
추론 중 컴퓨팅 리소스를 더 많이 할당하면, 대형언어모델(LLM)의 성능을 개선할 수 있다는 연구 결과가 나왔다.
벤처비트는 26일(현지시간) 구글 딥마인드와 UC 버클리 연구진이 컴퓨팅 리소스를 전략적으로 할당해 LLM의 성능을 개선하는 방법을 아카이브에 게재했다고 보도했다.
이는 추론 시간에 컴퓨팅 자원의 사용을 최적화, 큰 모델이나 광범위한 사전 훈련 없이도 LLM이 상당한 성능 향상을 달성할 수 있다는 내용이다.
일반적으로 LLM 성능을 개선하기 위해서는 모델 매개변수를 키우고 사전 훈련에 필요한 계산 자원을 확장하는 것이다. 그러나, 이 접근 방식은 비용이 많이 들고 많은 자원을 요구하기 때문에, 자원이 제한된 장치 등 다양한 환경에 배포하기 어렵다.
이번에 제시된 방법은 추론 중 더 많은 계산 자원을 사용해 어려운 프롬프트에 대한 LLM 응답의 정확성을 향상하는 방법이다. 인간이 어려운 문제에 직면했을 때 더 오랜 시간 생각해 나은 결정을 내리는 것처럼, 어려운 입력 쿼리에 대해 LLM이 추론 시간을 추가해 응답 정확성을 향상할 수 있다는 설명이다.
연구진은 이 접근 방식이 작은 모델도 크고 계산 비용이 많이 드는 모델과 유사한 성능을 달성할 수 있게 해준다고 전했다.
추론 시간에 계산 자원을 확장하는 대표적인 접근 방식으로는 ▲모델이 N개의 출력을 병렬로 생성하고 가장 정확한 응답을 최종 답변으로 선택하는 '최고 N 기준(best-of-N baseline) 병렬 샘플링' 방식이나 ▲여러 응답을 병렬로 생성하는 대신, 모델이 응답을 여러 단계에 걸쳐 수정하고 교정하는 '순차 샘플링' 방식이 있다.
또 가장 잘 생성된 응답을 선택하는 검증 메커니즘을 변경하거나, 병렬 샘플링과 순차 샘플링을 결합하고 다양한 검증 전략을 적용할 수도 있다.
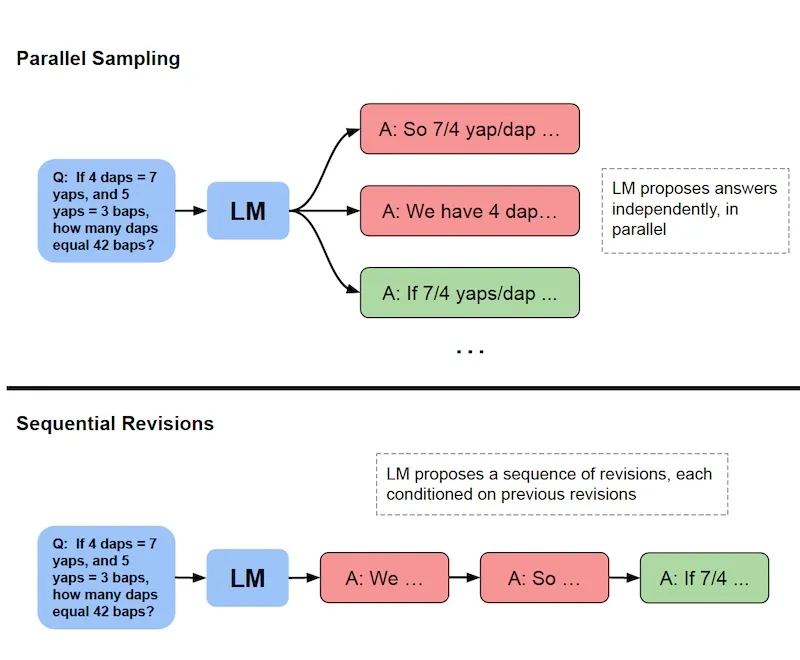
연구진은 LLM 성능을 향상하기 위해 추론 시간 계산을 확장하는 두가지 접근 방식을 결합했다. 첫번째 방식은 미세조정을 통해 복잡한 추론에 대해 LLM이 반복적으로 답변을 수정한다. 두번째는 프로세스 기반 보상 모델을 훈련, 가장 잘 생성된 응답을 선택하는 검증 메커니즘을 최적화하는 것이다.
연구진은 접근 방식을 평가하기 위해 구글의 '팜-2(PaLM-2)' 모델을 사용해 매쓰(MATH) 벤치마크에서 실험을 진행했다.
연구진은 쉬운 문제에서 LLM이 이미 합리적인 응답을 생성할 수 있는 경우에는, 모델이 초기 답변을 반복적으로 수정하는 순차 샘플링이 효과적이라는 것을 발견했다.
반면, 다양한 해결 전략을 탐색해야 하는 어려운 문제에서는 병렬로 여러 응답을 다시 샘플링하거나 프로세스 기반 보상 모델을 이용한 검증 메커니즘을 배포하는 것이 더 낫다는 것을 확인했다.
연구진은 "두가지 접근 방식 모두에서, 특정 추론 시간 계산 확장의 효과는 문제 특성과 사용하는 LLM 유형에 크게 의존한다"라고 밝혔다.
적절하게 추론 시간 계산 자원을 할당하는 것만으로도 성능을 크게 향상할 수 있다고 전했다. 약 25%의 계산 자원만 사용하면서도 최고 N 기준을 초과하는 성능을 기록할 수 있었다.
또 추론 시간 계산이 사전 훈련을 얼마나 대체할 수 있는지 조사하기 위해 ▲작은 모델에 추가적인 추론 시간 계산을 적용한 성능과 ▲14배 더 큰 모델에 더 많은 사전 훈련을 적용한 성능을 비교했다.
그 결과, 쉬운 질문과 중간 난이도의 질문에서는 추가적인 추론 시간 계산을 적용한 더 작은 모델이 큰 사전 훈련 모델과 비슷한 성능을 보였다.
이는 단순히 사전 훈련의 규모를 확장하는 것보다, 일부 문제에서는 더 적은 계산 자원으로 더 작은 모델을 사전 훈련한 뒤 추론 시간 계산을 적용하는 것이 더 효과이라는 설명이다.
그러나 어려운 문제에서는 추가적인 사전 훈련 계산 자원이 효과적인 것으로 나타났다. 이는 추론 시간 계산 확장 접근 방식이 모든 상황에서 사전 훈련을 완벽하게 대체할 수는 없다는 것을 의미한다.
연구진은 “전반적으로 추론 시간 계산을 확장하는 것이 사전 훈련의 확장보다 더 바람직할 수 있다”라며 “이는 사전 훈련에서 소비되는 FLOP 수를 줄이고, 추론에서 소비되는 FLOP 수를 늘리는 방식”이라고 말했다.
박찬 기자 cpark@aitimes.com
