
인공지능(AI) 에이전트에 대한 새로운 벤치마크 제안이 등장했다. 연구진은 기존 AI 모델 벤치마크로는 에이전트 성능 측정이 어려우며, 특히 '비용'이라는 중요 변수를 감안해야 한다고 주장했다.
마크테크포스트와 벤처비트는 6일(현지시간) 프린스턴대학교 연구진이 현재 활용 중인 AI 에이전트 벤치마크의 문제점을 지적하고 새로운 평가 방식을 제안한 논문을 발표했다고 보도했다.
연구진은 "AI 에이전트는 흥미로운 새로운 연구 방향이며, 에이전트 개발은 벤치마크에 의해 주도된다"라며 "현재 에이전트 벤치마크와 평가 관행은 실제 애플리케이션 구축 시 문제가 될 몇가지 단점을 보여준다"라고 지적했다.
즉, 에이전트 벤치마킹에는 고유한 과제가 따르며, 기존 모델 벤치마킹 방식으로는 평가할 수 없다는 내용이다.
우선 비용 문제를 간과하는 것이 문제라고 지적했다. AI 에이전트는 복합적인 작업을 처리하기 때문에 같은 쿼리라고 해도 단일 LLM보다 구동 비용이 훨씬 더 비쌀 수 있다.
하지만 현재 개발 중인 에이전트는 이런 점보다 정확도를 높이는 데 집중하고 있다. 따라서 일부 시스템은 여러 모델을 동시에 실행하고 투표나 비교 도구 등을 통해 최상의 답을 선택하는 방식을 채택하고 있다.
연구진은 수백, 수천개의 응답을 비교하면 정확도가 높아질 수 있지만, 상당한 계산 비용이 발생한다고 밝혔다. 정확도를 극대화하는 연구 환경에서는 큰 문제가 안 될지 몰라도, 실제 응용 환경에서는 문제가 된다는 내용이다.
그렇지 않으면 개발자들은 단순히 리더보드에서 좋은 성적을 거두기 위해 엄청난 비용이 드는 무용지물을 만들 수 있다고 강조했다.
이에 따라 평가 결과와 추론 비용의 상관관계를 그래프화, 적절한 균형점을 찾는 것이 중요하다고 제안했다. 특히 "어떤 경우는 정확도를 어느 이상 조금만 올리려고 해도 비용이 수십배 늘어났다"라며 "그렇다고 최적의 성능을 보인 것도 아니다"라고 밝혔다.
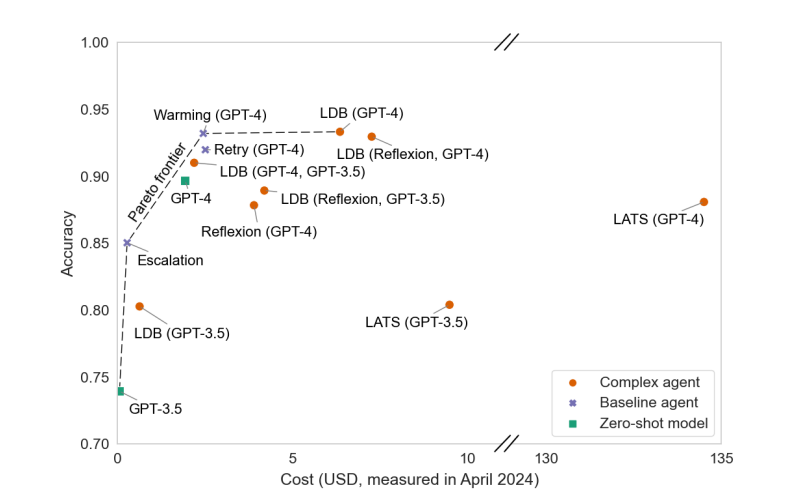
그 예로 인기 있는 벤치마크인 '핫팟QA(HotpotQA)'에서 비용-성능 최적화를 테스트, 최적의 균형을 이루는 방법을 선보였다.
