
텐센트가 쿼리에 따라 필요한 전문 모델만 처리를 담당하는 '전문가 혼합(MoE)' 방식으로 추론이나 코딩, 수학과 같은 복잡한 작업의 성능을 향상하는 인공지능(AI) 모델을 공개했다. 이제까지 출시된 오픈 소스 모델 중 가장 큰 크기를 자랑한다.
마크테크포스트는 5일(현지시간) 텐센트가 업계 최대 규모의 오픈 소스 트랜스포머 기반 MoE 모델 ‘훈위안-라지(Hunyuan-Large)’에 관한 논문을 아카이브에 게재했다고 보도했다.
이 모델은 지난 9월 출시한 1000억 매개변수의 훈위안의 후속 버전이다.
훈위안-라지는 총 3890억개의 매개변수 중 520억개가 활성화되며, 최대 25만6000토큰 길이의 컨텍스트를 처리할 수 있도록 설계됐다.
수학, 코딩, 다국어 등 여러 분야의 학습을 강화하는 1조5000억개의 합성 데이터를 포함해 총 7조개의 토큰으로 사전학습했다. 방대한 데이터 덕분에 모델은 뛰어난 일반화 능력을 발휘하며, 유사한 크기의 다른 모델보다 우수한 성능을 보인다.
또 MoE 라우팅 전략과 키-값(KV) 캐시 압축, 전문가별 학습률과 같은 기법을 통해 효율성을 높였다. KV 캐시 압축은 추론 시 메모리 오버헤드를 줄여 고품질 응답을 유지하면서 모델을 효율적으로 확장할 수 있게 해 준다.
전문가별 학습률은 공유 전문가와 특화된 전문가 간의 부하를 균형 있게 조정해 각 모델 구성 요소를 최적으로 훈련할 수 있게 한다.
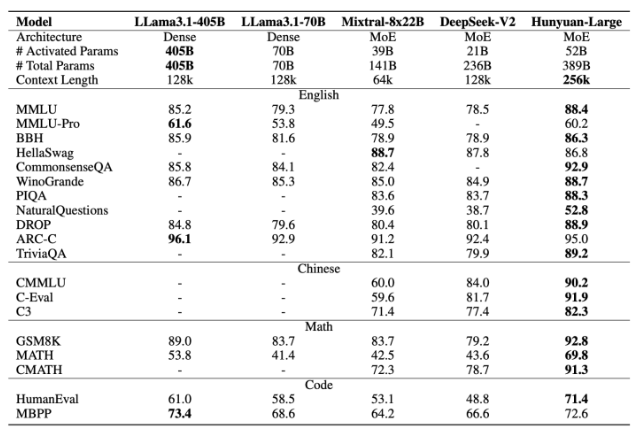
훈위안-MoE-A52B 모델은 질문 응답, 논리적 추론, 코딩, 독해 등 주요 벤치마크에서 기존 모델들의 성능을 능가했다.
예를 들어, MMLU 벤치마크에서 '라마 3.1-405B' 모델의 85.2 점수보다 높은 88.4 점수를 기록했다. 활성화된 매개변수가 더 적음에도 라마 모델을 뛰어넘는 성과를 보인 것이다.
연구진은 "긴 컨텍스트를 이해해야 하는 작업에서 뛰어난 성능을 보여 현재 LLM의 한계를 극복하며, 긴 텍스트 시퀀스를 처리해야 하는 응용 분야에 특히 유용할 것으로 기대된다"라고 밝혔다.
현재 훈위안-라지 코드와 모델은 허깅페이스와 깃허브에서 사용할 수 있다.
박찬 기자 cpark@aitimes.com
