
자율 주행이나 로봇과 같은 복잡한 비디오를 포괄적으로 이해, 자동으로 캡션을 생성하는 프레임워크가 등장했다. 이를 통해 비디오 작업을 통한 콘텐츠 이해와 검색, 교육 모델의 활용 등에 도움을 준다는 의도다.
마크테크포스트는 3일(현지시간) 엔비디아와 UC 버클리, MIT, UT 오스틴, 토론토대학교, 스탠포드대학교 등의 연구진이 비디오 캡션을 위한 프레임워크 ‘울프(WOLF, WOrLd summarization Framework)’에 관한 논문을 아카이브에 게재했다고 전했다.
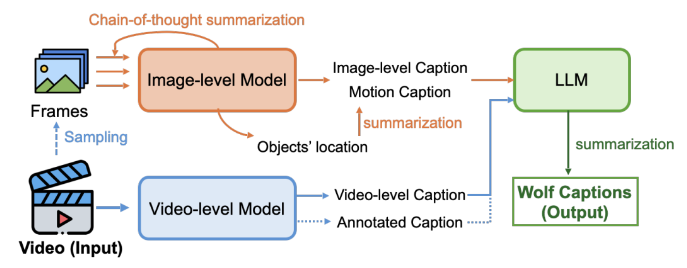
울프는 '전문가 혼합(MoE)' 방식을 채택한 자동 캡션 프레임워크다. 이미지 캡션 생성을 위해 비전언어모델(VLM) ‘코그에이전트(CogAgent)’ 및 ‘GPT-4V’를 사용하고, 비디오 캡션 생성을 위해 대형언어모델(LLM) ‘VILA-1.5’ 및 ‘제미나이 1.5 프로’를 사용한다.
이미지 기반 VLM이 비디오 기반 VLM보다 더 많은 데이터로 사전 훈련했기 때문에, 먼저 이미지 기반 VLM을 사용해 이미지 라벨의 캡션을 생성한다. 여기에 '사고 사슬(CoT)' 기법을 적용했다.
우선 비디오를 순차적인 이미지로 분할하고, 매초 두개의 주요 프레임을 샘플링한다. 이미지 1을 이미지 기반 VLM에 입력해 캡션 1을 얻으며, 모델이 상세한 장면 수준 정보와 객체 위치를 생성하도록 요구한다.
비디오에서 주요 프레임 간의 시간적 상관관계를 고려, 캡션 1과 이미지 2를 모델에 입력해 캡션 2를 생성한다. 이 절차를 반복해 모든 샘플링된 프레임에 대한 캡션을 생성하는 식이다.
마지막으로, 이미지 기반 VLM으로부터 캡션을 얻은 후 GPT-4에서 정확한 시간 정보와 함께 모든 캡션 정보를 요약한다. 이 과정에서 비디오 기반 VLM을 통해 비디오 레벨의 캡션을 생성하고, 최종 비디오 캡션을 생성하기 위해 내용을 크로스 체크한다.
연구진은 캡션 품질을 평가하기 위해 생성 캡션 실제 캡션의 유사성과 품질을 평가하는 LLM 기반 메트릭 '캡스코어(CapScore)'를 도입했다. 또 포괄적인 비교를 위해 자율 주행과 일반 장면, 로보틱스 등 세가지 영역에서 네개의 인간 주석 데이터셋을 구축했다.
그 결과, 울프는 최신 기술인 VILA1.5나 코그에이전트는 물론, 제미나이 1.5 프로와 GPT-4V와 비교해도 우수한 캡션 성능을 기록한 것으로 나타났다.
GPT-4V와 비교했을 때, 울프는 운전 비디오에서 캡스코어의 캡션 품질이 55.6% 뛰어났고, 캡스코어의 캡션 유사성에서 77.4% 개선됐다.
이 과정에서 GPT-4V는 장면 인식은 뛰어나지만, 시간 정보에는 어려움을 겪는다는 점이 발견됐다. 제미나이 1.5 프로는 동작 설명에 대한 세부 정보가 부족했다.
반면, 울프는 교통 신호의 흐름과는 다른 방향으로 움직이는 차량 등의 자세한 동작과 같은 점을 효율적으로 캡처한다.
연구진은 "이 접근 방식은 다양한 관점에서 비디오를 포괄적으로 이해할 수 있게 해주며, 특히 멀티뷰 운전 비디오와 같은 까다로운 시나리오에서 탁월하다"라고 밝혔다.
또 "비디오 캡션 기술에서 경쟁과 혁신을 장려하기 위해 리더보드를 구축했으며, 고품질 캡션이나 지역 정보 및 다중 객체 모션 세부 정보가 포함된 다양한 비디오 유형을 특징으로 하는 포괄적인 라이브러리를 만들 계획"이라고 덧붙였다.
박찬 기자 cpark@aitimes.com
