시각 인공지능(AI) 전문 한국딥러닝(대표 김지현)은 영상언어모델(VLM) 기반 광학 문자 인식(OCR) 솔루션 '딥 OCR+'을 출시했다고 10일 밝혔다.
딥 OCR+은 기존 OCR을 넘어, 문서의 의미와 구조를 자동으로 분석하고 핵심 정보를 추출할 수 있도록 설계한 것이 특징이다. 한국딥러닝이 4억장 이상의 텍스트 및 이미지 문서를 학습한 VLM을 기반으로 개발했다.
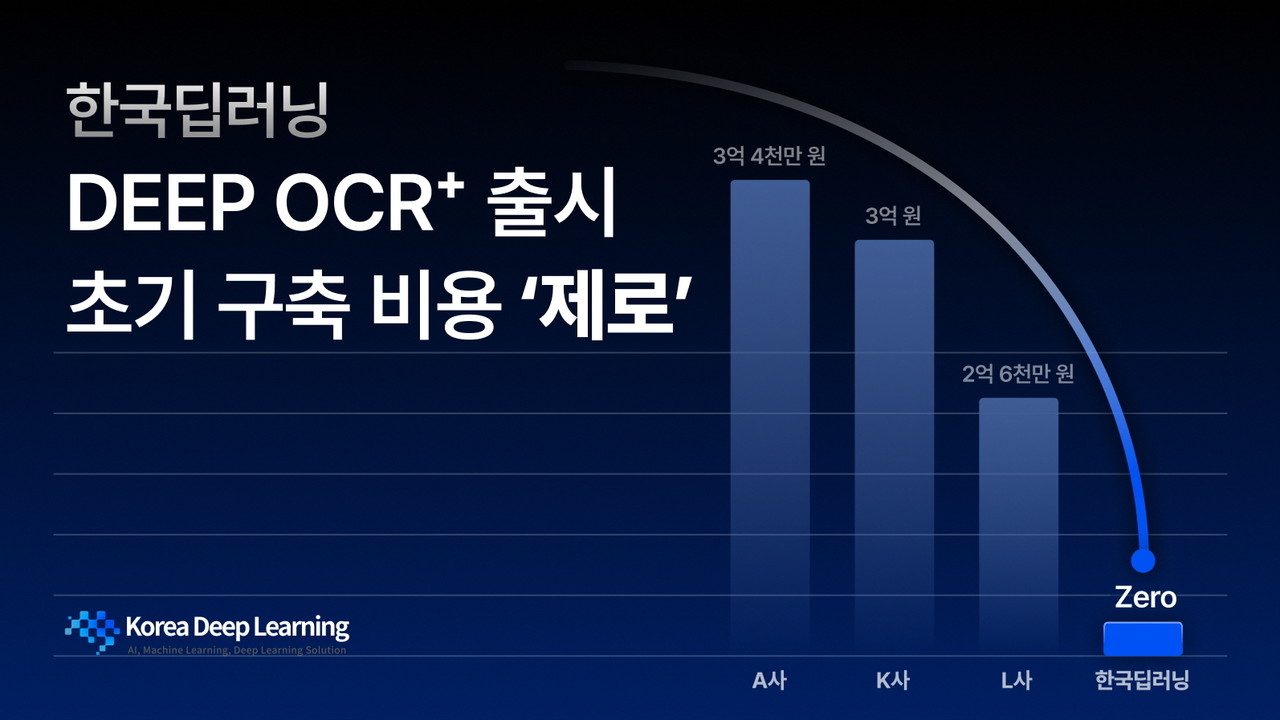
별도 데이터 수집이나 라벨링 없이도 다양한 문서 유형을 즉시 처리할 수 있어 초기 도입 부담이 거의 없다고 강조했다. 최소한의 데이터만으로도 최적의 정확도를 보장한다고 덧붙였다.
기존 OCR 솔루션은 문서 이미지에서 텍스트를 추출하는 데 중점을 둬, 표나 조항, 문단 등 복잡한 문서 구조를 인식하는 데 제약이 있었다고 지적했다. 계약서나 청구서처럼 포맷이 일정하지 않은 문서의 경우, 문서마다 별도 설계와 라벨링이 필요해 도입과 유지 비용도 높았다는 설명이다.
하지만 딥 OCR+는 특정 포맷에 의존하지 않고도 문서의 전체 구조와 의미를 이해할 수 있어 비정형화된 문서도 즉시 처리 가능하다고 설명했다. 이미지와 텍스트를 동시에 처리할 수 있는 VLM 기술을 통해, 사용자가 문서를 업로드하면 별도 학습 없이도 주요 정보를 구조화된 형태로 정리해 준다고 전했다.
구축형 외에도 서비스형소프트웨어(SaaS) 및 API 형태로도 제공한다. 평균 도입 기간은 2주 내외다.
김지현 한국딥러닝 대표는 “딥 OCR+은 금융, 법률, 공공 등 다양한 분야에서 도입 가능성이 검토되고 있으며, 일부 대형 프로젝트에서는 이미 시범 적용을 진행 중”이라며 “최근 단순 인식 기술을 넘어 문서 내 의미와 맥락까지 파악할 수 있는 AI 기술에 대한 관심이 높아지고 있으며 이번 신제품은 문서 처리 기술의 진화를 보여주는 사례가 될 것”이라고 말했다.
장세민 기자 semim99@aitimes.com
