
구글이 인공지능(AI) 모델이 더 많은 사고를 통해 답변할 수 있도록 하는 고급 '테스트-타임 컴퓨트(Test-time Comput)’ 최신 기술을 공개했다. 이 방식은 모델이 여러 번의 답변을 생성하고 이를 검토 및 수정하며 문제를 해결하는 다양한 방법을 탐색하는 것으로, 이번에는 '사고 진화'라는 개념을 도입했다.
구글 딥마인드 연구진은 22일(현지시간) 대형언어모델(LLM)의 계획 및 추론 작업에 대한 응답을 최적화하는 '마인드 에볼루션(Mind Evolution)' 기법에 관한 논문을 아카이브에 게재했다.
마인드 에볼루션은 ▲탐색(search)과 ▲유전(genetic) 알고리즘이라는 두가지 요소를 기반으로 한다.
탐색은 여러 테스트-타임 컴퓨트 기법에서 흔히 사용되며, LLM이 최적의 해결책을 도출할 수 있도록 최적의 추론 경로를 찾아내는 데 중요한 역할을 한다.
유전 알고리즘은 자연 선택(natural selection) 원리를 바탕으로, 목표를 달성하기 위한 후보 솔루션을 생성하고 진화시킨다. 자연 선택은 환경에 잘 적응한 생물체가 더 잘 생존하고 번식하는 진화 과정을 의미하며, ‘자연 도태’라고도 한다.
이는 AI 모델에서는 종종 ‘적합도 함수(fitness function)’라는 개념으로 표현된다. 적합도 함수는 문제의 후보 솔루션이 얼마나 문제의 답으로 적합한지를 평가하기 위한 것이다. 이는 실제 세계의 생명체가 유전적 특성에 따라 환경에 얼마나 잘 적응할 수 있는지가 결정되는 것에 비유한 것이다.
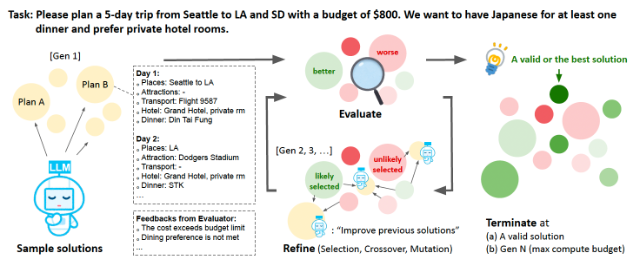
마인드 에볼루션은 문제에 대한 설명과 정보를 바탕으로 여러 해결책의 후보를 만드는 것부터 시작한다. LLM은 후보들을 생성한 뒤 이들을 평가하고 부족한 부분을 개선한다.
그 다음 알고리즘은 기존의 해결책 중에서 더 좋은 것을 선택한다. 선택된 해결책들을 합쳐서 새로운 해결책을 만들고, 일부는 무작위로 수정 과정을 거친다. 이 과정은 해결책을 점점 더 개선하기 위해 반복된다.
이 과정을 통해 알고리즘은 최적의 해결책을 찾거나, 미리 정해 놓은 반복 횟수에 도달할 때까지 계속 진행된다. 이처럼 기존 해결책의 장점만을 취해 다음 세대로 발전하는 것을 '유전'이라고 표현한 것이다.
마인드 에볼루션에서 중요한 부분은 평가 함수다. 일반적인 테스트-타임 컴퓨트 기법에서는 문제를 자연어에서 기호나 구조화된 형식으로 바꿔야 한다. 이렇게 바꾼 문제를 해결 프로그램이 처리할 수 있도록 하는데, 이 과정은 많은 전문 지식과 문제의 핵심 요소를 이해하는 것이 필요해서 적용이 어려울 수 있다.
하지만 마인드 에볼루션에서는 해결책을 자연어로 표현한다. 이렇게 하면 문제를 형식화할 필요가 없고, 해결책을 평가하는 프로그램만 있으면 된다. 또 숫자 점수뿐만 아니라 텍스트로 피드백을 제공, LLM이 문제를 더 잘 이해하고 개선할 수 있도록 돕는다.
마인드 에볼루션은 여러 해결책을 탐색하기 위해 ‘아일랜드(island)’라는 방식을 사용한다. 각 단계에서 알고리즘은 해결책을 여러 그룹으로 나누고, 각 그룹에서 해결책을 발전시킨다. 그 다음 가장 좋은 해결책을 다른 그룹으로 옮겨서 결합하고 새로운 해결책을 만들어내는 식이다.
