
메타가 최근 공개한 대형언어모델(LLM) ‘라마 3.1-405B’을 훈련하는데 54일 걸렸으며 이 기간 동안 평균 3시간 마다 예상치 못한 장애(failure)로 작업이 중단됐던 것으로 알려졌다. 하드웨어와 소프트웨어의 비약적 발전으로 AI 학습 속도가 빨라졌지만, 그만큼 LLM의규모가 커지며 개발이 복잡해졌다는 말이다.
톰스하드웨어는 28일(현지시간) 메타가 라마 3.1 405B 모델 학습 과정을 자세히 설명하는 연구 결과를 소개했다고 보도했다.
이에 따르면 메타는 라마 3.1 405B 모델을 1만6384개의 엔비디아 'H100' GPU가 탑재된 클러스터에서 54일 동안 훈련을 진행했다. 이 기간 동안 419건의 예상치 못한 장애로 작업이 중단됐다. 평균 3시간마다 한번씩 장애가 발생한 셈이다.
수만개의 프로세서, 수십만개의 다른 칩, 수백마일의 케이블을 사용하는 복잡한 대규모 슈퍼컴퓨터 시스템에서 몇 시간마다 장애가 발생하는 것은 지극히 정상적인 일이다. 더 중요한 것은 시스템이 계속 작동하도록 만드는 것이다.
특히 1만6384개의 GPU를 사용하는 대규모 훈련에서는 장애가 발생하기 쉽다. 장애가 올바르게 복구되지 않으면, 최악의 경우 단일 GPU 장애만으로도 전체 훈련 작업을 중단하고 재시작해야 할 수 있다. 이 경우 시간과 비용이 기하급수적으로 늘어난다.
하지만 메타에 따르면, 라마 3.1-405B은 재시작 없이 효율적인 훈련 시간을 90% 이상 유지했다.
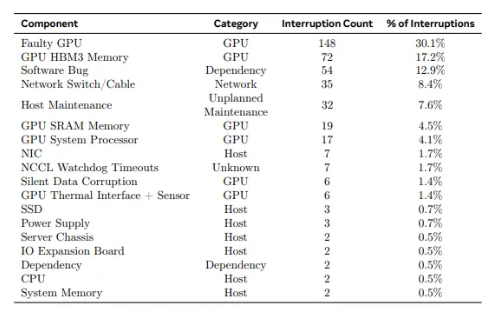
메타는 54일 훈련 기간 중 466건의 작업 중단이 발생했으며, 그중 47건은 계획된 중단이었고 예상치 못한 장애에 의한 중단이 419건이었다고 밝혔다. 계획된 중단은 자동 유지보수로 인한 것이었고, 예상치 못한 중단은 58.7%가 하드웨어 문제로 발생했다.
하드웨어 문제 중 148건(30.1%)은 GPU와 관련된 장애로 인해 발생했으며, 72건(17.2%)은 HBM3 메모리 장애로 인해 발생했다. 이는 엔비디아의 H100 GPU가 약 700W를 소비하고 많은 열이 발생한다는 점을 고려할 때 그리 놀라운 일이 아니다.
반면 54일 동안 CPU 장애는 단 2건에 불과했다. 또 복구에 수동 개입이 필요한 장애는 단 3건이었고, 나머지는 자동화로 해결됐다.
나머지 41.3%의 예상치 못한 중단은 소프트웨어 버그, 네트워크 케이블 및 네트워크 어댑터를 포함한 여러 요인으로 인해 발생했다.
이 외에도 메타는 수만개의 GPU에서 전력 소비량이 불규직으로 변하는 문제를 겪기도 했다. 이는 데이터센터의 전력망에 부담을 주는 문제로, 때로 수십메가와트(MW)에 달해 전력망의 한계를 초과한 경우도 발생했다. 데이터 센터에 충분한 전력을 확보하지 않으면, 훈련이 어렵다는 것을 의미한다.
한편 1만6384개의 GPU 클러스터에서 54일 동안 419건의 장애가 발생했다는 사실을 고려하면, 6배 많은 10만개의 H100 GPU가 탑재되는 일론 머스크의 xAI 클러스터에서는 얼마나 자주 장애가 발생할 지 의문이다.
그만큼 프론티어급 모델의 학습은 이제 규모의 싸움으로 치닫는 양상이다.
박찬 기자 cpark@aitimes.com
