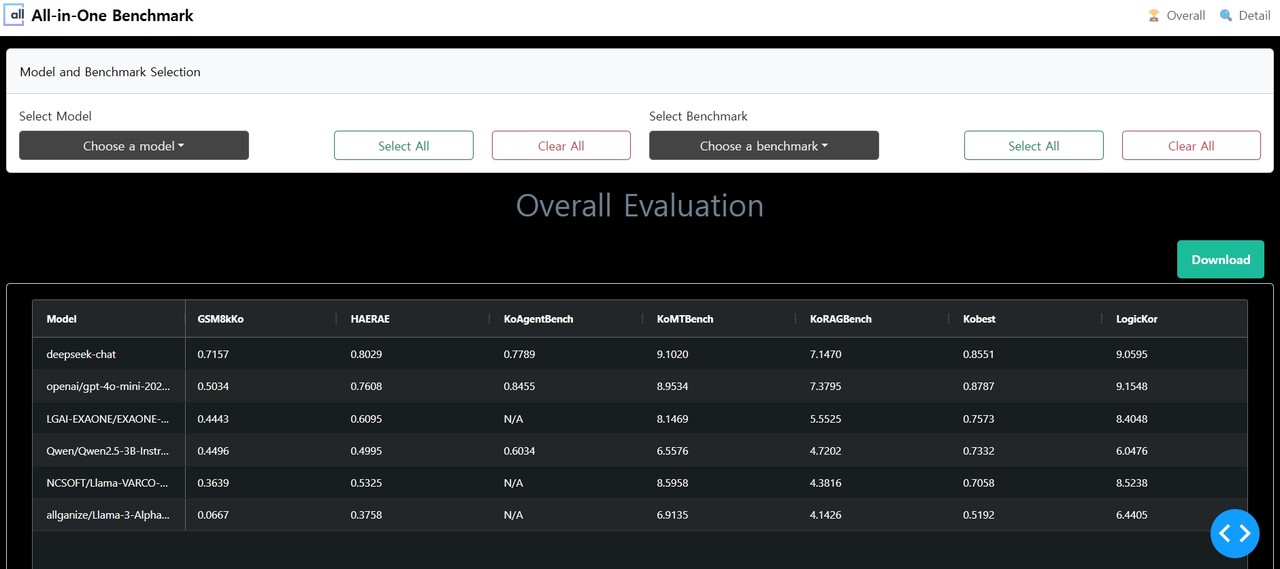
국내 기업에서 내놓은 인공지능(AI) 에이전트 성능 평가에서 '딥시크-‘V3’ 에이전트 성능이 ‘GPT-4o 미니’와 유사한 것으로 나타났다.
올거나이즈(대표 이창수)는 3일 국내 최초로 대형언어모델(LLM)의 에이전트 역량을 평가하는 ‘올인원 벤치마크’를 공개했다고 밝혔다.
올인원 벤치마크는 지난해 공개한 ‘금융 전문 LLM 리더보드’에서 발전, LLM의 에이전트 성능을 종합적으로 평가하는 플랫폼이다.
다양한 상황에서 ▲스스로 외부 도구를 호출하는 ‘툴 콜링(tool calling)’ 능력을 평가하는 ‘BFCL’ ▲한국어 환경에서 툴 콜링 능력을 평가하는 ‘펑션챗벤치(FunctionChatBench)' ▲유통, 항공 등 실제 산업 현장 상황에서 LLM의 문제 해결 능력을 평가하는 ‘타우벤치(TauBench)’ 등 3종의 벤치마크 테스트를 제공한다.
올거나이즈는 이를 통해 딥시크-V3의 에이전트 성능을 평가, GPT-4o 미니와 유사한 결과를 확인했다고 밝혔다. V3는 박사 수준의 과학 지식을 평가하는 'GPQA-다이아몬드'와 수학 문제 해결 능력을 평가하는 ‘매스 500’, 코드 생성 및 이해 평가 ‘코드포스’ 등을 통해 성능을 평가한 일은 있지만, 에이전트 성능 평가는 올거나이즈가 최초라고 전했다.
이 밖에도 LLM의 성능을 종합적으로 평가할 수 있는 총 12종의 벤치마크를 제공한다고 덧붙였다.
평가 방법도 간소화해 신규 출시된 LLM의 성능을 쉽게 확인할 수 있다고 전했다. 새로 나온 LLM 이름을 입력하면 플랫폼이 모델의 API를 자동으로 구현하고, 평가를 진행하는 방식이다. LLM이 출시될 때마다 각 벤치마크의 개별 코드를 실행해 동일 작업을 수차례 진행하는 기존의 문제점을 해결했다는 설명이다.
평가 시간도 대폭 단축, 기존 벤치마크에서 1시간30분 걸리던 시간이 올거나이즈의 플랫폼에서는 20여분으로 줄었다.
이창수 대표는 “기업이 생산성 향상을 위해 AI 모델을 도입하는 데 도움이 되는 LLM 평가 플랫폼을 지속적으로 업데이트해 나갈 예정”이라며 “나아가 에이전트 역할을 제대로 수행하는 LLM을 개발하기 위해 기존 LLM의 에이전트 성능을 확인하고 이를 향상시키기 위한 학습 방법을 심도 있게 연구하고 있다”라고 말했다.
박수빈 기자 sbin08@aitimes.com
