
소형언어모델(sLM)에 '테스트-타임 스케일링(TTS)' 기술을 잘 적용하면, 추론 작업에서 100배 이상 큰 대형언어모델(LLM)의 성능을 능가할 수 있다는 연구 결과가 나왔다.
상하이 AI 연구소는 20일 ‘1B LLM이 405B LLM을 능가할 수 있을까? 최적의 테스트 시간 스케일링 전략arxiv.org/pdf/2502.06703’이라는 논문을 온라인 아카이브에 공개했다.
논문 제목에 등장한 1B 모델은 '라마-3.2-3B'이며, 405B 모델은 '라마-3.1-405B'를 말한다. 따라서 논문 제목은 약간 과장이 된 것일 수 있지만, 그만큼 TTS 기술이 강력하다는 것을 강조한 셈이다.
TTS는 LLM이 추론 시 더 많은 자원과 시간을 사용해 어려운 질문에 대한 응답 정확도를 높이는 방식으로 잘 알려져 있다. 구체적으로는 '내부 TTS(Internal TTS)'와 '외부 TTS(External TTS)'로 나뉜다.
우선, 오픈AI 'o1'과 '딥시크-R1'과 같은 첨단 모델에 적용된 방식은 내부 TTS다. 이는 모델의 사훈 훈련을 통해 '사고 사슬(CoT)' 토큰을 길게 생성해 천천히 생각하도록 미세조정했다.
반면, ‘외부 TTS’는 미세조정 없이 외부 모델을 추가하는 방식이다. 이때 답변을 생성하는 원래 모델을 ‘정책 모델(Policy Model)’이라고 지칭하고, 이 모델이 생성한 답변을 평가하는 ‘프로세스 보상 모델(PRM)’이 추가된다. 두 모델이 동시에 작동하며 추론 성능을 높이는 방식이다.

외부 TTS를 적용하는 것도 다양한 방법이 있다. 그중 가장 간단한 것은 ‘베스트-오브-N(Best-of-N)’ 방식으로, 정책 모델이 여러 개의 답변을 생성한 후, PRM이 가장 좋은 답변을 선택하여 최종 응답을 만든다.
더 고급 기법으로는 탐색을 사용하는 방식이 있다. 예를 들어, ‘빔 서치(Beam Search)’는 답변을 여러 단계로 나눠 생성하고, 각 단계에서 여러 답변 후보를 만들어 PRM이 이를 평가한 후, 가장 적절한 것을 선택해 다음 단계를 이어간다.
‘다양성 검증 트리 탐색(DVTS)’ 방식은 여러 답변가지(branch)를 생성, 다양한 후보를 비교하고 잘못된 경로를 피하면서 최종 답변을 도출하는 빔 서치의 변형이다
결국 이번 연구는 외부 TTS를 활용할 경우, 정책 모델과 보상 모델이 어떤 상관관계로 추론 성능에 영향을 미치는지 밝혀낸 것이다.
연구 결과, TTS의 효율성은 정책 모델과 PRM에게 크게 좌우되는 것으로 나타났다. 예를 들어, 작은 정책 모델에서는 검색 기반 방법이 베스트-오브-N보다 성능이 뛰어나지만, 정책 모델이 커지면 베스트-오브-N이 더 효과적이었다. 이는 큰 모델이 더 뛰어난 추론 능력을 갖추고 있기 때문에, 모든 단계를 PRM으로 검증할 필요가 없다는 것을 말해 준다.
또 적절한 TTS 전략이 문제의 난이도에 따라 달라질 수 있는 것으로 나타났다. 70억개 이하의 매개변수를 가진 작은 모델의 경우, 쉬운 문제에서는 베스트-오브-N이 효과적이지만, 어려운 문제에서는 빔 서치가 더 나은 성능을 보였다.
반면, 매개변수가 70억~320억인 모델은 쉬운 문제와 중간 난이도에서는 DVTS가 효과적이며, 어려운 문제에서는 빔 서치가 가장 적합했다. 그러나 720억개 이상의 매개변수를 가진 대형 모델에서는 베스트-오브-N이 최적의 방법으로 나타났다.
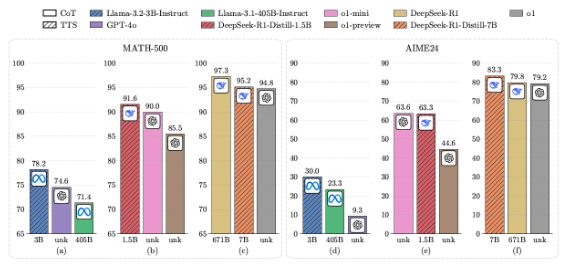
연구진은 벤치마크에서 TTS 전략을 적용한 '라마-3.2-3B' 모델이 'MATH-500'과 'AIME 2024' 등 수학 벤치마크에서 '라마-3.1-405B'보다 뛰어난 성능을 보였다고 밝혔다. 이는 최적화된 TTS 전략을 활용하면 무려 매개변수가 135배나 큰 LLM보다 sLM이 더 나은 성능을 발휘할 수 있음을 보여준다.
또 다른 실험에서는 매개변수 5억개를 가진 '큐원2.5' 모델에 TTS 전략을 적용했을 때 'GPT-4o'를 능가하는 성과를 보였다. 15억개의 매개변수를 가진 '딥시크-R1-증류' 버전은 MATH-500과 AIME24에서 'o1-프리뷰' 및 'o1-미니'보다 더 우수한 성능을 기록했다.
이처럼 최적화된 TTS 전략은 모델의 추론 능력을 크게 향상한다. 또 모델의 크기가 커질수록 성능 향상 효과는 점차 줄어드는 경향을 보였다.
이런 연구 결과를 바탕으로 개발자는 모델, PRM, 문제 난이도를 고려해 최적의 연산 자원 활용을 위한 TTS 전략을 설계하고, 제한된 컴퓨팅 자원 내에서도 추론 문제를 효율적으로 해결할 수 있다는 설명이다.
다만, 연구진은 "외부 TTS에는 여전히 한계가 존재한다"라고 지적했다. 정책 모델과 PRM을 병렬로 실행해야 하고, 이 기술은 수학이나 코딩처럼 명확한 답을 평가할 수 있는 문제에서만 성능을 발휘한다는 설명이다.
하지만 이번 연구로 TTS 기술의 단계별 추론 프로세스를 공개한 점은 주목할 만하다는 평이다. 오픈AI는 사고 사슬(CoT) 구조와 같은 내부 작동 방식을 비공개로 유지하기 때문이다.
박찬 기자 cpark@aitimes.com
