지금까지 글을 통해 데이터 종류와 데이터를 기반으로 한 문제 및 해결 방법을 살폈다. 이제부터 조금 더 실제적인 분석에 대한 설명을 진행하고자 한다. 실제 데이터 분석에 앞서 데이터 분포나 특성을 살피는 과정이 필요한데, 이 과정을 '데이터 탐색 분석(Exploratory Data Analysis, EDA)'이라 한다. EDA는 주로 데이터의 기초 통곗값과 여러 형태의 그래프를 활용한 시각화로 진행된다.

데이터 탐색
데이터 분석에 있어 가장 중요한 부분은 데이터 전처리와 피처 엔지니어링이라고 할 수 있다. EDA 과정으로 데이터를 정확하게 이해하고 피처 각각의 특징에 맞도록 적절하게 전처리 및 피처 엔지니어링을 진행한다면 우수한 성능을 얻을 수 있을 것이다. 또 컴퓨터는 문자로 된 데이터를 계산할 수 없기 때문에 적당한 형태의 숫자로 변환해주는 과정도 반드시 필요하다.
EDA과정은 데이터 형식과 크기, 결측값, 이상값, 기초 통곗값을 살펴보고 시각화하는 것으로 시작한다. 이번 글은 구글 코랩(https://colab.research.google.com)에서 Python과 pandas, numpy 라이브러리를 사용해 타이타닉 공개 데이터셋(http://biostat.mc.vanderbilt.edu/DataSets)을 분석하며 설명해 보겠다. 예시와 같이 데이터의 크기가 적은 경우 마이크로소프트(MS) 엑셀로도 충분하며 용도에 맞게 Python, R, MS엑셀 혹은 그 외의 도구를 사용하면 된다.
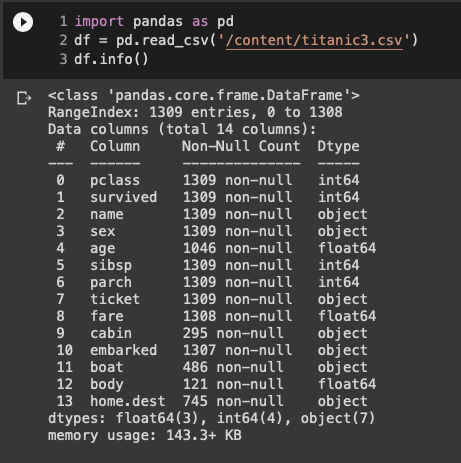
먼저 다운로드 받은 csv데이터를 불러와 데이터셋의 기본 정보를 살펴보자. 가장 먼저 확인할 수 있는 정보는 데이터셋의 크기와 형식으로 1309개의 행과 14개의 열을 갖고 있으며, 변수에 따라 object형태(여기서는 문자)와 int(정수), float(소수점을 포함한 숫자)형식의 데이터를 갖고 있는 것을 알 수 있다. 각 열에 대한 정보는 변수의 이름으로 어느 정도 추측이 가능하며, 변수에 대한 자세한 설명(http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic3info.txt)을 참고하자.
그 다음으로 확인할 수 있는 정보는 'Non-Null Count'로 데이터의 열에 비어있는 데이터의 개수를 짐작해볼 수 있다. 예를 들어 name의 경우 1309명 모두의 데이터를 갖고 있는 반면 age의 경우 1046명에 대한 정보만을 갖고 있는 것을 확인할 수 있다.
Null(비어있는 값) 이나 N/A(Not Applicable, 정보없음), Nan(Not A Number)이 데이터에 존재하는 경우 가장 쉽게는 평균이나 최빈값, 중간값 등으로 채울 수 있고, 다른 변수를 통해 추측할 수 있는 경우 kNN imputation과 같은 머신러닝 기법을 활용해 채우기도 한다.
값이 없는 데이터가 너무 많은 변수의 경우 변수 자체를 삭제(drop)하기도 한다. 이 같은 과정은 단순히 비어있는 값을 채우거나 삭제한다는 점에서 전처리라고 할 수 있겠으나 얼마나 정교하게 처리하는지에 따라 모델 성능에 영향을 줄 수 있다는 점에서 피처 엔지니어링 과정이라 해도 좋을 것이다.
다음으로 실제 처음 5개의 행을 확인해 데이터셋이 어떤 형태로 값을 갖고 있는지 살펴보자. 각 변수들에 존재하는 데이터를 확인하면 변수들을 어떻게 처리해야할지 아이디어를 얻을 수 있을 것이다. 또 데이터가 범주형(categorical)인지 수치형(numerical)인지, 범주형이라면 순서형(ordinal)인지 명목형(nominal)인지, 수치형이라면 연속형(continuous)인지 이산형(discrete)인지도 확인할 수 있다. 이 과정은 추후 피처 엔지니어링에서 변수를 어떻게 처리할지에 대한 중요한 정보를 제공한다.

