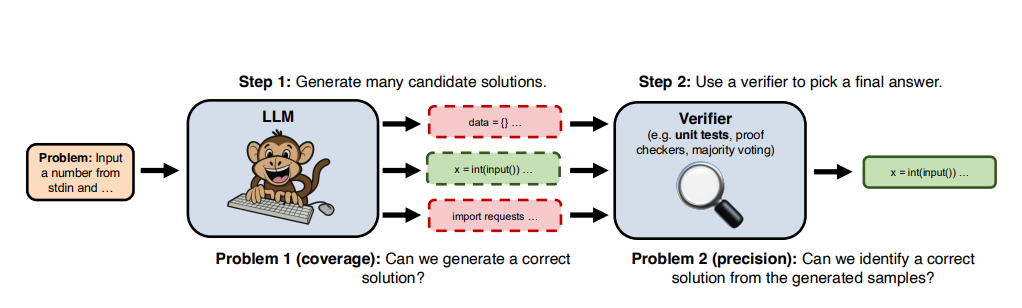
구글 딥마인드가 대형언어모델(LLM)의 추론 성능을 높이는 방법을 공개했다. 동일한 질문을 수백번 반복, 가장 좋은 답을 선택하는 간단한 방식이다. 이를 두고 연구진은 '대형언어 원숭이(LLM)'이라고 칭했다.
디 인포메이션은 12일(현지시간) 구글 딥마인드와 스탠포드대학교, 옥스포드대학교 연구진 등이 '대형 언어 원숭이: 반복 샘플링을 통한 추론 컴퓨팅 확장(Large Language Monkeys: Scaling Inference Compute with Repeated Sampling)'이라는 논문을 게재했다고 보도했다.
연구진은 훈련에 투입하는 컴퓨팅의 확장으로 LLM 성능이 크게 향상됐지만, 추론의 경우에는 문제당 한번으로 시도가 제한됐기 때문에 그 효과를 보지 못했다고 지적했다.
따라서 추론 횟수를 늘리기 위해 샘플 수를 4배 이상 투입하는 방법을 선택했다고 밝혔다. 즉, 같은 질문을 모델에게 4회 이상 반복했다는 말이다.
연구진은 이런 방식이 AI 코딩 어시스턴트에서 어떻게 작동하는지 실험했다. 'GPT-4o'와 '클로드 3.5 소네트'를 조합해 동일 질문을 반복, 찾아낸 최적의 답이 코드 생성 중 발생한 오류 중 43%를 해결했다고 밝혔다. 이는 SWE-벤치 라이트라는 테스트를 통해 밝혀졌다.
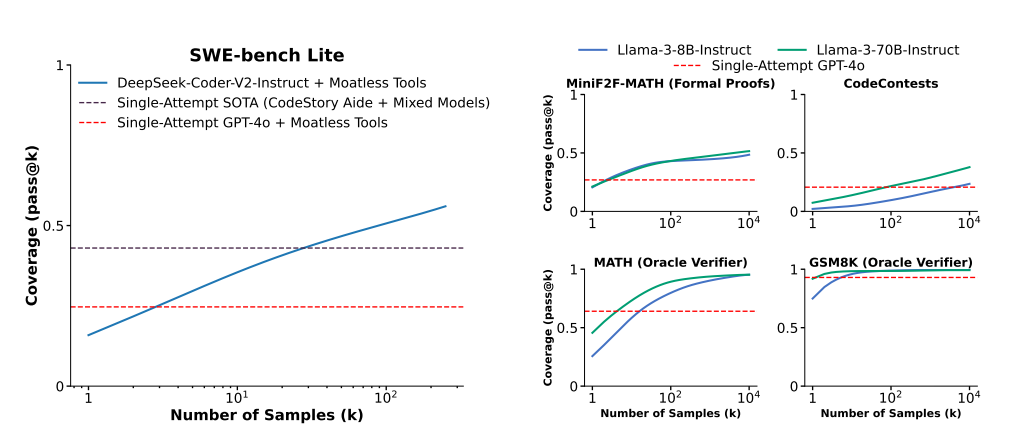
이 벤치마크는 LLM이 코드 오류를 얼마나 잘 수정할 수 있는지 테스트하는 것으로, 과거 '딥시크-코더(DeepSeek-Coder-V2-Instruct)'라는 모델은 최고 점수로 15.9%를 기록한 바 있다.
특히 연구진은 이 모델에 동일한 코딩 문제를 한번이 아니라 250번 풀도록 요청, 점수를 56%까지 끌어올렸다고 밝혔다. 이는 GPT-4o나 클로드 3.5 소네트 조합보다 13%나 높은 점수다.
결국 첨단 모델을 사용하는 것보다, 성능이 떨어지는 모델이라도 동일 질문을 반복하는 것이 더 정확도를 끌어 올리는 데 도움이 된다는 말이다. 또 비용 효율이 훨씬 뛰어나다고 강조했다.
연구진은 "딥시크 모델에 문제를 5번 풀게하고 그중 가장 좋은 답을 찾아내는 것이, GPT-4o나 클로드를 사용하는 것보다 더 정확하며 비용은 3배 이상 저렴하다"라고 밝혔다.
이런 방식이 코딩 모델에서 검증할 수 있는 것은 출력을 자동으로 검증할 수 있기 때문이다. 사람이 250개의 출력을 직접 확인하는 것은 아니다.
반면, 글 작성과 같이 자동 검증 기능이 없는 다른 분야에서는 가장 좋은 답을 가려내는 것이 쉽지 않으며, 이를 해결하는 것을 가장 큰 과제로 꼽았다.
이 경우 샘플링 방식의 '원숭이'는 효과적이지 않다는 지적이다.
임대준 기자 ydj@aitimes.com
