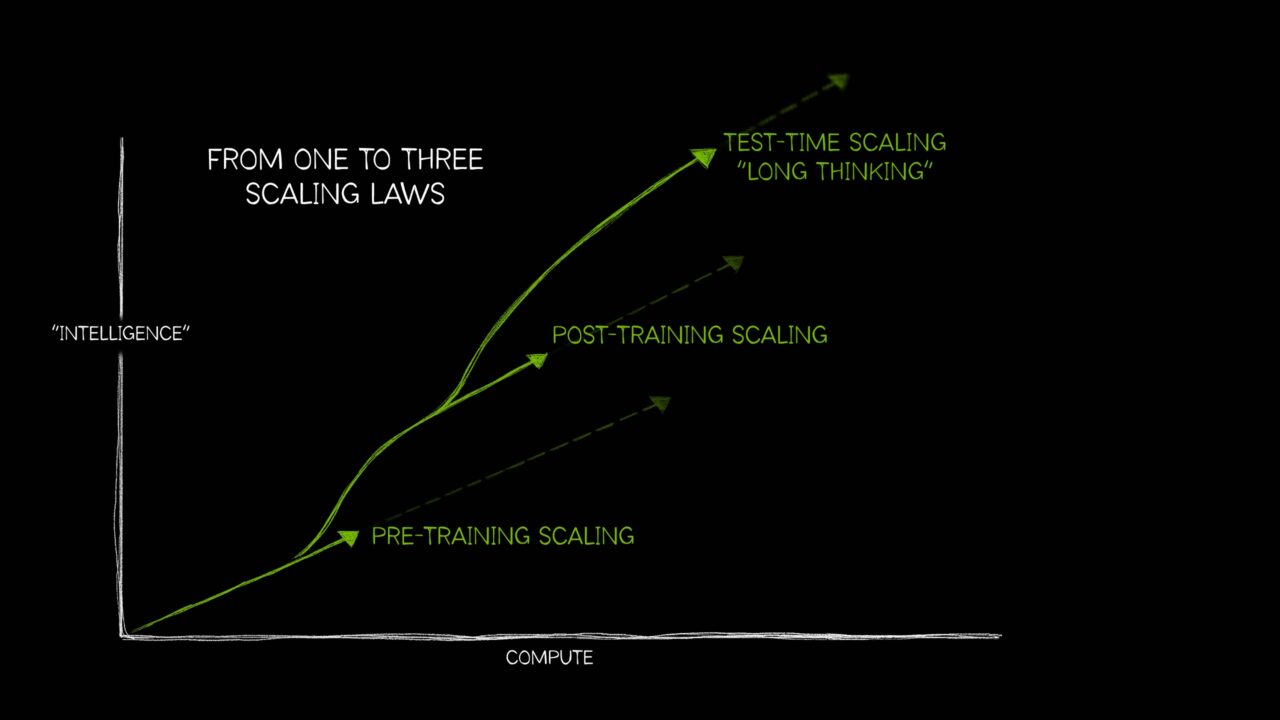
엔비디아가 인공지능(AI) 모델의 사전 훈련보다 사후 훈련과 추론 서비스에 수십~수백배의 컴퓨팅 인프라가 필요하다고 주장했다. 이는 얼마 전 딥시크와 같은 기술 발전에도 불구, GPU 수요가 계속 늘어날 것이라는 젠슨 황 CEO의 말을 구체적인 수치로 설명한 내용이다.
카리 브리스키 엔비디아 AI 제품 관리 부사장은 최근 공식 블로그를 통해 AI 모델의 스케일링 법칙, 즉 성능 확장이 어떤 식으로 이뤄지는지 설명했다.
그는 AI 분야는 오랫동안 한가지 아이디어에 의해 정의됐다고 지적했다. 즉, 사전 훈련에 더 많은 컴퓨팅과 더 많은 학습 데이터, 더 많은 매개변수를 투입하면 더 나은 AI 모델이 나온다는 것이다.
그러나 얼마 전부터는 사전 훈련 외에도 두가지 다른 방식이 AI 성능을 높이는 데 아주 중요해졌다고 밝혔다. 즉, AI의 스케일링(확장) 법칙은 ▲사전 훈련 ▲사후 훈련 그리고 ▲테스트-타임 컴퓨트(추론) 등으로 확대됐다고 설명했다.
