
구글 딥마인드가 별도의 검증자 대신, 대형언어모델(LLM)이 텍스트 생성 기능을 활용해 자체적으로 응답을 확인하고 정확도를 개선하는 새로운 접근 방식을 공개했다.
벤처비트는 3일(현지시간) 구글 딥마인드, 토론토대학교, 밀라, UCLA 연구진 등이 LLM의 생성 기능을 활용해 효과적인 검증자를 만드는 새로운 접근 방식 ‘젠RM(GenRM)’에 관한 논문을 아카이브에 게재했다고 보도했다.
LLM 정확도를 개선하기 위한 일반적인 방법은 여러 후보 응답을 생성한 다음 별도의 검증기나 보상 모델(RM, Reward Model)을 사용해 최상의 답변을 선택하는 것이다.
검증기나 RM은 일반적으로 후보 응답에 점수를 매기고 이 점수를 사용해 응답이 올바른지 아닌지 분류한다. 이런 RM 및 검증기를 보상 함수로 활용해 LLM을 미세조정함으로써 LLM은 정확한 답변을 생성하도록 훈련된다.
반면, 젠RM은 LLM의 텍스트 생성 기능을 활용하기 위해 '다음 토큰 예측(next token prediction)'을 사용해 검증기나 RM을 훈련하는 방식을 도입했다.
구체적으로, 솔루션에 대한 수치 점수를 생성하기 위해 검증기는 '이 답변이 올바른가'와 같은 프롬프트를 사용, 컨텍스트와 프롬프트에 따라 '네' 또는 '아니오'와 같은 단일 텍스트 토큰의 확률로 점수를 나타낸다.
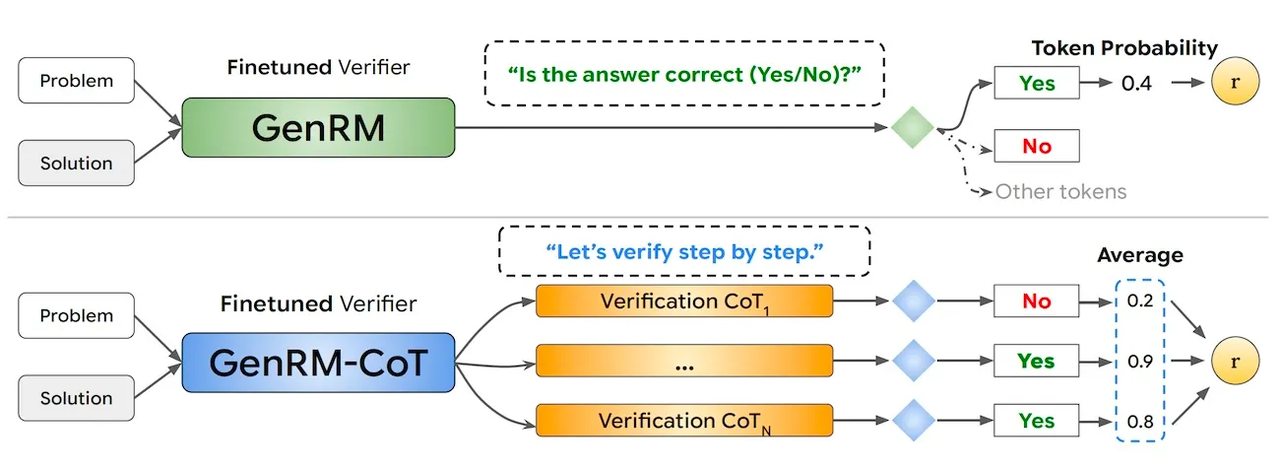
또 젠RM은 사고사슬(CoT) 추론과 같은 고급 프롬프트 기술을 지원한다. 응답의 정확성에 대한 결정을 내리기 전에 중간 추론 단계나 CoT을 생성할 수 있으며, 이를 통해 직접 검증기에서는 놓칠 수 있는 미세한 추론 오류를 식별할 수 있다.
