
ML옵스 전문 웨이트앤바이어스(W&B)가 언어모델의 한국어 능력을 비교하는 호랑이 리더보드의 첫번째 업데이트 버전 '호랑이 리더보드 3'을 31일 공개했다. 4월 출시 이후 6개월 만의 대대적 업데이트다.
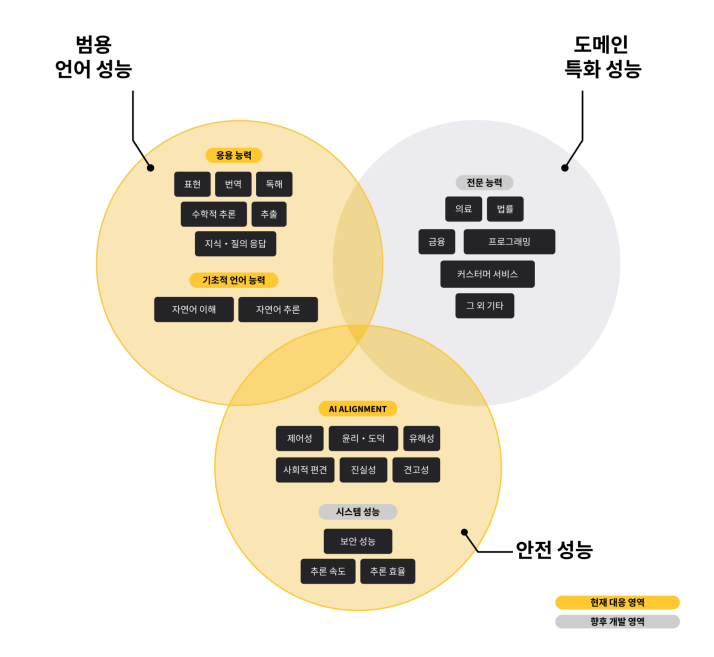
이번 업데이트로 언어모델의 용도에 따른 성능평가와 안전성 평가가 추가됐다. 또 추론 속도 향상 및 라이브러리 버전 관리 간소화 등을 통해 기업내 비공개 평가도 쉬워졌다. 오픈AI와 앤트로픽 등 최신 상용 API를 비롯한 국내외의 다양한 오픈소스 모델을 포함해 40개 이상의 모델평가 결과를 비교할 수 있다.
특히 AI 정렬(Alignment) 지표는 모델의 출력 제어능력, 유해성 판단, 사회적 편견을 포함해 모델이 사회적 가치관에 부합하는지 평가한다. 이를 위해 ▲KoBBQ ▲한국어 혐오 발언(Hate Speech) ▲AI HUB 의 텍스트 윤리검증 데이터 등 공개 데이터셋을 활용해 평가의 객관성과 신뢰도를 높였다.
평가 결과에서 주목할 점은 범용 언어 성능과 안전 성능은 비례관계를 보였다는 점이다. 이는 언어 모델이 기본적인 언어 이해와 생성 능력을 높을수록 윤리적 판단, 사회적 편견 관리 등 민감한 작업에서도 우수한 성능을 발휘할 가능성이 높다는 점을 시사한다.
또 한국어의 특성과 문화적 맥락을 반영하기 위해 오픈소스 언어모델 연구팀 ‘해례(HAERAE)’의 ▲해례_BENCH_V1 ▲KMMLU와 네이버 AI랩’ 의 ▲KoBBQ 를 활용해 평가를 수행했다.
실제 모델을 서비스할 때 적응력을 평가하기 위한 퓨샷 프롬프트 기반의 성능 평가도 추가했다. 제로샷 평가와 퓨샷 평가를 병행해 두 평가결과의 평균값을 최종 점수로 산출한다.
전체 평가 과정의 속도를 향상한 동시에 기업 내부에서도 자체 리더보드를 구축할 수 있게 지원한다.
업데이트 이후 국내 모델들은 주로 10B이하의 소형언어모델(sLM)들로 평가가 이뤄졌다.
10B이하 모델 중에서는 LG AI연구원의 '엑사원(EXAONE-3.0-7.8B)'이 두드러진 성능을 보였다. 10B~30B 모델에서는 업스테이지의 '솔라(Solar-mini)'가 높은 성능을 보였다.
W&B측은 "새로운 리더보드는 W&B의 강점을 살려 사용자와의 상호작용 기능을 강화했다"라며 "리더보드에서 실시간으로 다양한 모델을 추가하고 바로 분석해 평가결과를 비교할 수 있다"라고 말했다.
박수빈 기자 sbin08@aitimes.com
