트릴리온랩스(대표 신재민)가 대형언어모델( LLM) '트리(Tri)'를 공개했다. 자체 개발한 언어 확장 구조를 통해, 다국어와 산업 현장에 강하다는 점을 강조했다.
트릴리온랩스는 23일 허깅페이스를 통해 매개변수 7B와 21B로 구성된 트리 라인업을 오픈 소스로 출시했다.
이중 7B 모델은 지난 3월 공개된 '7B-프리뷰'의 업데이트 버전이다. 또 앞으로 풀 사이즈인 '트리-70B'를 출시, LLM 포트폴리오를 완성할 계획이다.
추론 성능 향상을 위해 '생각의 사슬(CoT)' 구조를 채택했으며, GPU 1대에서도 작동할 수 있는 효율성을 특징으로 들었다.
트릴리온랩스는 국내 시장은 물론, 아시아권을 중심으로 사업을 확장하려는 의도로 트리를 개발했다. 따라서 자체 개발한 '언어 간 상호학습 시스템(XLDA)'을 적용, 다국어 성능을 높였다고 전했다.
XLDAS는 자원이 풍부한 영어 지식을 한국와 일본어, 자원이 부족한 언어로 전이할 수 있는 구조다. 데이터가 부족한 산업 분야에서도 LLM 성능을 끌어올릴 수 있게 된다.
트릴리온랩스 관계자는 "학습 데이터에서 한국어의 비중을 점점 줄여가면서도 높은 한국어 성능을 달성하는 것이 목표"라고 덧붙였다.
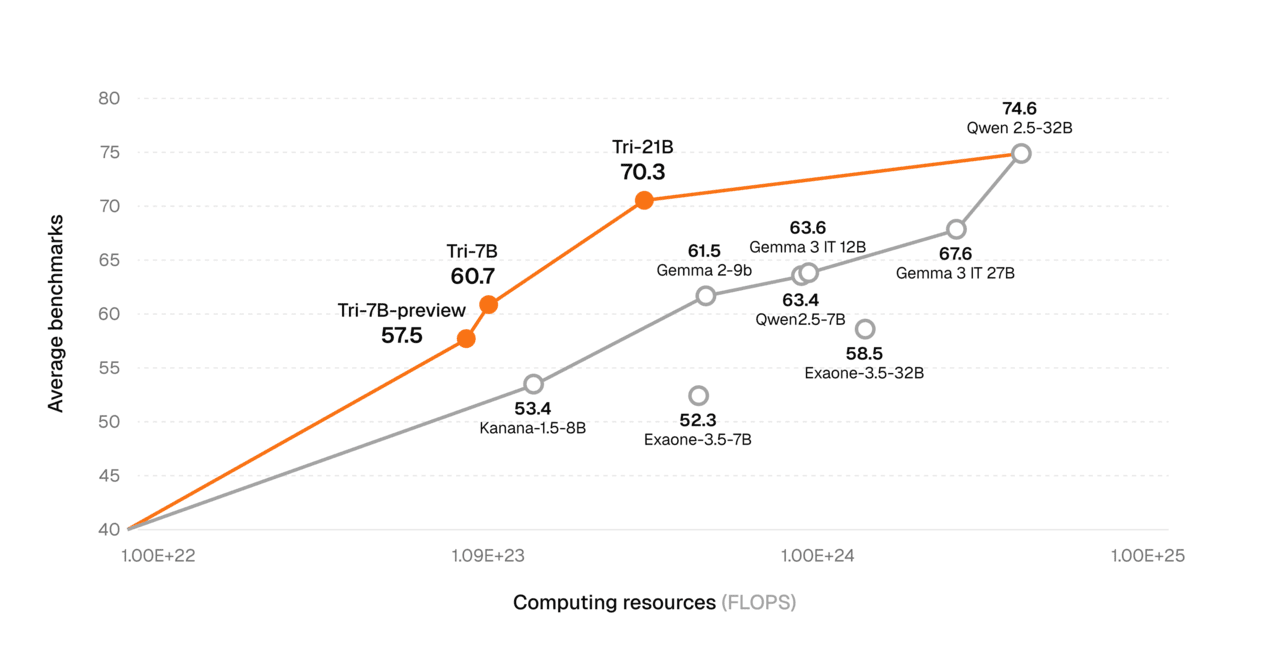
또 모델 학습에 든 비용을 크게 줄였다고 강조했다. 지난 4월22일 공개한 기술보고서에 따르면, 7B 모델을 2조 토큰으로 학습하는데 약 14만8000달러(한화 약 2억4300만원)의 비용을 지출했다.
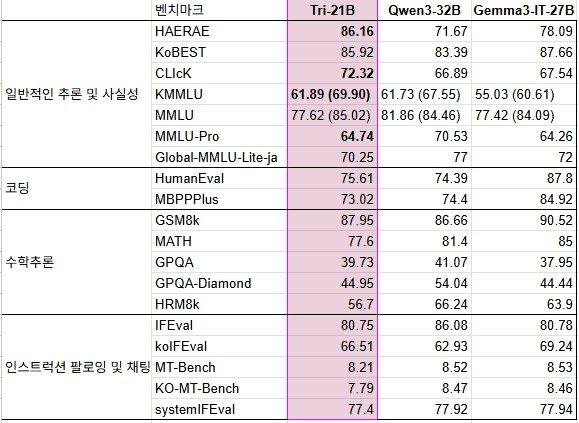
트릴리온-21B는 한국 문화 이해도를 측정하는 '해례(Hae-Rae)'에서 86.16점, 한국어 지식과 추론능력(KMMLU)에서 61.89점(CoT 적용 시 69.90)을 기록했다.
코딩, 수학 추론, 지시이행 및 채팅 분야의 벤치마크에서는 알리바바의 '큐원 3-32 B', 구글의 '젬마 3(27B)' 등과 유사한 성능을 보였다.
한편, 지난해 4월 설립된 트릴리온랩스는 네이버 연구원 출신 신재민 대표가 이끌고 있다. 신 대표가 자연어처리(NLP)와 합성 데이터 전문가로 알려져, 업계에서는 합성 데이터를 사용할 것으로 예상했다.
그러나 합성 데이터 대신 XLDA를 고안, 다국어와 여러 산업군에 대응할 수 있는 파운데이션 모델을 출시했다.
트릴리온랩스 관계자는 "백본(Back bone)부터 설계된 범용 모델이기 때문에 사용자의 목적에 따라 커스터마이징해서 사용할 수 있다"라고 전했다. 연구 목적과 상업적 이용이 모두 가능한 오픈 소스 라이선스로 공개됐다.
신재민 대표는 “트리-21B는 플라이휠 구조를 통해 70B급 대형 모델의 성능을 21B에 효과적으로 전이, 모델 사이즈와 비용, 성능 간 균형에서 현존하는 가장 이상적인 구조를 구현했다”라고 설명했다.
“또 이번 모델처럼 처음부터 사전학습으로 개발한 고성능 LLM을 통해 비용 효율성과 성능 개선을 빠르게 달성, 국내 AI 기술의 완성도를 높이겠다”라고 말했다.
한편, 트릴리온랩스는 의료 AI 전문 루닛과 컨소시엄을 구성, '국가 AI 파운데이션 모델 개발 사업'에 응모했다.
박수빈 기자 sbin08@aitimes.com