연구진은 다수결 투표를 사용해 CoT 검증기의 검증 정확도를 더욱 향상했다. 여러 CoT 체인을 샘플링하고 모든 샘플에서 '네' 토큰의 평균 점수를 계산해 테스트 시간의 계산을 효과적으로 활용한다.
이로 인해 젠RM은 인간 평가자 대신 LLM의 품질과 정확성을 평가하는 효율적인 평가 도구로 활용될 수 있다는 설명이다. 올바른 결과에 도달하는 추론 과정을 생성, 어떤 응답이 더 나은지 판단하는 '평가형 LLM(LLM-as-a-Judge)'인 셈이다.
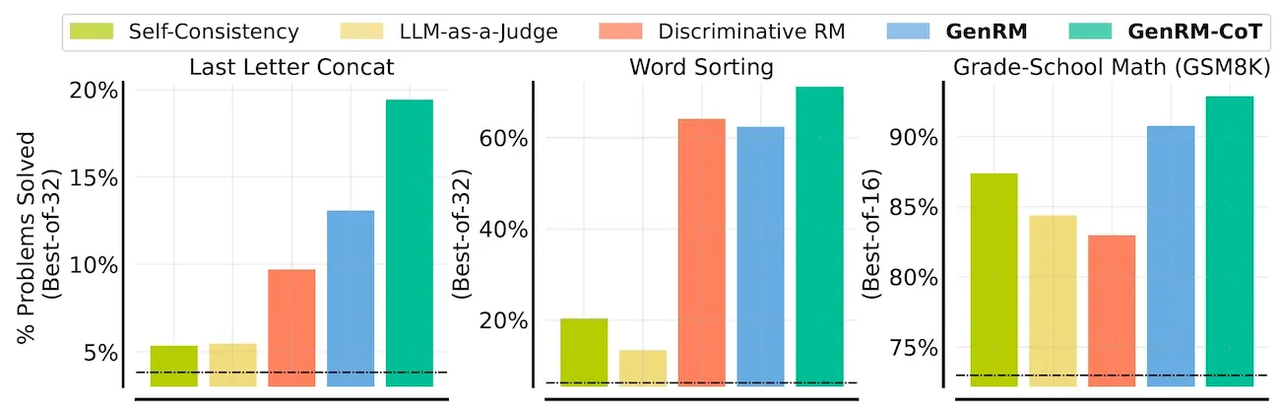
젠RM의 효과를 평가하기 위해, 연구진은 ▲마지막 글자 연결 ▲단어 정렬 ▲단어-수학 문제를 포함한 여러 추론 작업에서 테스트를 진행했다. 젠RM을 RM, 평가형 LLM, 그리고 모델이 여러 답변을 생성하고 가장 일반적인 답변을 최종 응답으로 선택하는 '자기 일관성(self-consistency)'과 같은 표준 접근 방식과 비교했다.
그 결과, 모든 작업에서 CoT를 사용한 젠RM은 다른 방법들보다 우수한 성능을 보였다. GSM8K 수학 추론 벤치마크에서는 젠RM을 위해 훈련된 '젬마-9B' 모델이 문제의 92.8%를 해결했으며, 이는 'GPT-4'와 '제미나이 1.5 프로'의 성능을 능가했다.
또 젠RM은 데이터셋 크기와 모델 용량이 증가함에 따라 성능이 확장된다는 것을 보여줬다. CoT를 사용하는 젠RM은 더 많은 응답을 샘플링할 수 있을 때, 계속 성능이 개선된다. 이는 LLM 애플리케이션 개발자들에게 정확성과 계산 비용 사이의 균형을 맞출 수 있는 더 많은 유연성을 제공한다.
연구진은 “젠RM이 다음 토큰 예측 목표를 사용해 응답 생성과 검증을 통합함으로써 모든 작업에서 검증 성능이 일관되게 향상된다”라며 “이런 개선은 직접 검증기와 CoT 기반 생성 검증기 모두에서 관찰되며, 검증기가 올바른 솔루션을 모방하도록 훈련하는 것이 일반적으로 도움이 된다는 것을 시사한다”라고 말했다.
박찬 기자 cpark@aitimes.com