우선 사전 훈련도 최근 멀티모달의 중요성이 강조되며, 텍스트뿐만 아니라 이미지와 영상이 학습 데이터에 추가되며 더 많은 리소스가 필요하게 됐다고 전했다.
이어 "사전 훈련을 마친 모델을 다양한 사용 사례에 맞게 조정하려면 사전 훈련보다 약 30배 더 많은 컴퓨팅이 필요할 수 있다"라고 말했다.
사후 훈련에는 미세 조정, 가지치기, 양자화, 증류, 강화 학습(RL) 및 합성데이터 증강 등이 포함되며, 이는 '딥시크-R1'이 보여주듯 모델 성능을 높이는 핵심적인 부분으로 떠올랐다.
젠슨 황 CEO도 대부분 사람이 사후 훈련에 들어가는 리소스가 상당하다는 것을 잊었다고 지적한 바 있다. 브리스키 부사장은 구체적으로 30배라고 지목한 것이다.
마지막 스케일링 법칙 대상인 테스트-타임 컴퓨트는 AI가 생각할 시간을 더 많이 주기 위해 많은 컴퓨팅 리소스를 투입하는 것이다. 난이도가 높은 추론의 경우, 일반적인 챗봇의 답변보다 100배가 넘는 컴퓨팅이 필요하다고 밝혔다. 여기에는 검색 증강 생성(RAG)에 들어가는 리소스도 포함된다.
특히 앞으로 AI 활용에서 추론 모델의 비중이 많이 늘어날 것으로 봤다. 여기에 AI 에이전트 보급이 보편화되면, 컴퓨팅 리소스 소비는 더 커진다고 전했다. 에이전트는 대부분 모델 여러대를 조합하는 경우가 많으며, 단일 쿼리 처리가 아닌 복합적인 계획과 추론, 실행, 검증 등의 과정이 필요하기 때문이다.
결론은 딥시크와 같은 모델의 등장이 사전 훈련과 추론 비용을 낮추는 것은 일부에 불과하며, 이런 고급 모델의 등장으로 개발 과정은 물론 실사용에서 필요한 GPU가 부쩍 늘어난다는 말이다. 그 차이는 기존의 수십, 수백배에 달할 것이라는 예측이다.
마이크로소프트와 구글, 메타, 아마존 등 빅테크도 이미 같은 뜻을 밝히고 AI 투자를 확대하겠다고 밝힌 바 있다. 이들 기업에 GPU를 공급하는 엔비디아는 구체적인 숫자를 제시한 셈이다.

월스트리트 저널도 21일(현지시간) 비슷한 내용의 글을 게재했다. 새롭고 효율적인 AI 모델이 AI의 컴퓨팅 파워 수요를 10분의 1로 줄였지만, 추론 모델이 표준이 되면 컴퓨팅 수요가 100배 증가해 AI의 미래 전력 수요는 10배가 늘어난다는 것이다.
최근 인기를 끄는 '딥 러시치' 같은 기능을 비롯해 의료나 산업 등 멀티모달 기능이 필요한 분야가 늘어나며 컴퓨팅 리소스의 기하급수적 증가는 피할 수 없다는 분석이다.
AI 컴퓨팅 리소스를 제공하는 베이스텐의 튜힌 스리바스타바 CEO는 "한 고객사는 6개월 전에 컴퓨팅 비용을 약 60%나 낮췄지만, 3개월 만에 그들은 처음 소비했던 것보다 더 높은 수준으로 소비하게 됐다"라고 말했다.
임대준 기자 ydj@aitimes.com
- [2월4주] 한달 만에 입 연 젠슨 황 "딥시크 사태는 오해...GPU 수요 증가할 것"
- 아마존도 올해 145.6조 투자...빅테크 4곳 AI 투자, 지난해 국내 정부 예산 3분의 2에 달할 듯
- [2월3일] 딥시크 등장으로 주목받은 '제번스의 역설'이란..."결국 GPU가 중요하다는 말"
- 앤트로픽 CEO "딥시크 개발 비용은 미국과 비슷...결국 인프라가 승부 가를 것"
- 젠슨 황 "AI 인프라, 훈련에서 추론으로 이동...'블랙웰 울트라'가 추론 가속할 것"
- “챗봇 대화에 전기 얼마나 들어갈까”…허깅페이스, AI 소비 전력 계산 도구 공개
- "오픈 소스 모델이 추론 시 토큰 훨씬 더 많이 사용...비용 절감 효과 없어"
