캐나다 스타트업 코히어가 텍스트의 의미를 100개 이상의 언어로 이해하는 '다국어 텍스트 이해 인공지능(AI) 모델'을 업계 최초로 출시했다고 벤처비트가 12일(현지시간) 보도했다.
인간은 7100개 이상의 언어를 구사하지만, 대부분의 언어 AI 모델은 영어만 지원한다. 이로 인해 다국어를 사용해 제품이나 프로젝트를 구축하는 것이 매우 어렵다.
다국어 텍스트 이해 모델은 여러 언어의 텍스트 데이터에서 통찰력을 얻을 수 있는 대규모 언어 모델(LLM)이다.
지난 7월 출시된 오픈소스 ‘블룸’을 비롯한 다국어 언어 모델이 다국어 텍스트 생성에 초점을 맞춘 반면 코히어의 다국어 모델은 다양한 자연어 사용 사례를 지원하기 위해 다국어를 이해하는 데 중점을 둔다.
코히어의 AI 모델은 텍스트의 의미를 숫자 형식으로 표현하는 '다국어 임베딩'을 통해 텍스트 간의 유사성을 비교하고 유사한 내용에 대해 이야기하고 있는지 파악할 수 있다. 텍스트를 '시맨틱(의미론적) 벡터 공간'에 매핑, 유사한 의미를 가진 텍스트들을 근접하게 배치한다.
예를 들어 검색 쿼리를 이 벡터 공간에 매핑해 근처에 있는 관련 문서를 찾을 수 있다. 이 방법은 종종 키워드 검색보다 몇 배 더 나은 검색 결과를 산출한다.

다국어 모델을 교육하려면 ‘질문-답변’ 쌍으로 구성된 학습 데이터가 수억개 필요하다. 코히어는 언어별 또는 국가별 뉘앙스를 포착할 수 있도록 수백개의 언어로 된 수만개의 웹 사이트에서 거의 14억개의 질문-답변 쌍 데이터셋을 수집했다.
코히어 모델은 단일 언어 내에서뿐만 아니라 여러 언어에서 의미론적으로 검색하는 데 사용할 수 있다. 다른 언어를 처리하기 위해 별도의 토크나이저와 색인이 필요한 키워드 검색과 달리, 검색을 위한 다국어 모델은 언어별 처리가 필요하지 않다. 단일 색인 내의 단일 모델에서 모든 작업을 수행할 수 있다.
기존의 키워드 검색은 사용자의 검색 의도와 일치하는 관련 정보를 찾지 못하는 경우가 많다. 예를 들어 ‘미국의 수도는 어디입니까(What is the capital of the United States)’라는 검색어에 대해 다음과 같은 결과를 얻었다.
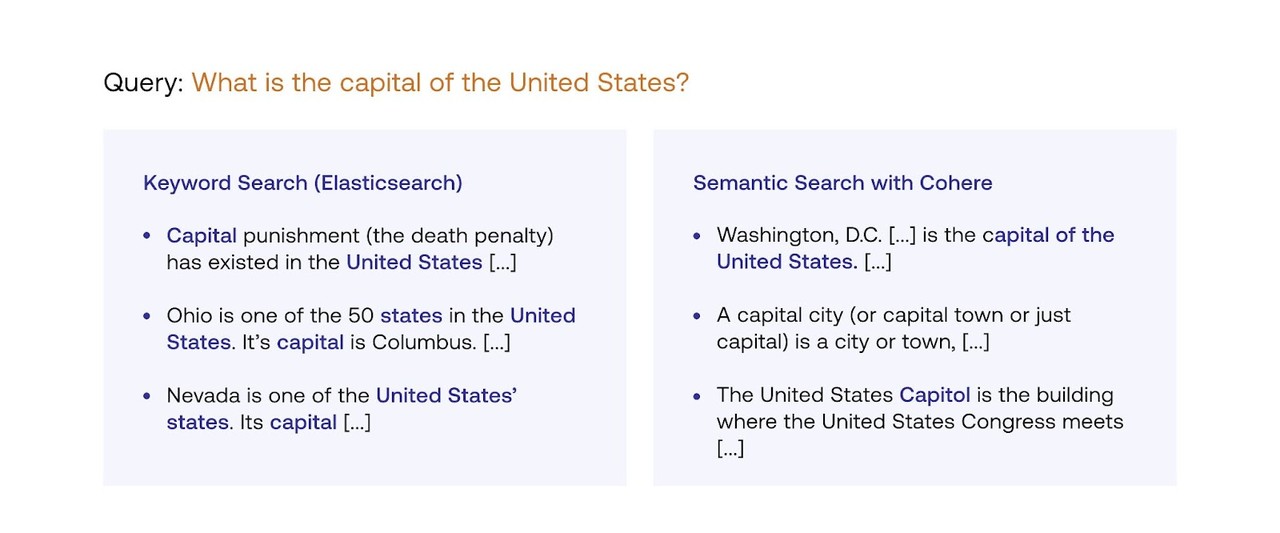
엘라스틱리서치(키워드 검색) 결과는 수도(capital), 연방(United) 및 주(States)라는 단어의 많은 인스턴스가 겹치는 '사형'에 관한 글을 최상위 순위로 보여준다. 2위와 3위의 결과도 그다지 좋지 않은데, 오하이오와 네바다가 미 연방 소속의 주로 수도는 어디라는 내용이다.
반면 코히어의 다국어 모델로 구동되는 시맨틱 검색을 사용하면 검색 품질을 크게 향상할 수 있다. 워싱턴 DC에 대한 관련 글이 검색 결과의 최상위에 배치된다.
시맨틱 검색은 동일한 언어로 된 쿼리와 문서에 국한되지 않고 여러 언어에서도 작동한다. 예를 들어 똑같은 질문을 아랍어 ‘ما هي عاصمة الولايات المتحدة؟’로 입력하면 동일한 결과를 얻을 수 있지만, 키워드 검색으로는 관련 문서를 검색할 수 없다.

아이폰과 같은 제품이 출시되면 전 세계 수만명의 사용자가 전자상거래 사이트, 소셜 미디어, 블로그 등에 사용후기를 자신의 언어로 게시한다. 이런 리뷰에서 인사이트를 추출하면 회사는 시장에 신속하게 대응하고 고객 기반을 더 잘 이해하며 제품 로드맵을 개선할 수 있다.
그러나 콘텐츠 집계를 위한 이전 방법은 영어에만 적합했으며 여러 언어의 패턴을 확인하거나 다른 시장의 피드백을 비교할 수 없었다.

코히어의 다국어 모델은 서로 다른 언어의 텍스트를 동일한 벡터 공간에 매핑해 사용자가 언어 전반에 걸쳐 통찰력을 얻고 특정 시장에 대한 패턴을 찾을 수 있도록 한다.
또 코히어 다국어 모델을 사용하면 작성된 언어에 관계없이 유해한 텍스트를 식별할 수 있다.
추천 영화 엔진을 구축하고 검색 쿼리 또는 콘텐츠 소스에 사용된 언어에 관계없이 관련 결과를 얻는 데 사용되는 코히어의 다국어 모델(영상=코히어)
박찬 위원 cpark@aitimes.com
