딥시크가 추론 모델의 성능을 높일 수 있는 새로운 방식을 선보였다. 강화 학습(RL)을 효율적으로 만드는 '보상 모델(RM)'을 구축했는데, 이를 적용해 곧 출시할 '딥시크-R2'의 성능을 끌어 올렸을 것으로 보인다.
딥시크는 칭화대학교 연구진과 협력, '생성 보상 모델링(GRM)을 위한 추론 시간 스케일링(Inference-Time Scaling for Generalist Reward Modeling)'이라는 논문을 4일 온라인 아카이브에 게재했다.
이 논문은 대형언어모델(LLM)의 효과적인 추론의 핵심으로 알려진 RL에 관한 내용이다. LLM이 RL을 통해 성능을 높이려면 정교한 RM을 만들어내는 것이 중요한데, 이를 효과적으로 구축하는 방법을 설명한 것이다.
특히 연구진은 671B 매개변수를 가진 R1을 효과적으로 훈련하는데 반드시 671B의 RM이 필요하지 않다는 것을 보여줬다.
대신, 27B에 불과한 특화된 RM을 사용하면서 더 많은 추가 컴퓨팅을 사용, 671B 모델에 맞먹는 결과를 얻어내는 데 성공했다고 밝혔다. 즉, RM에도 매개변수의 크기보다 추론이 더 효과적이었다는 말이다.
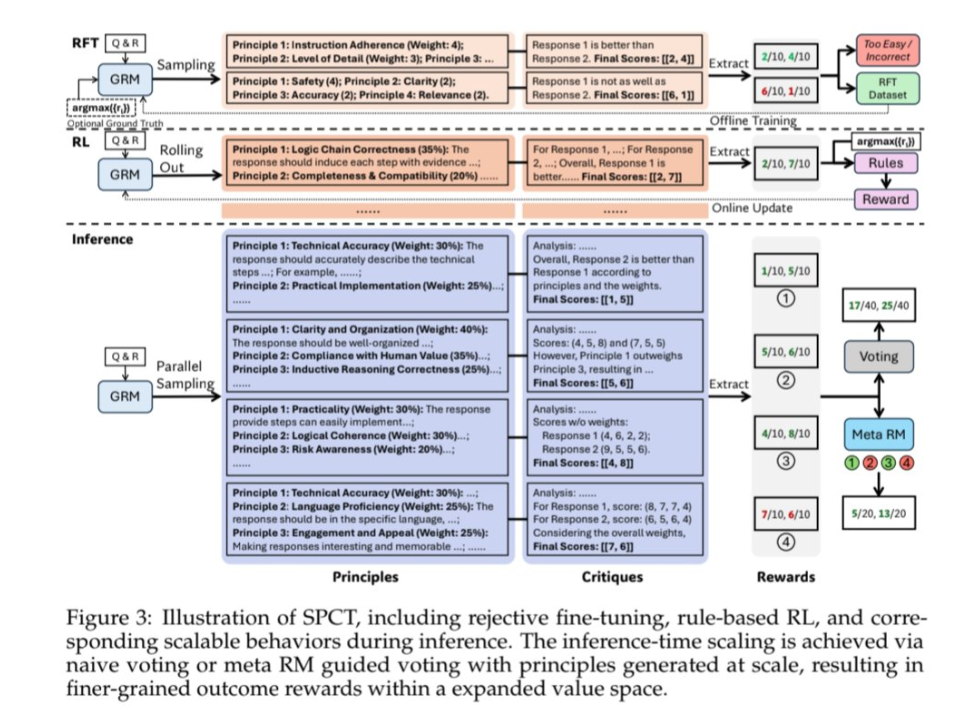
연구진은 RM을 훈련해 각 평가 작업에 맞는 맞춤형 원칙을 생성한 다음, 이에 따라 자세한 비판을 생성하는 'SPCT(Self-Principled Critique Tuning)'이라는 방법을 개발했다. 이를 통해 RM은 평가를 병렬로 실행, 큰 모델보다 더 나은 결과를 낼 수 있었다. 여러 답변을 동시에 생성한 뒤 가장 좋은 것을 골라내는 식이다.