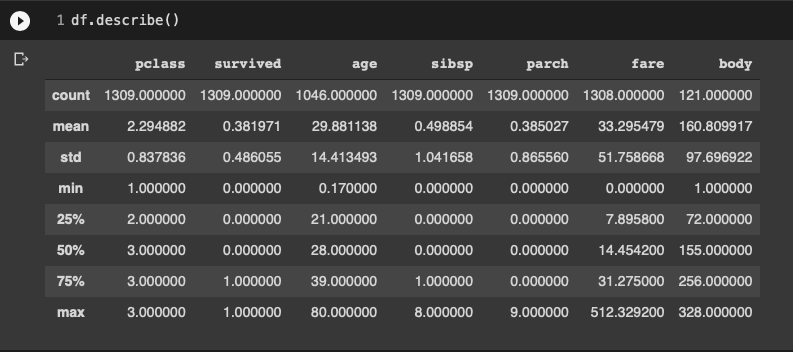
다음은 수치형 데이터를 갖고 있는 변수들의 기초 통곗값을 확인한 결과다. age 변수를 보면 희생자가 0.17세부터 80세까지 있었다는 것을 알 수 있다. 또 sibsp(siblings and spouse, 동승한 형제자매와 배우자 수)와 parch(parent and children)을 통해 많은 가족이 함께 승선한 경우도 있었다는 것을 알 수 있다. 하지만, 지금까지의 정보만으로 실제 데이터 분포나 이상값(outlier)이 있는지 확인하기 어렵다.
데이터 시각화
가장 먼저 데이터 전체를 히스토그램으로 표시해 봤다. 하지만 원칙적으로는 막대그래프는 범주형 데이터를 표시하는 데 유용하며 히스토그램은 순서형 데이터를 표시하는데 유용하다는 것을 이해하고 사용해야 한다.
예를 들어, 타이타닉 데이터셋의 목적변수인 survived 변수의 경우 0(사망), 1(생존)으로 표시되는데 이때 0과 1은 숫자의 크기가 의미있는 것이 아니라 범주를 나누기에 막대그래프로 표현하는 것이 올바른 방식이다. 반면 age의 경우 1부터 숫자가 증가함에 따라 나이가 많아진다는 의미를 갖기 때문에 히스토그램으로 표현하는게 올바른 표현 방식이며, 이때 x축의 구간 개수를 조절해가며 데이터의 형태를 확인할 수 있다.
편의를 위해 히스토그램으로 표현한 그래프를 해석해 보면 데이터의 분포도 쉽게 살펴볼 수 있는데 pclass를 보면 대다수의 승객들이 3등급 객실을 이용한 것을 확인할 수 있다.
Survived 변수의 분포를 보면 사망자(0)가 생존자(1) 보다 많다는 사실도 알 수 있다. age 변수의 경우 (왼쪽으로 치우친) 정규분포의 형태를 띄며 대부분 20-30대 승객이 많았던 것을 알 수 있다.
sibsp와 parch에서는 대부분의 승객 1-2명이 이용했으며 8명 이상의 가족과 여행한 경우도 있다는 점을 짐작할 수 있다. fare 변수를 통해서 대부분 요금이 200(파운드 혹은 달러) 미만이었다는 것을 확인할 수 있다.
데이터셋이 이미 어느 정도 정제됐기 때문에 모든 변수에서 이상값이 나타나지는 않는 것으로 보인다. 만약 이상값을 갖는 경우 그래프 범위가 끝쪽으로 길게 늘어나고 맨 끝 데이터가 일부 표시되는 형태로 나타난다. 이를 통해 이상치가 있는지를 확인할 수 있다.
예를 들어, age 변수에 200살이 있었다면 0~80까지 데이터가 존재하다가 중간 데이터는 없고 200세에 데이터가 존재하는 경우다. 이는 현실적으로 잘못된 데이터일 확률이 많다.
하지만 모두 그런 것은 아니다. 만약 소득(연봉)이라는 변수에 1000억이라는 데이터가 있었다면 이는 잘못됐다고 할 수 있을까? 고민해볼 문제다. 이 부분도 피처 엔지니어링 부분에서 좀 더 다뤄볼 예정이다.
