인공지능(AI) 전문 나라지식정보(대표 손영호)는 16일 뚝섬역 부근에서 2024 나라지식정보 부설연구소 데모데이 ‘굿 거버넌스’를 개최, 메타버스 및 AI 광학문자인식(OCR) 등 연구 현황을 발표했다.
먼저 정부 주요 과제인 ‘접근성 지원 메타버스 콘텐츠 실시간 변환 기술 개발’ 과정을 설명했다. 시각장애인 등이 태블릿PC를 이용해 웹상의 메타버스 플랫폼을 이용할 수 있도록 지원하는 것이 목표다.
인터페이스(UI) 및 사용자경험(UX)의 최적화가 관건이었다고 밝혔다. 시각장애인의 입장에서는 ‘터치 인터페이스’ 자체가 장벽이 될 수 있기 때문이다. 이를 해결하기 위해 캐릭터 이동은 기기 자체를 기울여서 진행할 수 있도록 하고, 선택지를 간소화해 버튼 크기를 키웠다.
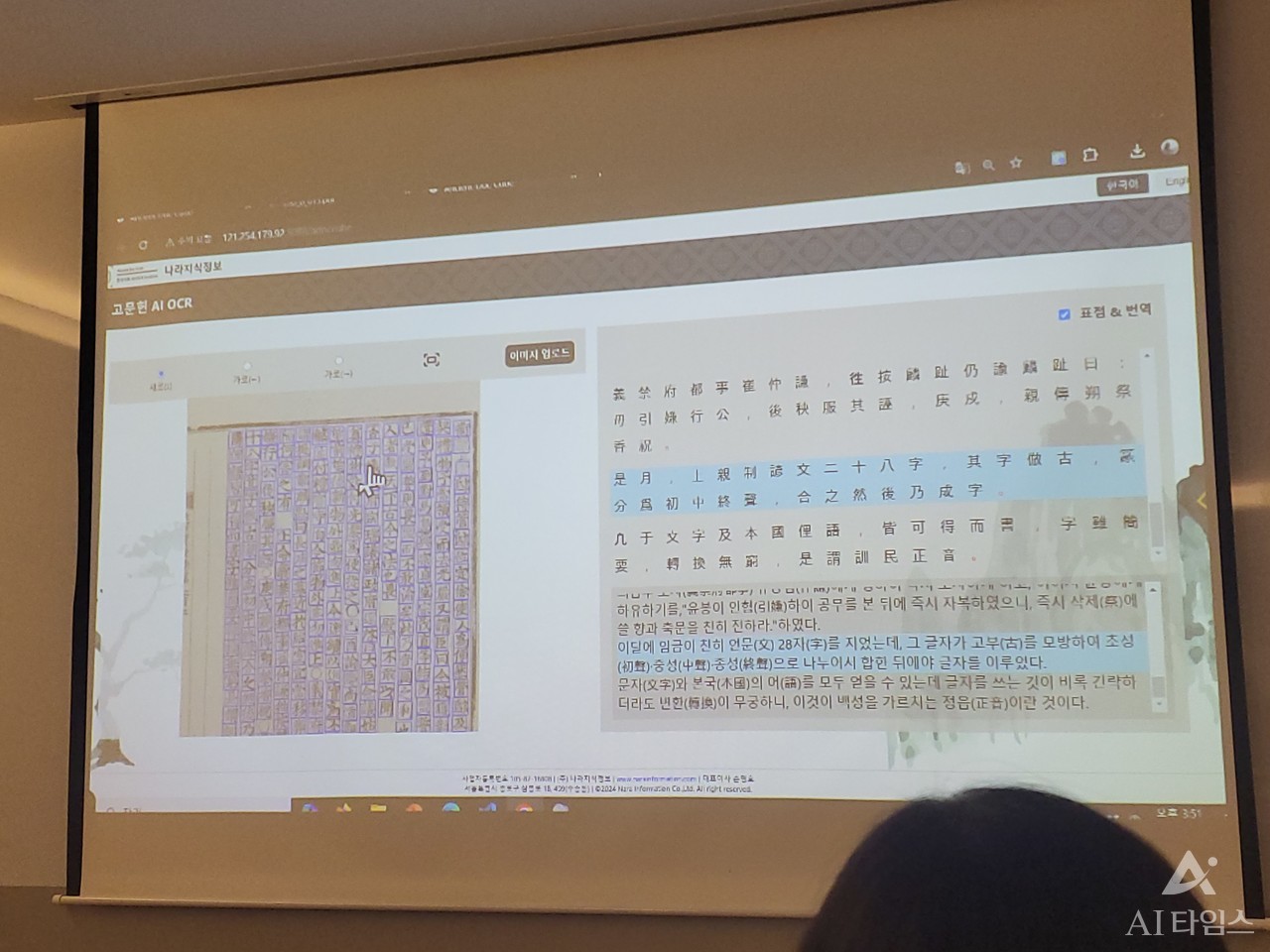
올해도 AI OCR 연구 현황을 발표했다. 지난해에는 ‘한자’ 자료에만 집중했다면, 이제는 ‘국한문’ 혼용 자료를 분석할 수 있는 다국어 모델 구축에 집중했다.
한자와 한글을 모두 구별, 정확하게 인식할 수 있는 것을 핵심 기술로 꼽았다. 한글을 비슷하게 생긴 한자로 인식하거나 한자를 한글로 인식하지 않도록 정확도를 높이는 것이 관건이다.
이에 데이터 학습에 ‘데이터 증강 기법’을 활용했다고 강조했다. 한자 자료를 글자 단위로 인식하는 기존 다국어 OCR 모델을 우선 적용하면 오류율이 높아 한글과 한자가 혼재된 데이터를 도출해낸다. 이 점을 역이용해 한번 OCR 모델을 거친 자료를 다국어 모델 학습에 이용했다고 밝혔다.
이처럼 데이터 학습과 모델 파이프라인은 어느 정도 갖췄지만, 데이터 불균형 문제를 해결해야 한다고 전했다. 데이터 증강을 활용할 경우, 글씨체나 글자 등에서 데이터 불균형이 일어나 특정 글자나 문자의 데이터가 적어지기 때문이다.
나라지식정보 관계자는 “앞으로는 데이터 불균형 문제를 해결하고, 고문헌 AI OCR과 번역 기능을 합쳐 한자 문서를 바로 한국어 내용으로 번역해서 볼 수 있도록 노력할 것”이라고 말했다.
한편, 국한문 혼용 문서에 대해서는 현재 평균 OCR 인식 정확도 94.8%를 기록 중이라고 밝혔다.
장세민 기자 semim99@aitimes.com
