
인간 평가자 대신 대형언어모델(LLM)를 활용, LLM의 품질과 정확성을 평가하는 효율적인 평가 도구가 등장했다. 인간이 라벨을 지정한 데이터가 필요 없는 합성 데이터를 생성, 자가학습 방식으로 LLM 평가자를 훈련해 LLM 평가의 효율성과 확장성을 크게 개선했다는 설명이다.
벤처비트는 19일(현지시간) 메타가 LLM을 활용해 LLM의 품질과 정확성을 평가하는 ‘자가학습 평가자(Self-Taught Evaluator)’에 관한 논문을 아카이브에 게재했다고 보도했다.
일반적으로 LLM을 평가하는 데에는 인간 평가자를 선호하지만, 인간 평가는 느리고 비용이 많이 들며 종종 전문 지식이 필요하다는 점에서 점차 LLM이 인간 평가자를 대체하는 추세다.
그러나 문제는 LLM 평가자를 훈련하는 것도 인간이 라벨을 지정한 방대한 데이터에 의존한다는 것이다. 이는 비용이 많이 들고 시간이 많이 걸린다.
따라서 메타의 자가학습 평가자는 인간 라벨링 데이터의 필요성을 없애는 훈련 방식을 사용해 이 문제를 해결한다. 이는 올바른 결과에 도달하는 추론 과정을 생성, 어떤 응답이 더 나은지 판단하는 '평가형 LLM(LLM-as-a-Judge)' 개념으로 구축됐다.

먼저 자가학습 평가자는 시드 모델을 사용해 기본 응답을 생성하고, 그 다음 지침을 수정해 원래 응답보다 낮은 품질의 새 응답을 생성한다. 이렇게 생성된 응답 쌍 중 하나는 ‘선택된 응답'으로, 다른 하나는 ‘거부된 응답'으로 지정된다. 모델은 이 응답 쌍에 대한 추론 과정과 판단을 생성한다.
이 과정은 반복적으로 수행되며, 이를 통해 모델은 여러 평가형 LLM 추론 과정과 판단을 비교 분석한다. 올바른 추론 과정은 다시 훈련 데이터셋에 추가된다.
최종 데이터 세트는 입력 지침, 선택과 거부 응답 쌍, 그리고 판단 과정을 포함하는 일련의 예시들로 구성된다. 모델은 이 새로운 훈련 세트로 미세조정되며, 다음 반복을 위한 업데이트된 모델이 생성된다.
연구진은 '라마 3-70B-인스트럭트' 모델을 자가학습 평가자의 시드 모델로 사용했다. 인간이 작성한 대규모 지침 풀을 포함하는 와일드챗(WildChat) 데이터셋에서 2만개 이상의 예시를 선택했다.
또 코딩과 단어 수학 문제를 포함한 다른 데이터셋과 작업도 테스트했다. 이 과정에서 인간의 개입 없이 전체 답변과 훈련 세트를 생성하도록 했다.
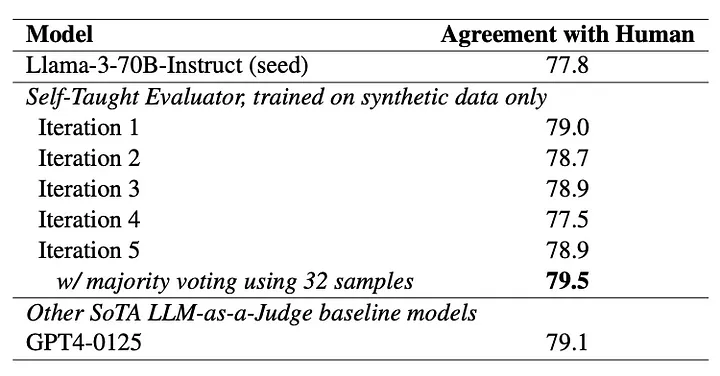
실험 결과, 자가학습 평가자는 인기 있는 리워드벤치 벤치마크에서 기반 모델의 정확도를 크게 향상시켰으며, 인간 라벨링 없이 다섯번의 반복 후 정확도를 75.4%에서 88.7%로 끌어올렸다.
이 성능은 인간이 라벨링한 데이터로 훈련된 모델과 비슷하거나 일부 경우에는 이를 능가했으며, 일부 폐쇄형 첨단 모델을 능가하기도 했다. LLM의 다중 턴 대화를 평가하는 MT-벤치 벤치마크에서도 유사한 성능 향상을 기록했다.
자가학습 평가자는 방대한 양의 라벨링되지 않은 기업 데이터를 보유한 기업들이 라벨링 수작업이나 인간 평가 없이 자체 데이터를 사용해 모델을 미세조정하는 데 도움이 될 수 있다는 평이다.
박찬 기자 cpark@aitimes.com
- "LLM, 귀납적 추론에는 강하지만 연역에는 매우 약해"
- 애플, LLM 실제 능력 파악하는 벤치마크 도구 공개..."오픈 소스, 폐쇄형 비해 많이 부족해"
- 갈릴레오, 기업용 LLM 기반 환각 평가 도구 ‘루나’ 공개
- 구글 딥마인드, LLM이 자체 응답 확인해 정확도 높이는 ‘젠RM’ 공개
- '4대 AI 회사' 모델 순위 뽑았더니...메타, 오픈AI·앤트로픽 성능에 근접
- 오픈AI, 한국어 포함 14개 언어 AI 평가용 벤치마크 데이터셋 출시
- 오픈AI, ML 엔지니어링 역량 벤치마크 공개..."o1, 인간 데이터 과학자에 못 미쳐"
- 메타, 음성-텍스트 통합 모델 출시..."AI 비서 음성에 인간 감정까지 포함"
