
구글 딥마인드가 ‘전문가 믹스(MoE, Mixture of Experts)’를 구성하는 소수의 전문가 모델을 수백만개로 확장할 수 있는 새로운 아키텍처를 공개했다. 이를 통해 대형언어모델(LLM) 운영 비용과 효율성을 향상할 수 있다는 설명이다.
벤처비트는 12일(현지시간) 구글 딥마인드 연구진이 MoE를 수백만 전문가로 확장, LLM 계산 비용을 늘리지 않으면서 추론 성능을 향상할 새로운 아키텍처 '피어(PEER, Parameter Efficient Expert Retrieval)'에 관한 논문을 아카이브에 게재했다고 전했다.
LLM에서 사용되는 모든 트랜스포머는 어텐션 계층과 피드포워드(FFW) 계층으로 구성된다. 어텐션 계층은 트랜스포머 블록에 공급된 토큰 시퀀스 간의 관계를 계산하고, FFW 네트워크는 모델의 지식을 저장하는 역할을 한다. 트랜스포머 아키텍처에서 FFW 계층은 모델 매개변수의 3분의 2를 차지하며, 추론시 계산량이 FFW의 매개변수 크기에 비례할 정도로 병목이 발생하는 지점이다.
MoE는 이 문제를 해결하기 위해 전문가 모델로 FFW를 대체한다. MoE는 LLM을 생물, 물리, 수학 등 각 분야를 담당하는 작은 전문가 모델로 쪼개고, 라우터가 질문에 따라 전문 모델을 연결하거나 몇 종류를 섞는 방식이다. 이 경우 전체 큰 모델을 돌리는 것보다 비용과 시간이 훨씬 적게 들어간다.
MoE는 LLM 크기와 훈련 데이터가 클수록 전문가 수를 늘리면 성능이 향상될 수 있다. 그러나 MoE는 특정 수의 전문가를 위해 설계된 고정 라우터가 있기 때문에, 새로 전문가를 추가하려면 미세조정이 필요하다.
반면 피어 아키텍처는 MoE를 수백만개의 전문가 모델로 쉽게 확장할 수 있다. 피어는 고정 라우터를 학습된 인덱스를 대체, 방대한 전문가 풀을 효율적으로 라우팅할 수 있다.
쿼리가 주어지면 피어는 먼저 빠른 초기 계산을 사용해 잠재적 후보의 전문가 목록을 만든 다음, 그중 최고 전문가 모델을 선택하고 활성화한다. 이 메커니즘을 통해 MoE는 속도를 늦추지 않고도 매우 많은 수의 전문가를 처리할 수 있다.
또 MoE보다 작은 전문가를 사용하는 것이 특징이다. 이를 통해 모델은 전문가 간에 숨겨진 뉴런을 공유, 지식 전달과 매개변수 효율성을 개선할 수 있다는 것이 핵심이다.
전문가의 작은 크기를 보완하기 위해 피어는 트랜스포머 모델에서 사용되는 '다중 헤드 어텐션 메커니즘'과 유사한 '다중 헤드 검색 접근 방식'을 사용한다.
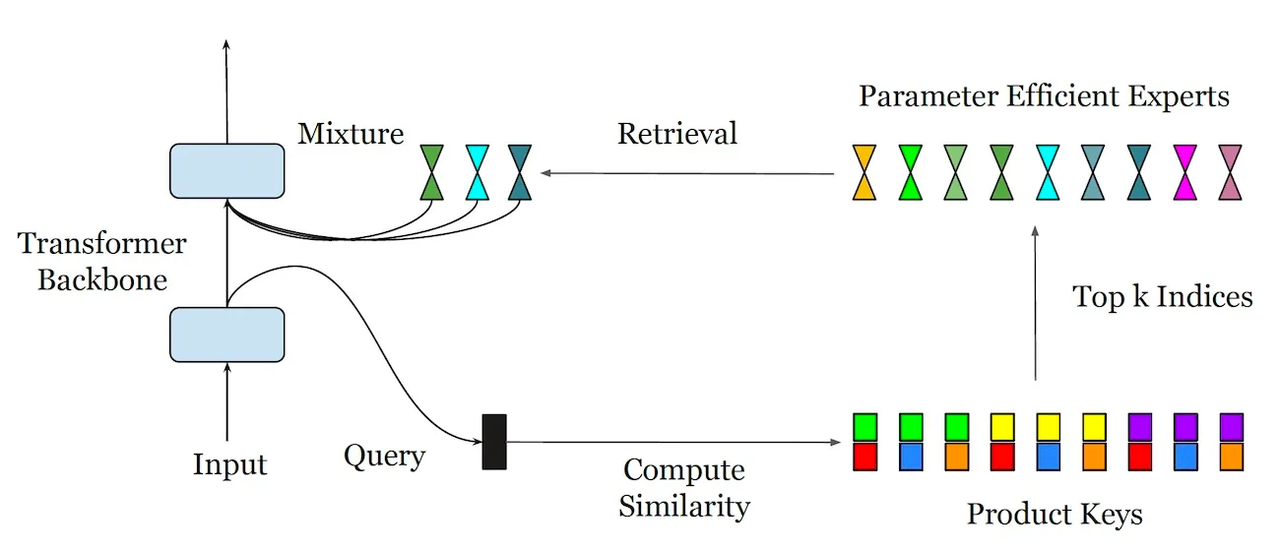
피어는 기존 트랜스포머 모델에 추가하거나 FFW 계층을 대체하는 데 사용할 수 있다.
필요한 매개변수만 미세조정하는 로라(LoRA)와 같은 매개변수 효율적 미세 조정(PEFT) 기술을 통해 런타임에 PEFT 어댑터를 선택하도록 조정할 수 있고, 이를 통해 LLM에 새로운 지식과 기능을 동적으로 추가할 수 있다.
연구진은 "현재 구글 딥마인드의 제미나이 1.5 프로 모델이 피어 아키텍처를 도입, 더 빠르고 효율적으로 작동한다"라고 밝혔다.
기존 FFW 계층과 MoE 아키텍처, 피어 아키텍처를 갖춘 트랜스포머 모델 등을 비교한 결과, 피어 모델은 더 나은 성능을 달성하며 동일한 계산 비용으로 더 낮은 복잡도 점수에 기록했다.
또 피어 모델에서 전문가의 수를 늘리면 복잡성이 더욱 감소하는 것을 발견했다고 덧붙였다.
연구진은 "결론적으로 이런 접근 방식을 통해 매우 큰 LLM을 훈련하고 실행하는 데 드는 비용과 복잡성을 더욱 줄일 수 있다"라고 강조했다.
박찬 기자 cpark@aitimes.com
