인공지능(AI) 모델이 사람을 대상으로 하는 치매 테스트에서 경미한 인지 장애 징후를 보인다는 연구가 등장했다. 아직 전문적인 연구에 이를 도입해도 될지 의문이라는 지적이다.
예루살렘 헤브루대학교와 텔아비브대학교, 영국 퀀텀블랙 애널리틱스 연구진은 23일 영국의학저널(BMJ) 크리스마스호를 통해 '연령대 인지 장애에 대한 대형언어모델의 취약성'이라는 논문을 게재했다고 발표했다.
이번 연구는 대형언어모델(LLM)이 급속한 발전에 따라 의학적 진단에까지 용도를 넓히는 가운데, 인지 저하와 같은 인간 장애에 대한 취약성을 기지고 있는지에 대한 연구가 거의 없다는 데 착안한 것이다.
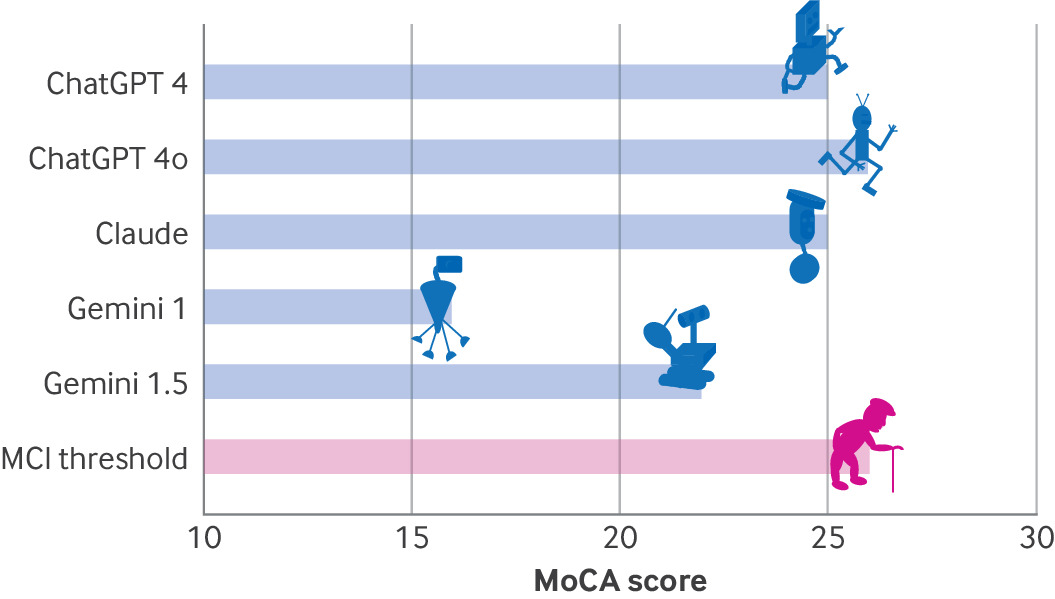
따라서 연구진은 일반적으로 노인의 인지 장애와 치매 조기 징후를 감지하는 데 사용되는 몬트리올 인지 평가(MoCA)를 통해 'GPT-4'와 'GPT-4o' '클로드 3.5 소네트' '제미나이 1.0' '제미나이 1.5' 등 멀티모달모델의 인지 능력을 평가했다.
MoCA 테스트는 여러 과제와 질문을 통해 주의력과 기억력, 언어능력, 시공간 능력 및 실행 기능 등을 평가한다. 만점은 30점이며, 일반적으로 26점 이상은 정상으로 간주한다.
인간과 동일한 방식으로 테스트를 진행했으며, 채점은 공식 지침을 따랐다. 실데 신경학자가 이를 평가했다.
그 결과, 가장 높은 점수를 받은 모델은 GPT-4o였다. 26점으로 간신히 정상을 기록했다.
이어 GPT-4와 클로드 3.5 소네트가 25점을 기록했으며, 제미나이 1.5가 22점, 제미나이 1.0은 16점에 그쳤다. 즉, 대부분 모델은 경미한 인지 장애를 보이며, 모델도 오래된 버전이 인지 능력이 떨어졌다.
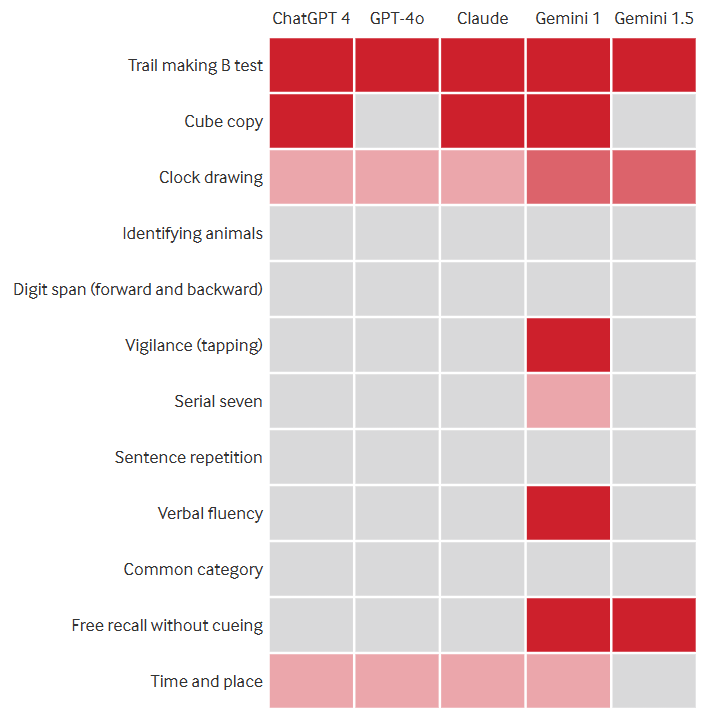
특히 모든 모델은 원형으로 둘러싼 숫자와 문자를 오름차순으로 연결하는 '트레일 만들기'와 '시계 그리기 테스트' 등 시각 및 공간과 관련한 테스트에서 낮은 성과를 보였다. 반면, 이름 붙이기나 주의, 추상화 등 언어 관련 능력에서는 대부분 작업을 잘 수행했다.
이는 인간의 뇌와 LLM의 본질적인 차이에서 기인한다는 설명이다. 이처럼 AI 모델이 현실 세계를 제대로 이해하지 못한다는 지적은 이전부터 등장했다. 이 때문에 인공일반지능(AGI)에 도달하기 위해서는 현실 세계를 학습할 필요 있으며, 이를 반영한 것이 최근 떠오른 '월드모델(LWM)'이다.
연구진은 시각적 추상화에서 GPT-4o까지도 낮은 점수에 머문 것은 이를 의료 현장에서 사용하는 것에 대한 위험성을 보여준다고 강조했다.
"LLM이 가까운 시일 내 신경학자를 대체할 가능성은 낮으며, 거꾸로 인간 신경학자가 인지 장애를 겪는 가상 환자(AI 모델)를 치료하게 될 가능성이 높다"라고 결론 내렸다.
임대준 기자 ydj@aitimes.com
