량을 늘리기 위해 고가의 GPU를 추가 구매하던 방식과 달리, CXL-GPU는 GPU에 메모리 자원만 선택적으로 추가할 수 있어 구축 비용을절감할 수 있다. 그러나 대규모 AI 서비스에 필요한 연산속도에 맞추기 위해, 메모리 확장 장치의 메모리 읽기·쓰기 성능을 기존 GPU의 로컬 메모리에 준하는 성능으로 확보할 필요가 있었다.

KAIST 연구진은 CXL-GPU 장치의 메모리 읽기/쓰기 성능이 저하되는 원인을 분석해 이를 개선하는 기술을 개발했다.
메모리 확장 장치가 메모리 쓰기 타이밍을 스스로 결정할 수 있는 기술을 개발, GPU 장치가 메모리 확장 장치에 메모리 쓰기를 요청하면서 동시에 GPU 로컬 메모리에도 쓰기를 수행하도록 설계했다. 즉, 메모리 확장 장치가 내부 작업을 수행 상태에 따라 작업을 하도록 해, GPU는 메모리 쓰기 작업의 완료 여부가 확인될 때까지 기다릴 필요가 없어 쓰기 성능 저하 문제를 해결할 수 있도록 했다.
또 메모리 확장 장치가 사전에 메모리 읽기를 수행할 수 있도록 GPU 장치 측에서 미리 힌트를 주는 기술을 개발했다. 이 기술을 활용하면 메모리 확장 장치가 메모리 읽기를 더 빨리 시작하게 돼, GPU 장치가 실제 데이터를 필요로 할 때는 임시저장 공간(캐시)에서 데이터를 읽어 더욱 빠른 메모리 읽기 성능을 달성할 수 있다는 설명이다.
이번 연구는 반도체 팹리스 스타트업인 파네시아(Panmnesia)의 초고속 CXL 컨트롤러와 CXL-GPU 프로토타입을 활용해 진행됐다.
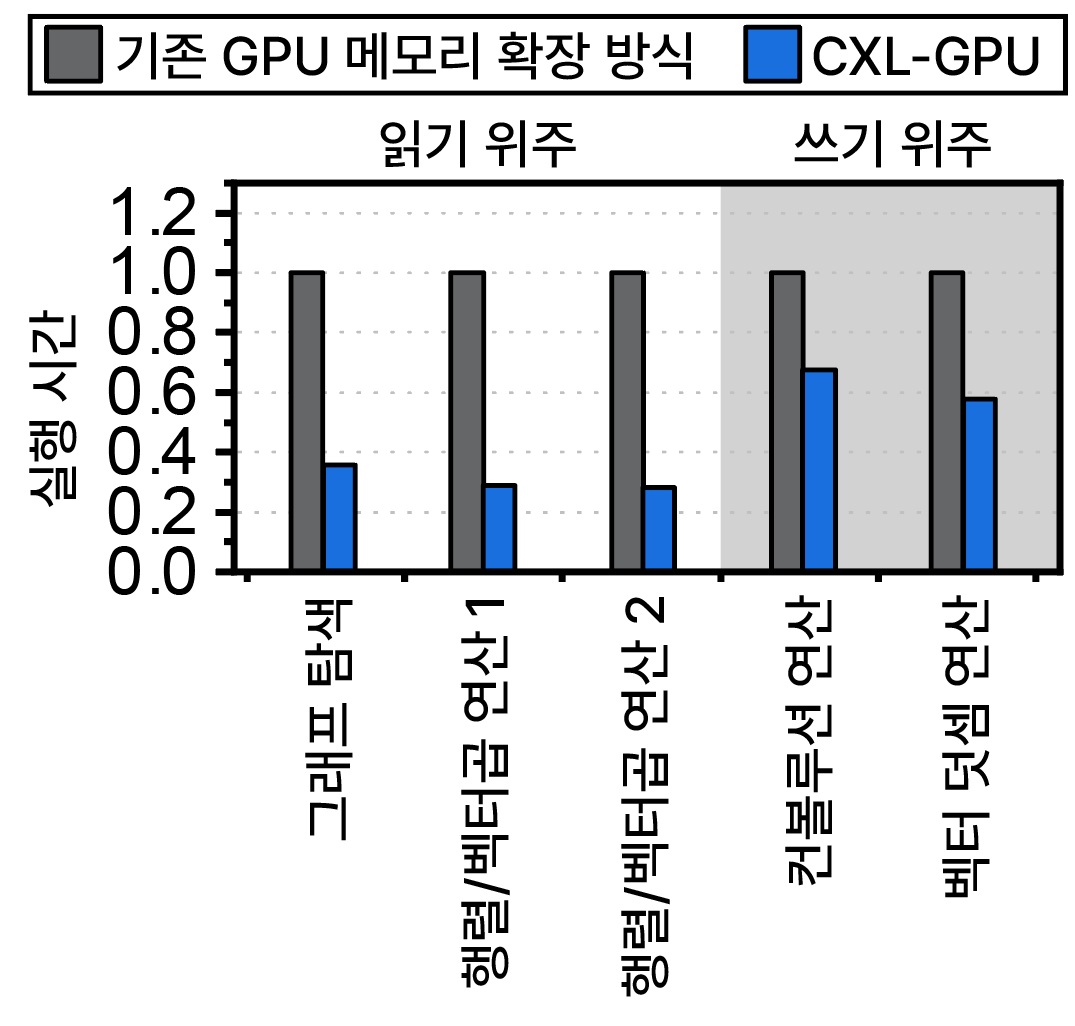
연구팀은 파네시아의 CXL-GPU 프로토타입을 활용한 기술 실효성 검증을 통해 기존 GPU 메모리 확장 기술보다 2.36배 빠르게 AI 서비스를 실행할 수 있음을 확인했다. 해당 연구는 7월 산타클라라 유즈닉스(USENIX) 연합 학회와 핫스토리지의 연구 발표장에서 결과를 선보인다.

정명수 전기및전자공학부 교수는 “CXL-GPU의 시장 개화 시기를 가속해 대규모 AI 서비스를 운영하는 빅테크 기업의 메모리 확장 비용을 획기적으로 낮추는 데 기여할 수 있을 것”이라 말했다.
박수빈 기자 sbin08@aitimes.com
