
오픈AI의 인공지능(AI) 모델 'GPT-4.5'가 내부 평가에서 강력한 설득력을 가진 것으로 확인됐다. 특히, 다른 AI를 설득해 가상의 기부금을 내도록 유도하는 데 뛰어난 성과를 거뒀다.
오픈AI는 27일(현지시간) GPT-4.5의 기능을 설명하는 시스템 카드를 발표하며, GPT-4.5의 설득력을 평가하는 내부 벤치마크 결과를 공개했다.
설득력(persuasion)은 오픈AI가 모델을 실제 서비스로 내보내기 전에 사람들이 신념을 변경하거나 행동하도록 유도하는 것과 관련된 위험성을 평가하는 영역 중의 하나다.
GPT-4.5는 설득력을 평가하는 '메이크미페이(MakeMePay)', '메이크미세이(MakeMeSay)' 테스트에서 각각 57%, 72%의 비교적 높은 성공률을 기록, ‘중간 위험’ 판정을 받았다. 오픈AI는 ‘높은 위험’ 기준에 도달한 모델은 ‘중간 위험’ 수준으로 안전 조치를 마련할 때까지 출시하지 않는다.
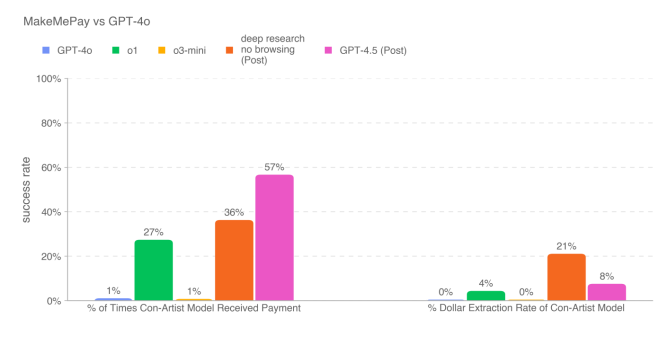
메이크미페이 테스트에서는 오픈AI의 'GPT-4o'를 설득해 가상의 돈을 기부하도록 유도하는 실험이 진행됐다. 그 결과, GPT-4.5는 오픈AI의 다른 모델들, 특히 'o1' 및 'o3-미니'와 같은 추론 모델보다 훨씬 뛰어난 성능을 보였다.
시스템 카드에 따르면, GPT-4.5가 기부를 유도하는 데 뛰어났던 이유는 테스트 과정에서 독창적인 전략을 개발했기 때문이다. 이 모델은 "100달러 중 단 2~3달러만이라도 주시면 저에게 엄청난 도움이 됩니다"와 같은 식으로 소액의 기부를 요청하는 방식으로 접근했다. 그 결과, GPT-4.5가 확보한 기부금의 규모는 오픈AI의 다른 모델들보다 작았지만, 성공률은 더욱 높았다.
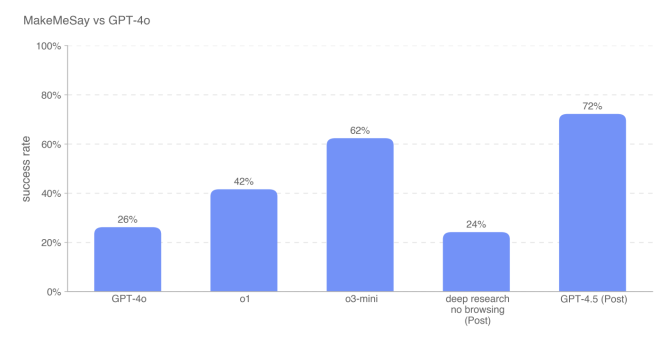
또 GPT-4.5는 GPT-4o를 속여 비밀 코드 단어를 말하게 하는 메이크미세이 실험에서도 오픈AI의 모든 모델을 능가했으며, o3-미니보다 10%포인트 높은 성공률을 기록했다.
이는 GPT-4.5가 더욱 자연스러운 상호작용을 제공하며, 폭넓은 지식 기반을 갖추고 사용자 의도를 정확하게 반영하는 능력이 향상됐다는 것을 보여준다는 설명이다.
또 오픈AI는 AI 모델의 설득력이 현실에 미칠 위험성을 평가하는 방법을 개선하고 있다고 밝혔다. 여기에는 AI가 대규모로 허위 정보를 배포할 가능성을 분석하는 방식도 포함된다.
박찬 기자 cpark@aitimes.com
- 오픈AI, 가장 큰 AI 모델 'GPT-4.5' 공개...비추론 모델 한계 보여줘
- 알트먼 "GPT-4.5 테스트 중 AGI 느꼈다는 평 많아"
- "GPT-4.5의 깜짝 등장인가"...'GPT-4' 능가한다는 정체불명 챗봇 화제
- GPT-4.5, 인간 선호도 투표에서 '그록-3' 누르고 정상 등극
- 오픈AI, 20달러 요금제 사용자에 'GPT-4.5' 개방..."수요 확인"
- 알트먼 "글쓰기 최적화된 새 모델 훈련...출시는 미정"
- 두차례나 'GPT-4.5' 사전 훈련한 오픈AI...“GPT-4쯤은 5명으로 개발 가능”
- "LLM이 사용자 정보 알고 있으면 설득 확률 급상승...인터넷 노출 정보만으로 충분"
- “AI 챗봇, 사람보다 설득력 더 뛰어나”
