
앨런AI연구소(AI2)가 전문가 혼합(MoE) 방식의 오픈 소스 대형언어모델(LLM) '올모E(OLMoE)’를 출시했다. 모델 가중치, 훈련 데이터, 코드 등에 대한 정보를 투명하게 공개한 최초의 오픈 소스 MoE 기반 모델이다.
벤처비트는 9일(현지시간) 비영리 민간 AI 연구기관인 AI2가 MoE 방식의 고성능 저비용 오픈 소스 LLM인 ▲OLMoE-1B-7B ▲OLMoE-1B-7B-인스트럭트를 출시했다고 보도했다.
MoE는 대형언어모델(LLM)을 작은 전문 모델(Expert)로 쪼개고, 질문에 따라 전문 모델을 연결하거나 몇 종류를 섞는 방식이다.
올모E는 64개의 작은 전문 모델로 세분화해 한번에 8개만 라우팅하고 방식으로, 전체 70억 매개변수 가운데 10억개만 활성화한다. 이를 통해 다른 모델과 비슷한 성능을 보이면서도 추론 비용과 메모리 저장 공간을 절감할 수 있다.
AI2의 오픈 소스 모델인 올모 1.7-7B(OLMo 1.7-7B)를 기반으로 구축됐으며, 4096 토큰 컨텍스트 창을 지원한다. 데이터 큐레이션을 통해 구축한 고품질 데이터셋 DCLM과 AI2의 데이터셋 '돌마(Dolma)'의 혼합 데이터를 사용해 훈련했다.
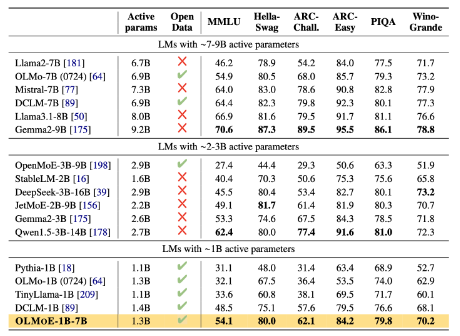
성능 면에서도 올모E는 비슷한 활성 매개변수를 가진 모델을 능가하는 것으로 나타났다. 10억 매개변수를 가진 모델과의 비교에서 '파이시아(Pythia)', '타이니라마(TinyLlama)', 기존 올모와 같은 오픈 소스 모델들의 성능을 압도적으로 능가했다.
또 '미스트랄-7B' '라마 3.1-8B' '젬마 2'와 같은 7B 이상의 매개변수를 가진 다른 모델들과 유사한 성능을 보였으며, '라마2-13B-챗'과 '딥시크 MoE-16B'와 같은 더 큰 모델보다도 뛰어난 성능을 보였다.
AI2는 "올모E의 출시는 단순히 도구를 제공하는 것이 아니라, 완전한 오픈 소스 MoE 모델을 구축하기 위한 것"이라고 밝혔다.
MoE 아키텍처를 사용해 많은 모델들이 구축되고 있지만, 대부분의 MoE 모델은 폐쇄형 소스다. 예를 들어, 미스트랄의 '믹스트랄 8x22B', xAI의 '그록'도 MoE 방식을 사용했다. 'GPT-4'도 MoE를 활용했다고 전해진다.
AI2는 “일부 MoE 모델이 모델 가중치를 공개적으로 공개했지만, 훈련 데이터, 코드 또는 레시피에 대한 정보는 제한적이거나 전혀 제공하지 않는다”라고 지적했다.
박찬 기자 cpark@aitimes.com
- 구글 딥마인드, 전문가 모델을 수백만개로 확장하는 MoE 아키텍처 소개
- '진짜' 오픈 소스 LLM '올모' 업데이트..."데이터셋·학습 강화로 성능 올려"
- 미스트랄 AI, '믹스트랄'보다 4배 커진 SMoE 모델 출시
- 하루 만에 또 "세계 최고 오픈 소스 모델" 등장...중국 딥시크, ‘딥시크-V2.5’ 출시
- MS, 'o1' 빼닮은 ‘그린-MoE’ 모델 출시..."코딩·수학 뛰어난 저가형 모델"
- AI2, 오픈 소스 LMM ‘몰모’ 공개..."100배 적은 데이터 학습으로 GPT-4o 능가"
- 텐센트, 오픈 소스 최대 규모 'MoE' 모델 출시
- AI2, 오픈 소스 성능 첨단 모델급으로 올려주는 '사후 훈련' 풀셋 공개
