
애플이 인공지능(AI) 시스템 ‘애플 인텔리전스’의 기반 모델 이름과 훈련 방법 등을 상세하게 공개했다. 이는 지난 6월 발표한 기술 문서의 내용을 구체화한 것이다.
CNBC는 29일(현지시간) 애플이 ‘애플 인텔리전스 파운데이션 언어 모델(AFM)’이라는 제목의 논문을 발표했다고 보도했다.
이에 따르면 애플 인텔리전스의 기반 모델은 ▲모바일 기기 내 AI 처리를 위한 30억 매개변수의 온디바이스 언어 모델 ‘AFM-온디바이스(AFM-on-device)’ ▲’프라이빗 클라우드 컴퓨트(Private Cloud Compute)’ 시스템 기반 애플의 클라우드 인프라에서 실행될 서버 언어 모델 ‘AFM-서버(AFM-server) 등 2가지다. 서버 모델은 구체적인 정보는 공개되지 않았다.
애플은 웹 크롤러인 '애플봇(AppleBot)'이 수집한 공개 데이터뿐만 아니라, 특정 기능을 향상하기 위해 라이선스 데이터를 기반으로 기반 모델을 훈련했다고 밝혔다. 요약과 같은 작업을 향상하기 위해 합성 데이터도 활용했다.
이와 함께 애플이 새로운 AI 모델을 훈련하기 위해 사용한 인프라의 규모도 구체적으로 드러났다.
6월 당시에는 구글의 AI 칩 ‘텐서처리장치(TPU,Tensor Processing Unit)’를 장착한 구글 클라우드에서 훈련했다고만 밝혔는데, 이번에는 구체적인 수치를 추가했다.
온디바이스 AI 모델 학습에는 올해 1월 선보인 TPUv5p 칩 2048개를, 서버 모델에는 지난해 공개된 TPU 4세대 버전인 TPUv4 8192개를 사용했다는 내용이다. 구글의 TPU는 구글 클라우드 플랫폼을 통해서만 액세스를 허용하기 때문에 사용자는 구글 클라우드를 통해 소프트웨어를 구축해야한다.
애플은 모델의 추론 성능 향상을 위해 온디바이스와 프라이빗 클라우드에서 속도와 효율성을 최적화하는 데 집중했다.
이를 위해 기기 내 모델과 서버 모델 모두 '그룹 쿼리 어텐션(grouped-query-attention)'을 사용했다. 입력 및 출력 어휘 임베딩 테이블을 공유해 메모리 요구 사항과 추론 비용을 줄였다. 온디바이스 모델은 4만9000개, 서버 모델은 10만개의 어휘 크기를 사용한다.
또 기반 모델들을 로라(LoRA) 기법을 사용해 특정 작업에 맞게 모델을 미세조정했다. 로라는 전체 가중치 대신 일부 가중치만을 조정해 전체 매개변수 미세조정을 통해 달성한 것과 같은 수준의 정확도를 유지하면서 필요한 메모리와 계산을 획기적으로 줄이는 미세조정 기법이다.
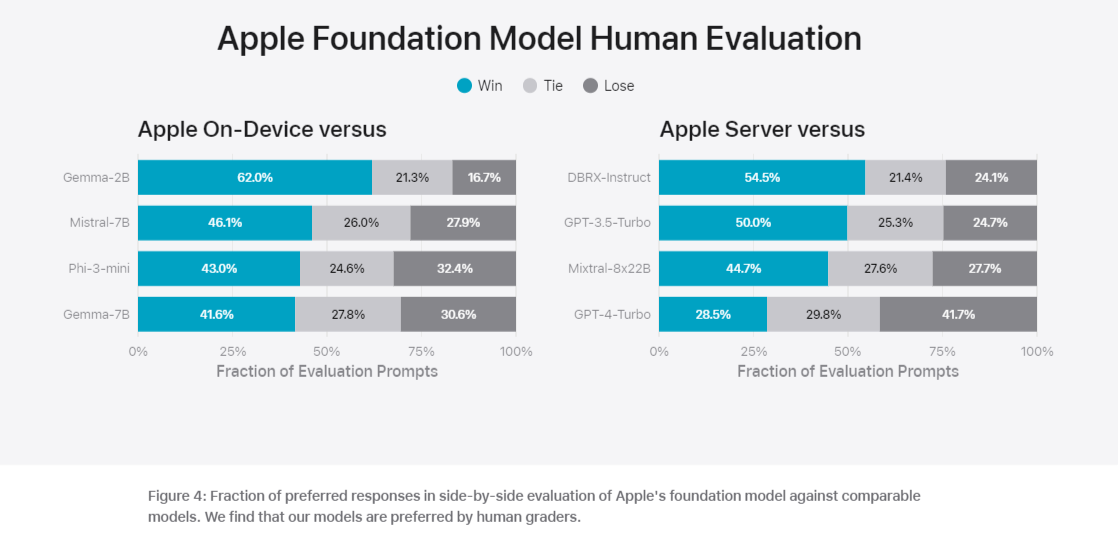
온디바이스 모델과 서버 모델의 성능 평가 결과도 공개했다. 벤치마크에서는 '파이-3' '젬마' '미스트랄' 'DBRX' 등 오픈 소스 모델과 상업용 모델 'GPT-3.5-터보' 'GPT-4-터보' 등을 비교했다.
그 결과, 대부분의 경쟁 모델보다 애플 모델이 인간 평가자들에게 더 선호된다는 것을 확인했다. 온디바이스 모델은 파이-3-미니, 미스트랄-7B, 젬마-7B 등의 더 큰 모델들을 능가했다. 서버 모델은 DBRX-인스트럭트, 믹스트랄l-8x22B, GPT-3.5-터보에 비해 높은 효율성을 보였다.
또 애플의 온디바이스 모델과 서버 모델은 모두 적대적 프롬프트에 대해 강력한 성능을 보였다. 안전을 강조하는 애플답게 다른 회사 모델을 모두 앞섰다.
애플은 새로운 AI 모델을 10월에 출시되는 iOS 18, 아이패드OS 18 및 맥OS 세쿼이아의 후속 버전에 적용할 예정이다.
박찬 기자 cpark@aitimes.com
