오픈AI의 'o1'을 따라잡으려는 중국의 시도가 이어지고 있다. 이번에는 일반적인 지식 증류(distillation) 방법 대신, 추론 모델 구축을 위한 강화 학습(RL) 프레임워크가 잇달아 공개됐다.
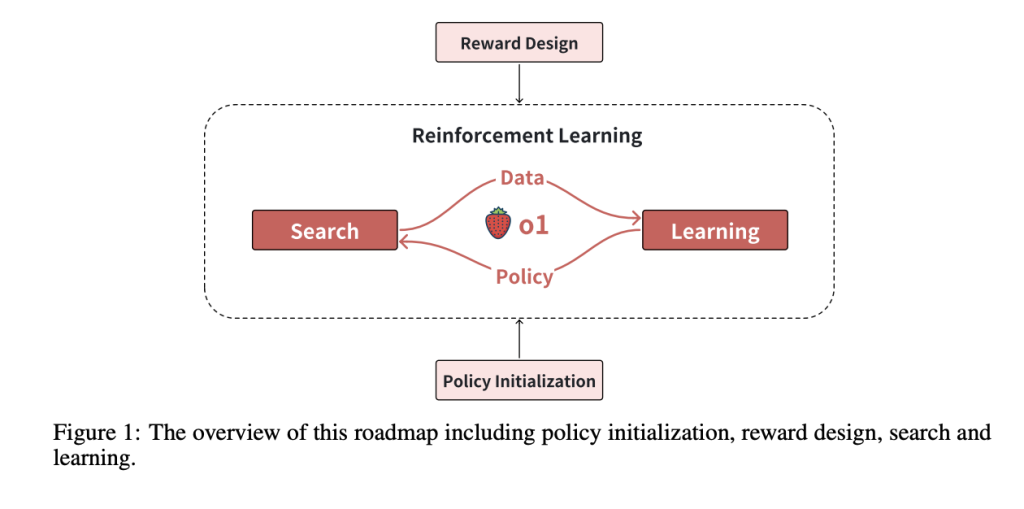
중국 푸단대학교와 상하이 인공지능(AI) 연구실은 최근 강화 학습의 관점에서 o1을 재생산하기 위한 로드맵을 개발했다고 발표했다. 논문의 제목은 '검색 및 학습의 확장: 강화 학습 관점에서 o1을 재생산하기 위한 로드맵'이다.
말 그대로 o1 모델을 구축하기 위해 검색과 강화 학습을 확장한다는 내용이다. 실제로 이 프레임워크는 ▲정책 초기화 ▲보상 설계 ▲검색 ▲학습 등 네가지 핵심 구성 요소에 초점을 맞췄다.
정책 초기화를 통해 모델은 인간과 유사한 추론 행동을 개발, 복잡한 문제에 대한 솔루션을 효과적으로 탐색할 수 있는 능력을 갖추게 된다.
보상 설계는 프로세스 보상과 같은 기술을 사용해 중간 단계를 검증하는 것으로, 오픈AI가 스스로 o1의 핵심이라고 밝힌 강화 학습(RL)과 검색을 강화하기 위한 것이다.
검색 전략으로는 '몬테카를로 트리 탐색(MCTS)' 및 '빔 탐색'으로 고품질 솔루션을 생성하는 데 초점을 맞췄다. 검색을 통해 생성한 데이터는 RL을 통해 모델 정책을 반복적으로 개선한다.
이런 요소를 통합, 결국 추론 기능을 향상하는 검색과 학습 간의 시너지를 보여준다는 내용이다. 또 이 방식은 수동으로 큐레이팅된 데이터에 대한 의존도를 줄여, 추론 기능을 향상하면서 리소스를 효율적으로 만든다고 설명했다.
연구진도 "오픈AI는 o1의 주요 기술이 RL이라고 주장했다"라며 "최근 많은 연구에서 지식 증류와 같은 대체 접근 방식을 사용해 o1의 추론 스타일을 모방하지만, 그 효과는 교사 모델의 역량 한계에 의해 제한된다"라고 지적했다. 이에 따라 RL의 관점에서 o1을 달성하기 위한 로드맵을 분석했다고 설명했다.
이 프레임워크를 적용한 결과, 추론 정확도와 일반화에서 큰 개선이 이뤄졌다고 밝혔다.
