
구글 딥마인드가 대형언어모델(LLM)의 응답 정확도와 환격 여부를 체크하는 새로운 벤치마크를 선보였다. 동시에 이를 근거로 리더보드도 공개했는데, 구글의 '제미나이' 시리즈가 1~3위를 차지했다. 오픈AI의 추론 모델 'o1' 시리즈는 8위와 9위에 그쳤다.
구글 딥마인드는 지난주 온라인 아카이브를 통해 새로운 벤치마크 'FACTS 그라운딩(FACTS Grounding)' 논문을 게재하며 이와 관련된 리더보드를 론칭했다.
이 벤치마크는 LLM이 장문의 문서를 입력할 경우 얼마나 사실적으로 정확한 응답을 생성하는 능력을 평가한다. 또 유용하고 관련성 있는 답변을 제공할 수 있는지를 따진다.
연구진은 LLM 사전 훈련이 이전 토큰을 기준으로 다음 토큰을 예측하는 것에 중점을 두기 때문에 사실적이고 정확성이 있는 출력이 항상 나오는 것은 아니라고 지적했다. "사전 훈련은 사실적 시나리오 출력에 최적화한 것이 아니다"라며 "대신 모델이 일반적으로 그럴듯한 텍스트를 생성하도록 장려한다"라고 밝혔다.
이를 해결하기 위한 FACTS는 모델이 모델을 평가하는 방식이다. 테스트용 질문은 860개의 공개 및 859개의 비공개 샘플 등 모두 1719개로 이뤄졌다. 여기에는 ▲제공된 맥락에 따라서만 대답하라는 일반 지침과 명령이 포함된 시스템 프롬프트 ▲답변할 구체적인 질문 ▲필요 정보가 포함된 긴 문서 등이 포함됐다.
이를 통해 모델에 "회사 수익이 3분기에 감소한 이유를 요약해달라"라고 요청했을 때 "회사는 3분기에 수익에 영향을 미치는 문제에 직면했다"와 같이 구체적이지 않은 답을 내놓는 것을 실패로 간주한다는 설명이다.
또 FACTS에는 최대 3만2000개의 토큰(2만단어)에 달하는 다양한 길이의 문서와 금융이나 기술, 소매, 의학 및 법률을 포함한 전문 분야를 포함했다. Q&A 생성은 물론 요약 및 재작성 등 다양한 요청으로 상대 모델을 평가한다.
이를 통해 LLM이 요청한 내용을 정확하게 수행했는지, 또 응답은 제공한 문서 기반으로 환각이 없는지 등을 평가한다.
점수를 매기는 것도 제미나이나 'GPT-4o', '클로드 3.5 소네트' 등이다. 테스트 모델이 출력한 내용을 각각 계산한 뒤 이를 합쳐 평균을 내는 방식이다. 모델의 특정한 편향 효과를 막기 위해 심사위원의 조합이 중요하다는 설명이다.
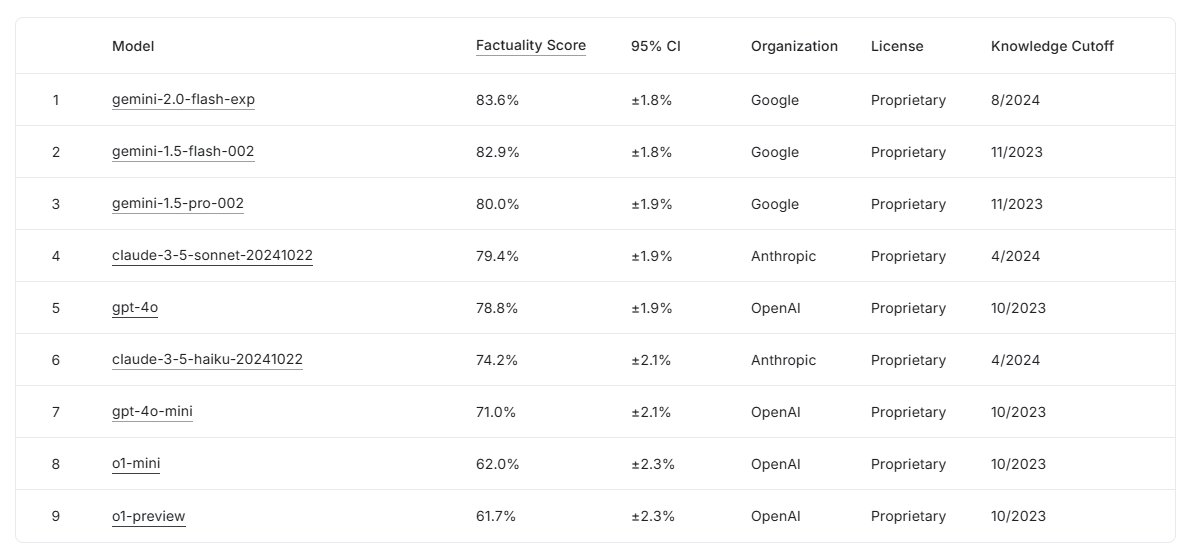
그 결과 1월 2주 현재 리더보드에서는 최신 모델인 '제미나이 2.0 플래시'가 정확도 83.6%로 1위를 차지했다. 2위는 '제미나이 1.5 플래시(82.9%)', 3위는 제미나이 1.5 프로(80.0%)' 등 구글 모델이 상위권을 휩쓸었다.
이어 클로드 3.5 소네트가 79.4%, GPT-4o가 78.8%로 4, 5위에 올랐다. 반면, 추론 기능으로 성능 높아진 것으로 알려진 o1-미니가 62%, o1-프리뷰가 61.7%로 공개된 모델 중 최하위인 8, 9위를 차지했다는 것이 의아하다. 특히 o1 모델은 컴퓨팅 리소스 투입 여부에 따라 정확도가 크게 달라질 수 있는데, 이에 대한 언급은 없다.
다만, 연구진은 리더보드가 지속적으로 업데이트될 것이라고 밝혔다. 또 "이런 포괄적인 벤치마킹 방법과 지속적인 연구 및 개발이 AI 시스템을 계속 개선할 것이라고 믿는다"라며 "이는 시작에 불과하다"라고 문제를 인정했다.
임대준 기자 ydj@aitimes.com