또 연구진은 연구 목적으로 모델을 평가하는 것과 실제 사용하는 애플리케이션 개발과의 차이를 지적했다. 실제 애플리케이션을 개발할 때 추론 비용은 모델을 선택하는 데 중요한 역할을 하기 때문이다.
AI 에이전트의 추론 비용을 평가하는 것은 쉽지 않다. 동일한 모델에 대해서도 사업자에 따라 청구 금액이 달라질 수 있고, API 호출 비용은 정기적으로 변경되기도 한다.
따라서 이 문제를 해결하기 위해 토큰 가격에 따라 모델 비교를 조정하는 웹사이트를 만들었다.

이를 평가하기 위해 매우 긴 텍스트에 대한 벤치마크인 '노블QA(NovelQA)'에 대한 연구를 실시했다. 그 결과 벤치마크 결과와 실제 응용이 차이가 큰 경우도 발견했다.
예를 들어, 원래 노블QA 벤치마크에서는 검색 증강 생성(RAG)이 긴 컨텍스트 모델보다 성능이 훨씬 더 나쁘다는 결과가 나왔다. 하지만 RAG와 긴 컨텍스트 모델은 정확도에서 큰 차이를 보이지 않았으나, 비용은 긴 컨텍스트 모델이 20배 더 비싼 것으로 밝혀졌다.
마지막으로 지적한 것은 '과적합(overfitting)' 문제다.
이는 벤치마크 데이터를 너무 오래 학습, 모델이 추론이 아니라 데이타셋의 답을 외우고 답하게 되는 것을 말한다. 이는 벤치마크 데이터가 오래됐기 때문에 일어나는 것으로, 벤치마크에서는 좋은 성적을 거둔 모델이 현실에서는 성능을 못 내는 주요 이유이기도 하다.
이 문제를 해결하기 위해 벤치마크 개발자가 훈련 데이터와 테스트 데이터를 구분하는 '홀드아웃(holdout test) 테스트셋'을 구축해야 한다고 밝혔다. 연구자들은 17개 벤치마크를 분석한 결과, 상당수는 홀드아웃 데이터셋이 부족하다는 것을 발견했다.
이로 인해 벤치마크에 대한 과적합과 편법이 발생, 취약한 에이전트가 등장한다는 지적이다. 실제로 다양한 웹사이트 작업 능력을 평가하는 '웹아레나(WebArena)' 테스트 결과, 에이전트가 쉽게 과적합할 수 있는 몇가지 사례를 발견했다. 이는 에이전트가 벤치마크에서는 좋은 성적을 거뒀다고 해도, 다른 사이트에서는 잘 작동하지 않을 수 있다는 것을 의미한다.
연구원들은 이런 문제로 인해 AI 에이전트의 정확도 추정치가 높아지고, 결국 에이전트에 대한 지나친 낙관주의로 이어질 수 있다고 경고했다.
또 AI 에이전트가 새로운 분야이기 때문에 테스트 방법에 대해서는 아직 배울 것이 많다고 결론 내렸다.
"AI 에이전트 벤치마킹은 새로운 것이고 모범 사례가 아직 확립되지 않아, 진짜 발전과 과장을 구별하기 어렵다"라며 "이번 연구는 에이전트가 기존 AI 모델과는 다르기 때문에 벤치마킹 관행을 재고해야 한다는 것"이라고 밝혔다.
박찬 기자 cpark@aitimes.com
- [클릭AI] 앤트로픽, 'AI 안전' 벤치마크 개발 위해 지원금 내걸어
- 비전 모델 능력 평가하는 '멀티모달 아레나' 출시..."GPT-4o가 1위"
- 허깅페이스, LLM 리더보드 교체..."첫 주 1·2위는 큐원2·라마3"
- 앤트로픽 '클로드 3.5', 출시 5일 만에 '챗봇 아레나' 인간 선호도 1위 차지
- 구글 딥마인드, 13배 빠르고 10배 저렴한 AI 훈련 방법 ‘제스트’ 공개
- 캡제미니 "내년에는 협업형 다중 AI 에이전트 등장할 것"
- 애플, LLM 실제 능력 파악하는 벤치마크 도구 공개..."오픈 소스, 폐쇄형 비해 많이 부족해"
