
구글이 새로운 비전언어모델(VLM) ‘팔리젬마 2(PaliGemma 2)’를 오픈 소스로 공개했다. 이 모델은 단순히 객체를 식별하는 것을 넘어 이미지 속에서 감정과 동작을 분석하고, 장면의 전반적인 서사를 파악할 수 있는 고도화된 기능을 갖추고 있다고 밝혔다.
구글은 5일(현지시간) 이미지 캡션 작성과 텍스트 이해, 객체 감지 및 분할, 시각적 질문 응답(VQA) 등 다양한 기능을 제공하는 오픈 소스 VLM ‘팔리젬마 2’를 출시했다.
이는 지난 5월 출시된 '팔리젬마'의 후속 모델로, 기존 모델 대비 더욱 길고 세밀한 사진 설명을 생성할 수 있는 점이 특징이다.
구글의 '젬마 2' 언어 모델을 기반으로 개발, 언어 처리 능력이 크게 향상됐다. 이를 통해 복잡하고 디테일한 이미지 분석이 가능, 실질적인 활용도가 높아졌다는 설명이다.
모델 크기는 30억, 100억, 280억 매개변수로 구성된다. 구글의 AI 전용 프로세서인 TPUv5를 활용해 학습 효율성을 극대화했으며, 일반 PC 환경에서도 효과적으로 실행될 수 있도록 최적화했다.
또 224p 해상도만 지원했던 기존 모델과 달리, 이번 버전은 448p와 896p 고해상도까지 지원해 활용폭을 넓혔다.

글씨를 정밀하게 인식하는 광학문자인식(OCR) 기술과 표의 구조와 내용을 이해하는 기능도 강화됐다.
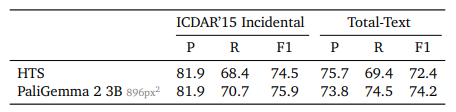
구글은 이 모델이 화학 공식 및 음악 악보 인식, 공간 추론, 흉부 X-레이 보고서 생성 등에서 탁월한 성능을 보였다고 강조했다. 예를 들어, 텍스트 인식 평가 벤치마크인 'ICDAR 15'와 '토털텍스트' 데이터셋에서 F1 점수 75.9를 기록해 기존 최고 성능을 뛰어넘었다.
또 구글은 이 모델에 대해 "단순한 객체 식별을 넘어 장면의 동작, 감정 및 전반적인 내러티브를 설명한다"라고 강조했다.
하지만 사진 속 인물 사진의 감정까지 읽어낼 수 있다는 내용에 일부 전문가들은 부정적인 반응을 보였다.
마이크 쿡 퀸 메리 대학교 연구원은 테크크런치와의 인터뷰에서 "사람들은 복잡한 방식으로 감정을 경험하기 때문에 일반적인 경우에는 감정 감지가 불가능하다"라며 "많은 기관이나 회사들이 수년에 걸쳐 시도했으나 완전한 사례는 등장하지 않았다"라고 전했다.
한편, 구글은 팔리젬마 2가 기존 모델과 쉽게 교체 가능한 ‘드롭인 대체’로 설계됐으며, 이 때문에 별다른 코드 수정 없이 즉각적인 성능 향상을 제공할 것이라고 밝혔다. 또 특정 작업에 맞게 모델을 손쉽게 미세조정할 수 있는 점도 큰 장점으로 내세웠다.
팔리젬마 2의 사전 학습 모델과 코드는 현재 허깅페이스와 캐글에서 다운로드 가능하다.
박찬 기자 cpark@aitimes.com