이렇게 구축된 보상 모델이 '딥시크-GRM-27B(DeepSeek-GRM-27B)'이다. GRM은 말 그대로 비판을 통해 좋은 답을 '생성하는' RM을 뜻한다.
따라서 대형 RM을 구축하지 않고도, 개발자들은 27B의 중간 크기 보상 모델을 활용, 다른 모델에 RL을 적용해 추론 성능을 끌어 올릴 수 있게 됐다는 설명이다.
이처럼 딥시크-GRM은 판단(보상)이 핵심으로, 추론(정책)에 초점을 맞춘 R-1의 핵심 기술과는 결이 다르다.
그러나 RM 구축을 위해 컴퓨팅 리소스를 사전훈련에 투자하는 대신, 추론에 사용하는 것이 효과적이라는 것을 밝혔기 때문에 역시 컴퓨팅의 효율에 관한 것으로 볼 수 있다.
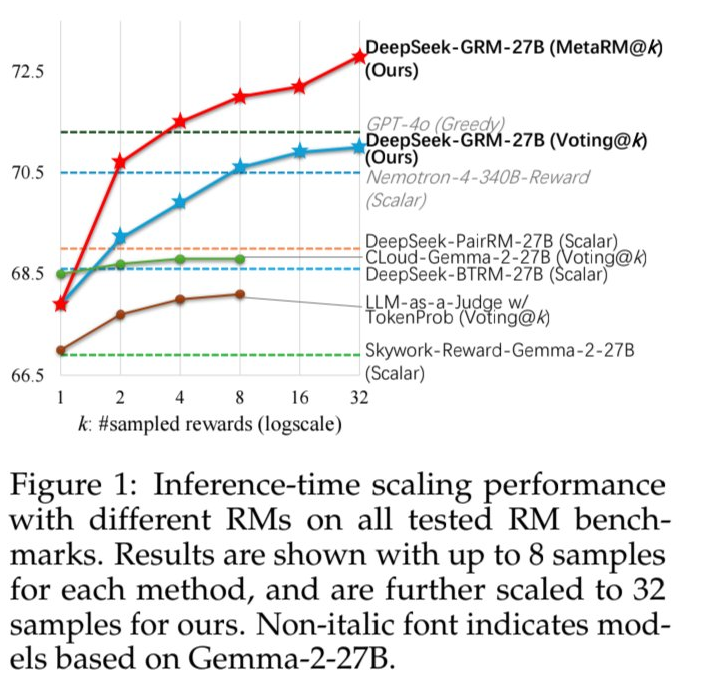
연구진은 "우리는 SPCT가 GRM의 품질과 확장성을 크게 개선해 다양한 RM 벤치마크에서 기존 방법과 모델을 능가하는 것을 발견했다"라고 밝혔다.
딥시크-GRM을 적용한 R1 모델은 RM 벤치마크 성적이 67점대에서 72점대로 뛰어올랐다. 이는 다른 방식을 사용한 모델보다 훨씬 높은 수치다.
또 "딥시크-GRM은 일부 작업에서 과제를 해결하고 있다"라고 덧붙였다. 이는 후속 모델인 R2의 개발에 사용됐다는 점을 의미하는 것으로 보인다.
딥시크는 이 모델을 곧 오픈 소스로 출시할 것이라고 예고했다.
워낙 전문적인 내용이라 논문이 발표되자 AI 커뮤니티에서는 무슨 내용인지를 파악하는 데 집중했다. 그 가운데 일부 전문가들은 딥시크가 추론 확장성을 계속 넓혀가고 있다고 칭찬했다.
특히, 이번 논문의 등장에 따라 업계는 1~2주 내로 R2가 출시될 것을 기정사실화하고 있다.
또 딥시크는 지난달 25일에는 오픈AI의 'GPT-4.5'나 앤트로픽의 '클로드 3.7 소네트' 등 최근 등장한 비추론 모델과 맞먹는 성능을 가진 '딥시크-V3'의 업그레이드 버전을 오픈 소스로 출시해 눈길을 모았다.
임대준 기자 ydj@aitimes.com
