
구글이 텍스트 설명으로 모든 장르의 음악을 생성할 수 있는 인공지능(AI) 모델인 ‘뮤직LM(MusicLM)’를 개발했다.
하지만 저작권 문제를 이유로 아직 출시 계획은 세우지 않고 있다고 테크크런치가 28일(현지시간) 보도했다.
이처럼 음악을 생성해주는 AI가 나온 것은 이번이 처음은 아니다. '리퓨전(Riffusion)'을 비롯해 구글의 ‘오디오LM(AudioLM)', 오픈AI의 '쥬크박스(Jukebox)', 메타의 ‘오디오젠(AudioGen)’ 등 이미 다양한 모델이 나와있다.
그러나 이들 모델은 모두 기술적 한계와 제한된 학습 데이터로 인해 설득력을 지니지 못했다. 구성이 복잡하거나 충실도가 높은 곡을 제작하는데는 어려움이 있다.
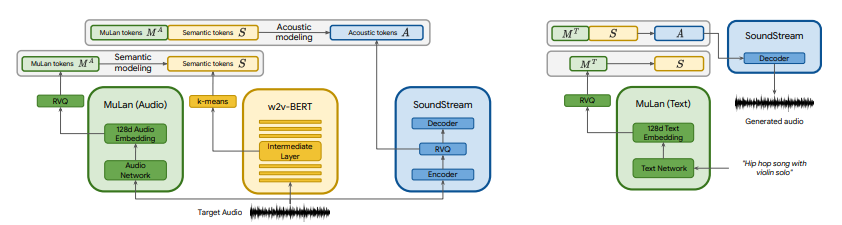
뮤직LM은 이같은 한계를 처음으로 극복할 수 있는 모델로 보인다. 추상적인 개념을 사용해 다양한 장르의 음악 트랙을 자동으로 생성할 수 있다. 댄스 음악과 레게의 하이브리드를 생성하는 것도 가능하다. 허밍, 휘파람은 물론 그림 설명을 기반으로도 멜로디를 생성할 수 있다.
또 스토리 모드로 여러 설명을 함께 연결해 DJ 세트 또는 사운드트랙을 생성하거나 이미지와 설명을 읽고 이미지와 동기화되는 음악을 만드는 일도 가능하다.
일부 작곡은 이상하게 들리거나 이해할 수 없는 보컬이 들어갈 수 있지만 일단은 그럴듯한 음악을 생성한다는 평가다.
다만 구글은 생성된 음악의 약 1%가 학습에 사용된 곡에서 직접 복제됐다고 털어놓았다. 아직 뮤직LM 출시계획을 세우지 못하고 있는 원인으로 보인다.
박찬 위원 cpark@aitimes.com
- 텍스트에서 음악 생성하는 인공지능(AI) '리퓨전'
- 음악에 맞춰 춤추는 인공지능...댄스 생성 AI 등장
- 'AI 창작'에 진심인 구글...비디오·글·음악 생성기 동시 공개
- 구글, '챗GPT' 대항마로 '람다' 기반 새로운 챗봇 테스트
- '목소리 딥페이크'를 막는 법...음성 워터마크 등장했다
- 구글, 챗GPT 경쟁자 '바드' 정식 공개..."테스트 거쳐 몇 주내 일반 공개"
- 음반업계도 생성 AI에 저작권 침해 경고
- 메타, 오픈 소스 AI 음악 생성기 '뮤직젠' 공개
- 구글, 현악기 연주하는 '바이올라 더 버드' 공개
- 메타, 음악·오디오 생성 AI ‘오디오크래프트’ 오픈소스로 공개
- 구글, 최고 성능 음악 생성 AI 개발하고도 저작권 문제로 프로젝트 중단