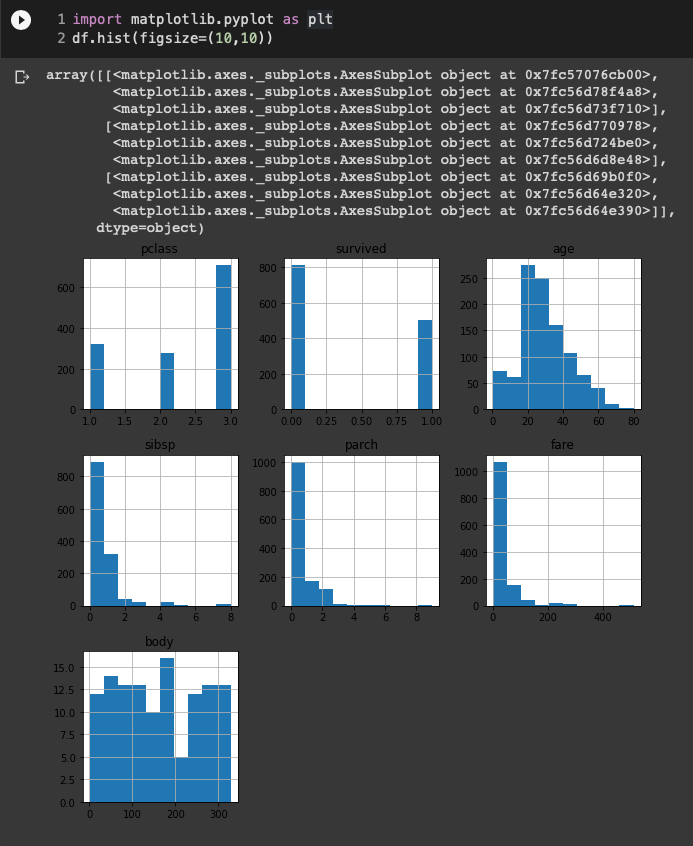
다음으로 수치형 데이터를 갖고 있는 상관관계를 피어슨 상관계수(person correlation coefficient)와 히트맵(heat map)으로 확인해보자.
피어슨 상관관계는 한 변수가 증가할 때 다른 변수도 증가하면 계수가 + 값을 갖으며 1인 경우 똑같은 비율로 증가한다는 의미다. – 값의 경우 반대로 해석하면 되고 0인 경우 변수 사이에 상관관계가 없다고 이해하면 된다.
우선 목적변수 survived와 어떤 변수가 상관관계가 높은지 살펴보면 양의 상관계수가 0.244265로 fare와 가장 큰 양의 상관관계를 갖는 것을 알 수 있으며 pclass와 -0.312469의 가장 큰 음의 상관관계를 갖는 것을 알 수 있다.
다시 말하면 높은 요금(fare)을 지불하고 좋은 등급(pclass)에 탑승한 승객이 생존(survived)할 확률이 높았다고 해석해 볼 수 있다. 안타까운 분석 결과이지만 너무 실망할 필요는 없다. 지금 분석한 데이터셋은 피처 전처리와 엔지니어링을 거치지 않은 데이터며, 모든 변수를 처리 후 분석하면 이보다는 희망적인 결과를 볼 수 있을 것이다.
상관관계도 위에서와 마찬가지로 숫자만으로 표현된 경우 눈에 잘 들어오지 않는다. 따라서 이를 히트맵으로 표현해보면 흰색과 검정색 영역을 구성하는 상관관계가 높은 변수들을 보다 쉽게 파악할 수 있다.
지금까지 공개 데이터셋을 활용해 데이터를 탐색하는 과정을 살펴봤다. 여기서 모두 다루지 못했지만 데이터를 사분위를 활용해 중간값과 사분위, 이상값을 한번에 표시할 수 있는 상자 그래프(box plot), 두 변수 사이에 데이터 분포를 확인하기 쉬운 산점도(scatter plot) 등도 데이터 탐색에 매우 유용한 그래프다.
데이터 탐색 과정은 데이터를 이해하고 전처리 및 피처 엔지니어링을 진행하기 위해 진행하지만 실제 전처리 및 피처 엔지니어링을 진행한 후에도 반복적으로 데이터를 확인하기 위한 목적으로 진행한다.
또 시각화는 모델 성능을 평가하는 과정과 결과를 전달하는 과정에서도 사용되는 부분이다. 그래프를 표현하고자 하는 대로 표현할 수 있는 능력을 기르는 것도 매우 중요하다.
다음 시간에는 오늘 분석한 EDA 결과를 활용해 실제 데이터 피처 유형에 맞게 피처 엔지니어링을 진행하는 방법에 대해 다뤄 본다.
박정현 칼럼니스트는 서울대 EPM연구원(공학전문대학원 엔지니어링 프로젝트 매니지먼트(EPM) 연구실)이며, 머신러닝 스타트업을 창업한 바 있다.
[관련 기사][박정현의 데이터사이언스 시작하기] ③ 데이터 분석 문제