연구진은 마인드 에볼루션을 '1-패스(1-pass)', '베스트-오브-N(Best-of-N)', '순차적 개선+(Sequential Revisions+)'와 같은 기준 모델들과 비교해 테스트했다. 1-패스는 모델이 하나의 답만 내놓는 방식이고, 베스트-오브-N은 여러 답을 만들고 그 중 가장 좋은 답을 고르는 방식이다. 순차적 개선+는 10개의 후보를 제시한 뒤, 각각을 80번 수정하는 방식이다. 순차적 개선+는 마인드 에볼루션과 가장 비슷하지만, 발견한 답에서 좋은 부분을 결합하는 유전 알고리즘이 없다.
연구진은 '제미나이 1.5 플래시'를 사용해 여행 계획을 짜주는 벤치마크 '트레블러플래너(TravelPlanner)'로 테스트했다.
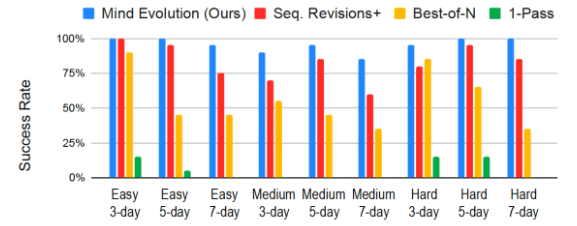
1-패스를 적용한 제미나이 1.5 플래시는 성공률이 5.6%에 불과했으며, 베스트-오브-N 방법을 사용해 800개 이상의 응답을 생성한 결과도 55.6%에 그쳤다. 반면, 마인드 에볼루션을 적용한 제미나이 1.5 플래시는 무려 95%의 성공률을 기록했다.
순차적 개선+가 성능 면에서 비슷한 결과를 보였지만, 마인드 에볼루션은 그보다 훨씬 적은 수의 토큰을 사용했다. 마인드 에볼루션이 비용 효율적이라는 설명이다.
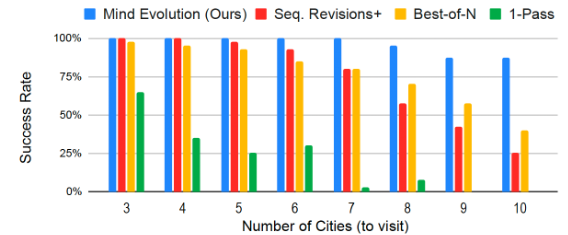
특히, 작업이 더 어려워질수록 마인드 에볼루션은 기준 모델들을 크게 초과하는 성과를 보였다.
예를 들어, 각 도시를 방문할 일수를 설정해 여행 일정을 작성하는 '트립 플래닝(Trip Planning)' 벤치마크에서는 마인드 에볼루션이 94.1%의 성공률을 기록했으며, 다른 방법들은 최대 77%의 성공률에 그쳤다. 도시 수가 많아질수록 차이는 커졌다.
연구진은 "이번 결과는 확률적 탐색을 통한 광범위한 탐색과 LLM을 활용한 심층 탐색을 결합한 진화적 전략의 명확한 장점을 보여준다"라고 밝혔다.
박찬 기자 cpark@aitimes.com
- 구글도 LLM 성능 둔화로 사후 훈련에 집중...'하이퍼파라미터' 조정 등 시도
- "LLM 사전훈련 통한 성능 향상 한계...앤트로픽·구글 등도 추론에 집중"
- "GPT 성능 향상 속도 둔화"...오픈AI, '오라이온' 개선 위해 전략 수정
- 오픈AI “테스트-타임 컴퓨트 늘어나면 적대적 공격 대처에도 효과적”
- 구글, 딥시크 충격 속에 '조용히' 차세대 프론티어 모델 출시
- 메타, 쿼리 난이도 따른 추론 최적화 기술 공개..."더 열심히가 아니라 더 똑똑하게 생각하라"
- “테스트-타임 스케일링 잘 쓰면 sLM도 매개변수 100배 이상 LLM 성능 능가”
- '테스트-타임 컴퓨트' 이어 '추론-시간 검색' 등장...'제4의 스케일링 법칙' 여부로 논란
- “강화학습은 효율에 집중한 LLM 훈련법...창의력을 키우지는 못해”
