엣지 장치에 최적화된 세계에서 가장 작은 비전언어모델(VLM)이 출시됐다. 이 모델은 이미지 토큰 수를 대폭 줄여 지연 시간과 계산 비용을 절감한다.
AI 스타트업 넥사 AI는 15일(현지시간) 세계에서 가장 작고 빠른 VLM ‘옴니비전-968M(OmniVision-968M)’을 발표했다.
옴니비전은 9억6800개의 매개변수를 가진 멀티모달 모델로, 텍스트와 시각 입력을 처리하며 엣지 장치에 최적화돼 있다. '라바(LLaVA)' 아키텍처를 개선해 이미지 토큰을 729개에서 81개로 축소해 효율성을 9배 높였고, 이를 통해 지연 시간과 계산 비용을 대폭 절감했다.
또 직접 선호도 최적화(DPO) 훈련을 통해 모델의 정확도를 향상시켰다. DPO는 RLHF(강화 학습 기반 인간 피드백)를 대체하는 방식으로, 선호 데이터를 직접 모델 학습에 활용하는 방법이다.
옴니비전의 아키텍처는 알리바바의 오픈 소스 모델 '큐원2.5-0.5B-인스트럭트'로 텍스트 입력을 처리하며, 'SigLIP-400M' 비전 인코더가 384 해상도와 14×14 패치 크기로 이미지 임베딩을 생성한다.
이후 '다계층 퍼셉트론(MLP)'을 활용한 프로젝션 레이어가 비전 인코더의 임베딩을 언어 모델의 토큰 공간과 일치시키며, 이미지 토큰 수를 9배 축소한다.
토큰 수를 줄인 덕분에 옴니비전은 추론에 필요한 계산 자원을 크게 줄일 수 있었다. 이는 웨어러블과 모바일 장치, IoT 하드웨어 등 제한된 자원을 가진 환경에서 VLM을 구현하려는 개발자들에게 이상적인 솔루션을 제공한다.
또 DPO 훈련 전략을 통해 모델의 환각 문제를 최소화하고 신뢰성을 높였다.

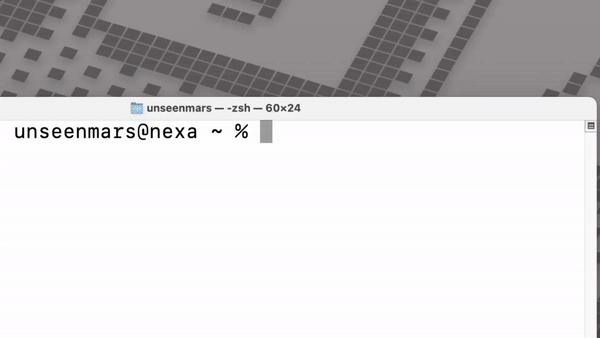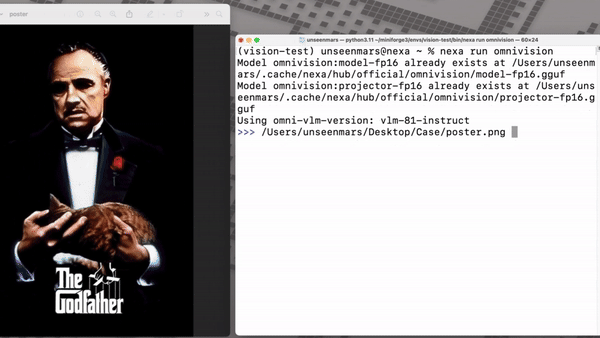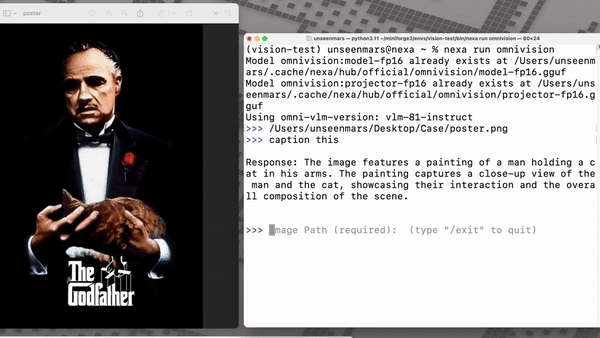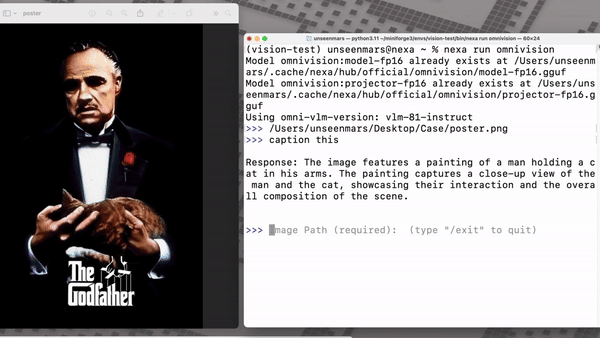
실제 테스트에서 옴니비전은 맥북 프로의 장착된 'M4'에서 1046×1568 이미지 캡션 생성에 2초 미만의 처리 시간을 기록했다. 988MB의 RAM과 948MB의 저장 공간만을 필요로 했다.
벤치마크 결과에서도 옴니비전은 이전 모델에 비해 추론 시간을 35% 단축하면서도 시각적 질문 응답과 이미지 캡셔닝 작업에서 정확도를 유지하거나 개선했다.
또 모든 작업에서 지금까지 세계에서 가장 작은 VLM인 나노라바(nanoLLAVA)보다 우수한 성과를 보였다.
이런 모델은 의료나 스마트 시티, 자동차 등 저전력 고속 상호작용이 필요한 산업에 큰 도움이 될 수 있다.
다만 이 모델은 아직 초기 연구 단계라고 밝혔다. 넥사 AI는 "한계를 해결하고 생산에 바로 적용할 수 있는 솔루션으로 발전할 예정"이라고 설명했다.
현재 옴니비전-968M은 허깅페이스에서 사용할 수 있다.
박찬 기자 cpark@aitimes.com
