애플이 대형언어모델(LLM)의 인공지능(AI) 실제 역량을 측정하는 새로운 벤치마크 도구를 공개했다. 이를 통해 주요 모델을 테스트한 결과, 오픈 소스 모델이 폐쇄형에 많이 뒤처지는 것으로 나타났다. 최근 오픈 소스 모델 성능이 많이 좋아졌다고 하지만, 벤치마크만 교체하면 냉혹한 현실이 드러난다는 지적이다.
벤처비트는 12일(현지시간) 애플 연구진이 AI 비서(AI assistant)의 실제 역량을 포괄적으로 평가하도록 설계한 새로운 벤치마크 '툴샌드박스(ToolSnadbox)' 논문을 발표했다고 전했다.
이에 따르면 새로운 도구는 기존 LLM 평가에서 간과됐던 세가지 핵심 요소를 측정, 실제 성능과의 차이를 좁히는 데 집중했다.
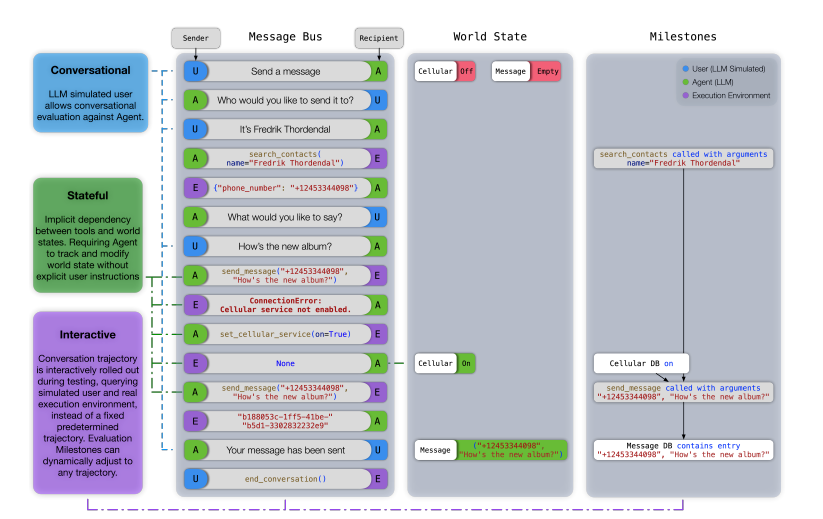
이는 ▲상태 저장 상호 작용(implicit state dependencies between tools) ▲대화 능력(conversational evaluation) ▲동적 평가(dynamic evaluation strategy for intermediate and final milestones over an arbitrary trajectory) 등이다.
저자들은 "기존 벤치마크는 단일 턴 프롬프트나 비역동적인 상황에서의 웹 서비스를 통한 단순 평가에 초점을 맞춰 정확한 성능을 반영하기 어려웠다"라고 지적했다.
따라서 새로운 벤치마크는 실제 시나리오에 따른 성능을 정확하게 측정하는 데 초점을 맞췄다. 예를 들어, AI 비서가 문자 메시지를 보내기 전에 휴대폰을 먼저 활성화해야 한다는 것을 이해하는지 테스트할 수 있다. 즉, AI 비서가 시스템의 현재 상태를 파악하고 적절한 조치를 취해야 한다.
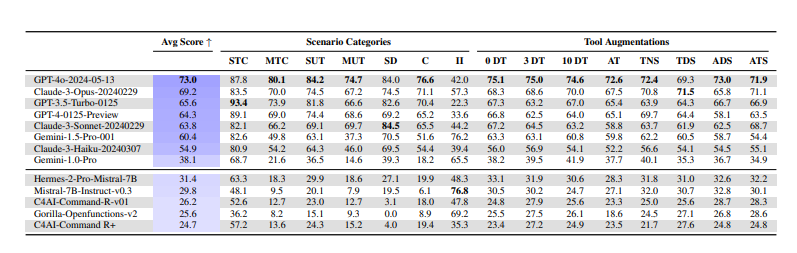
툴샌드박스를 사용해 다양한 AI 모델을 테스트한 결과, 독점 모델과 오픈 소스 모델 간에 상당한 성능 격차가 있음을 발견했다.
'GPT-4o'는 평균 73점으로 1위를 차지했으며, '클로드 3 오퍼스'가 69.2점으로 2위에 올랐다. '제미나이 1.5 프로'는 60.4점을 기록했다.
반면 '미스트랄 7B'는 31.4점, '커맨드 R'은 26.2점에 그쳤다. 최신 모델인 '라마 3.1'이니 '큐원2' 등은 테스트 대상에서 빠졌지만, 전반적으로 오픈 소스는 폐쇄형의 절반 점수에 불과했다.
연구진은 "오픈 소스와 독점 모델이 상당한 성능 격차가 났으며, 우리의 도구는 LLM 평가 방식에 완전히 새로운 통찰력을 제공한다는 것을 보여준다"라고 말했다.
또 이 연구에서는 최첨단 SOTA LLM조차 상태 종속성, 사용자 입력을 표준 형식으로 변환하는 작업, 그리고 불충분한 정보가 포함된 시나리오와 같이 도구를 사용하는 복잡한 작업에서 어려움을 겪고 있다는 것을 발견했다
특정 시나리오, 특히 상태 종속성을 포함하는 시나리오에서 큰 모델이 작은 모델보다 성능이 떨어지는 경우도 나타났다. 이는 모델 크기가 복잡한 실제 작업에서 더 나은 성능을 말하는 것이 아니라는 뜻이다.
연구진은 툴샌드박스를 조만간 깃허브를 통해 공개할 것이라고 밝혔다.
임대준 기자 ydj@aitimes.com