예를 들어, 프로세스 보상은 까다로운 추론 벤치마크에서 작업 성공률을 20% 이상 증가했다. MCTS와 같은 검색 전략은 고품질 솔루션을 생성하는 데 효과적이며, 구조화된 탐색을 통해 추론을 개선했다. 또 검색으로 생성된 데이터를 사용한 반복 학습을 통해 모델은 기존 방법보다 적은 매개변수로 고급 추론 기능을 달성할 수 있었다는 설명이다.
연구진은 "이런 결과는 o1과 같은 모델의 성능을 복제하기 위해서는 RL이 핵심이며, 일반적으로 이 프레임워크가 유효하다는 것을 보여준다"라고 전했다.
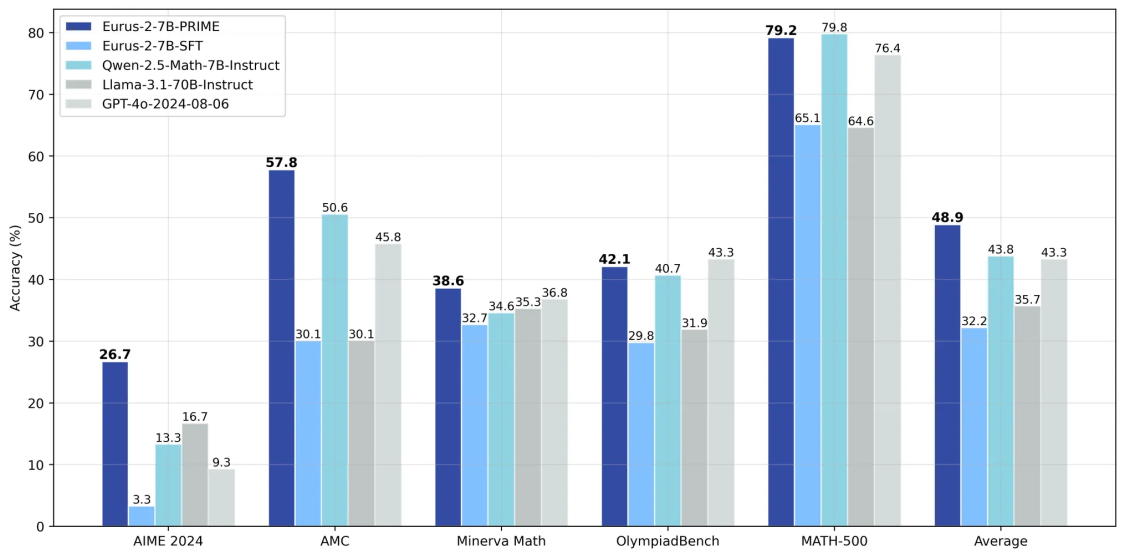
칭화대학교 등으로 구성된 연구진도 RL을 통한 추론 모델 개발법을 오픈 소스로 공개했다. '프라임(Process Reinforcement through IMplicit Rewards)'이라는 접근 방식 역시 RL 프로세스 보상을 통해 모델 추론을 강화하는 것이다.
이를 통해 연구진은 '큐원2.5-매스-7B(Qwen2.5-Math-7B)'를 베이스로 강력한 추론 모델인 '유러스-2-7B-프라임(Eurus-2-7B-PRIME)'을 개발할 수 있었다고 전했다. 이 모델은 AIME(수학경시대회) 벤치마크에서 26.7%를 기록, 'GPT-4o'와 소스 모델인 큐원2.5-매스를 능가했다고 밝혔다.
이처럼 o1 출시 후 최근 중국에서는 잇달아 o1을 따라잡기 위한 연구 결과가 쏟아지고 있다.
지난주에는 텐센트와 상하이 자오퉁대학교 연구진이 추론 전문 모델의 과잉 사고 문제를 해결하기 위한 학습 방법을 공개했으며, 난징대학교 등도 추론 중 토큰 사용량을 최소화하면서 정확도를 유지할 수 있는 추론 프레임워크 논문을 공개했다.
또 딥시크와 알리바바, 문샷 등 주요 AI 기업도 추론 전문 모델을 공개해 눈길을 끌었다. 그중 딥시크의 'V3'는 오픈 소스 역대 최고 규모와 성능으로 주목받았다.
임대준 기자 ydj@aitimes.com
