
로봇이 원활하게 작동하기 위해서는 주변 환경을 정확하게 이해하고 계획을 설정하며 정확하게 움직이는 3가지 능력이 필요하다. 이제까지 이런 기능은 개별 모델에 분리됐는데, 이를 통합한 최고 성능의 '비전-언어-행동모델(VLAM)'이 등장했다.
마이크로소프트(MS)와 메릴랜드대학교, 위스콘신대학교-매디슨, 한국과학기술원(KAIST), 워싱턴대학교 등 연구진은 20일(현지시간) ‘마그마(Magma)’라는 새로운 VLAM에 관한 논문을 발표했다.
연구진은 기존 VLA 모델이 비전-언어 쌍과 행동 데이터를 대규모 데이터셋으로 훈련해 멀티모달 작업을 해결하려고 했지만, 다양한 환경에 적응하는 데 어려움이 있었다고 지적했다.
예를 들어, UI 탐색에 강점을 보이는 '픽스투액트'와 로봇 조작에 특화된 '오픈VLA' 및 'RT-2' 등은 특정 작업에만 뛰어나며, 별도의 훈련 과정을 요구해 일반화 능력이 떨어졌다고 전했다.
또 이런 모델들은 공간적 및 시간적 지능을 통합하는 데 한계가 있어, 복잡한 작업을 자율적으로 처리하는 데 어려움을 겪었다는 설명이다.
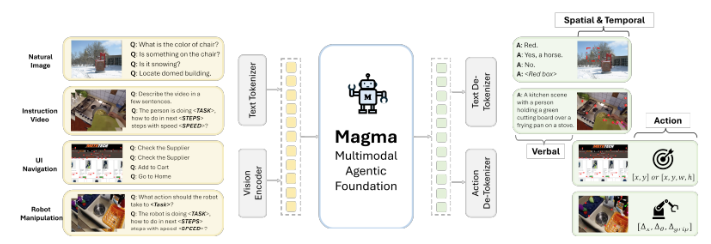
마그마는 이런 단점을 극복하기 위해 멀티모달 이해, 행동 기반, 계획을 결합한 강력한 훈련 방법을 적용했다고 밝혔다.
3900만개의 샘플을 포함한 다양한 데이터셋으로 훈련했다.
특히, 'SoM(Set-of-Mark)'과 'ToM(Trace-of-Mark)'이라는 두가지 새로운 기법을 도입해 UI 환경에서 능력을 강화했다.
로봇 기능을 위해서는 '컨브넷Xt-XXL' 비전 모델을 사용해 이미지를 처리하고, '라마-3-8B' 언어 모델을 통해 텍스트 입력을 처리하는 구조로, 비전-언어 이해와 행동 실행을 매끄럽게 통합했다고 전했다.
또 시클릭, 비전투UI, 에고4D, 섬싱-섬싱 V2, 에픽-키친과 같은 다양한 데이터셋으로 훈련, 행동을 학습하고 향후 행동을 예측하는 능력을 향상했다.

그 결과, 제로 샷 UI 탐색 작업에서 57.2%의 정확도로 요소를 선택, 'GPT-4V-옴니파서'와 '시클릭' 등을 초과했다.
구글 로봇 작업과 브릿지 시뮬레이션에서는 각각 52.3%와 35.4%의 성공률을 달성하며 '오픈VLA'보다 월등한 성과를 보였다.
비디오 질문-답변 테스트인 인텐트QA와 넥스트QA에서 각각 88.6%, 72.9%의 정확도를 기록하며 시간적 정보를 효과적으로 처리하는 능력을 입증했다.
이처럼 마그마는 다양한 UI 탐색과 로봇 작업에서 최고의 결과를 도출, 이런 작업에 특화된 모델보다 우수한 성능을 보였다는 설명이다.
이런 종합적인 능력은 현실 세계에서 로봇이 동작하는 데 큰 도움이 된다. 예를 들어, 로봇이 커피 자동 머신에서 버튼을 누르거나 체스 게임 도중 상대를 이기려면 정확하게 UI를 이해하고 그에 걸맞는 행동을 취해야 하기 때문이다.
연구진은 "마그마는 멀티모달 입력을 해석하고 근거를 제공할 수 있는 최초의 파운데이션 모델로, 목표가 주어지면 계획을 수립하고 이를 달성하기 위한 조치를 실행할 수 있다"라고 강조했다.
박찬 기자 cpark@aitimes.com
