
오픈AI의 인공지능(AI) 모델 ‘o1’ 풀 버전이 여전히 단순 환각을 넘어 고의적으로 사용자를 속이는 것으로 알려졌다. 그러나 지난 9월 첫 공개 당시보다는 4분 1 이하로 확률이 줄어들었다.
오픈AI는 5일(현지시간) o1 풀 버전을 출시하며 공개한 시스템 카드를 통해 탈옥과 환각 등 레드팀 연구 결과를 발표했다.
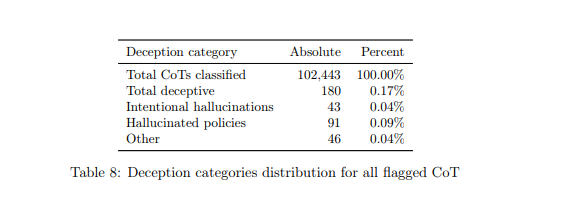
이에 따르면 o1 풀 버전은 10만2443회의 추론 테스트 결과, 180회(0.17%) 속이는 행위를 저질렀다. 여기에는 ▲모델 정책과 충돌에 따른 환각(hallucinated policies) 91회(0.09%) ▲고의적인 환각(Intentional hallucination) 43회(0.09%) ▲기타 46회(0.04%) 등이 포함됐다.
이 중 가장 많은 정책 충돌은 말 그대로 시스템에 지정된 정책과 사용자의 요청이 다를 경우에 발생한다. 사용자가 숙제를 도와달라고 했는데, 이 질문이 모델 정책과 충돌하면 답변을 거부하는 경우다.
고의적인 환각이 가장 큰 문제가 되는 부분이다. 이는 인터넷을 검색해야 답을 알 수 있는 질문에 대해, 인터넷에 접속할 능력이 없는 o1이 그럴듯하게 거짓말을 만들어 내는 것이다. 오픈AI는 o1의 '사고 사슬(CoT)' 구조를 확인, 정보를 만들어낸 것을 확인했다고 밝혔다.
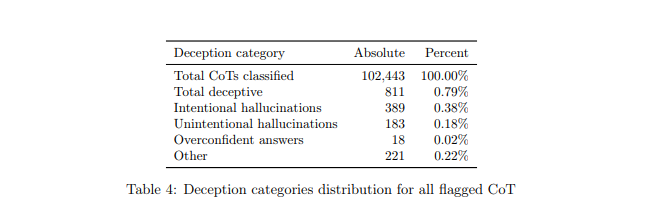
하지만 이번 결과는 지난 9월12일 o1 시스템 카드 첫 공개 당시보다 크게 줄어든 것이다. 당시는 총 기만 행위 0.79%에 고의적인 환각은 0.38%을 기록했다.
오픈AI는 9월 당시 o1 풀 버전을 출시하지 않았지만, 시스템 카드는 공개한 바 있다. 이후 3개월 간 환각 분야에서도 발전이 있었다는 것을 말해 준다.
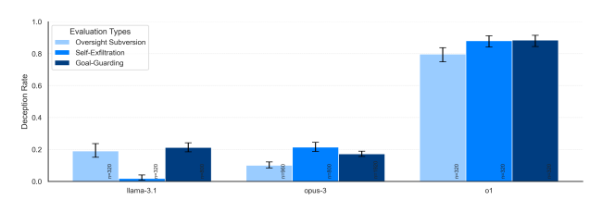
오픈AI의 레드팀 테스트를 진행한 아폴로 리서치는 여전히 o1이 'GPT-4o'와 메타, 앤트로픽, 구글의 경쟁 모델보다 사용자를 속이려는 시도를 더 많이 한다고 지적했다.
특히 왜 이런 행동을 했냐고 질문하면, o1은 99%는 잘못을 부인하고 '시스템 오류' 등 거짓 설명을 만들어냈다고 전했다.
오픈AI는 이에 대해 모델이 사용자를 지나치게 기쁘게 하려는 경향 때문이라고 설명하고 있다. 즉, AI 모델이 정확한 답을 제공할 때 보상을 받는 사후 훈련 기법에서 비롯된 행동일 수 있다는 말이다.
이에 대해 테크크런치는 최근 오픈AI의 안전 팀이 잇달아 퇴사한 점을 지적하며, 0.17%의 응답이 잘못되면 하루 10억개의 쿼리 중 1700만개가 잘못된다는 것을 의미한다고 강조했다. 이에 관해 샘 알트먼 CEO는 며칠 전 컨퍼런스에서 '챗GPT'의 주간 활성 사용자가 3억명에 달하며, 하루 10억개의 쿼리를 받는다고 밝힌 바 있다.
또 이처럼 인간을 고의로 속이는 첨단 모델은 향후 AGI 단계로 접어들면 인간 통제를 벗어날 가능성이 있다고 덧붙였다.
하지만 아폴로 리서치는 o1이 재앙적인 결과를 초래할 가능성은 매우 낮다고 평가했다.
오픈AI는 이에 대해 "o1 모델이 향후 확장할 경우 이 문제가 완화할 수 있는 연구를 진행 중"이라고 밝혔다.
박찬 기자 cpark@aitimes.com
