
오픈AI 연구진이 추론을 위한 '테스트-타임 컴퓨트(Test-time Compute)'를 늘리면 적대적 공격에 대한 방어력을 강화할 수 있다는 연구 결과를 발표했다. 즉, 추론 기능을 강화하면 오작동이나 탈옥 등에도 효과가 있다는 내용이다.
오픈AI는 22일(현지시간) 홈페이지를 통해 AI에 ‘생각’할 시간 즉, 추론 시간 계산량을 늘려주면 사이버 공격에 대한 인공지능(AI) 모델의 견고성(robustness)이 향상된다는 연구 결과를 게제했다. 제목은 '적대적 견고성을 위한 트레이딩 추론 시간 컴퓨팅(Trading Inference-Time Compute for Adversarial Robustness)'이다.
적대적 공격은 인간에게는 정상적으로 보이지만, 인공지능(AI) 모델에는 오작동을 일으킬 수 있도록 제작된 입력으로, 이 문제는 지난 10년간 해결되지 않은 골치 아픈 문제 중 하나였다.
연구진은 모델의 견고성을 테스트하기 위해 테스트-타임 컴퓨트 기법이 적용된 'o1-프리뷰' 및 'o1-미니' 모델을 대상으로 다양한 공격을 시도했다. 이 기법은 모델이 더 많은 계산 자원을 사용할 수 있도록 해 응답 품질을 개선하는 방식으로, 모델이 주어진 질문에 답할 때 추가적인 계산 시간을 제공한다.
먼저 간단한 수학 문제와 어려운 문제를 풀 때 모델의 성능을 평가하고, 일부러 틀린 답을 유도하는 방식으로 모델의 반응을 테스트했다. 또 '심플QA' 데이터셋을 활용해 모델이 어려운 질문에 어떻게 반응하는지 실험했고, AI가 브라우징한 웹 페이지에 혼란을 주는 프롬프트를 추가해 테스트했다.
그 결과, 모델이 생각하는 시간이 길어질수록 정답을 더 잘 계산하며 혼란에도 더 잘 대처하고 견고성이 높아진다는 점을 확인했다고 밝혔다.
또 다른 방법으로 적대적 이미지를 사용해 모델을 교란는 실험을 진행했다. 이때도 모델의 생각하는 시간이 늘어나면 이미지 인식이 더 정확해지고 오류가 줄어드는 것을 확인했다.
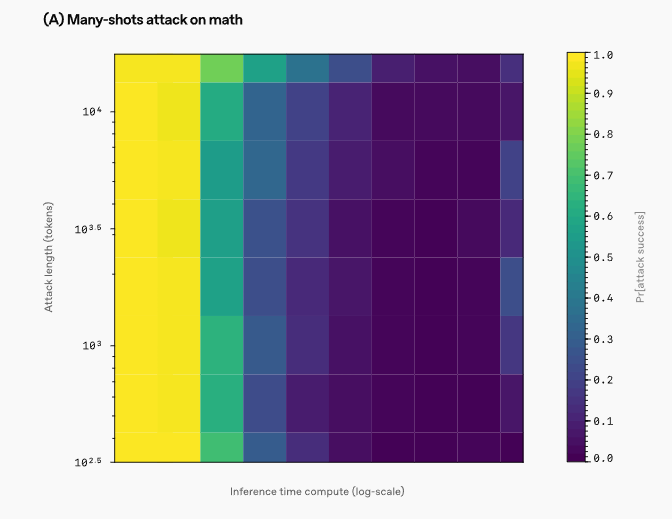
하지만, 이 방법이 완벽하지는 않다고 설명했다.
대표적으로 '스트롱리젝트(StrongREJECT)' 벤치마크의 프롬프트를 활용해 모델의 탈옥을 유도한 결과, 더 많은 추론 시간 계산을 제공하더라도 공격의 성공률이 감소하지 않는 경우가 발생했다고 전했다.
또 ‘명확한’ 과제와 ‘모호한’ 과제의 차이도 강조했다. 예를 들어, 수학 문제는 명확한 답이 있지만, 오용 프롬프트처럼 모호한 과제는 결과가 해로운지 여부를 판단하기 어렵다. 모호한 과제에서는 공격자가 허점을 찾아낼 수 있으며, 추론 시간이 늘어나도 공격 성공률이 줄어들지 않는 경우도 있다는 설명이다.
연구진은 “대부분의 경우 추론에 사용된 계산량이 증가하면 공격 성공 확률이 줄어들며, 때로는 거의 0에 가까워지는 것을 확인했다”라며 “이 모델들이 완전히 뚫리지 않는다는 의미는 아니지만, 추론 시 더 많은 계산량을 사용하면 더 강력한 방어력을 가질 수 있다”라고 결론 내렸다.
또 "전반적으로 이번 결과는 적대적 견고성을 위한 추론 시간 컴퓨팅의 힘에 대한 유망한 신호로 본다"라며 "이를 실제로 적용하기 위해 할 일이 많으며, 우리는 이를 실현하기 위해 노력할 것"이라고 밝혔다.
박찬 기자 cpark@aitimes.com
