
허깅페이스가 경량형 오픈 소스 비전-언어모델(VLM) ‘스몰VLM(SmolVLM)’을 공개했다. 이 모델은 인터넷 연결 없이도 모바일 기기에서 완전히 실행될 수 있도록 설계된 온디바이스 인공지능(AI)에 최적화돼 있다.
허깅페이스는 27일(현지시간) 클라우드 서버에 연결하지 않고도 장치에서 로컬로 실행 가능한 온디바이스 AI용 VLM ‘스몰VLM’을 오픈 소스로 출시했다.
스몰VLM은 이미지 및 텍스트 입력을 받아들여 텍스트 출력을 생성하는 20억 매개변수의 소형 멀티모달모델이다.
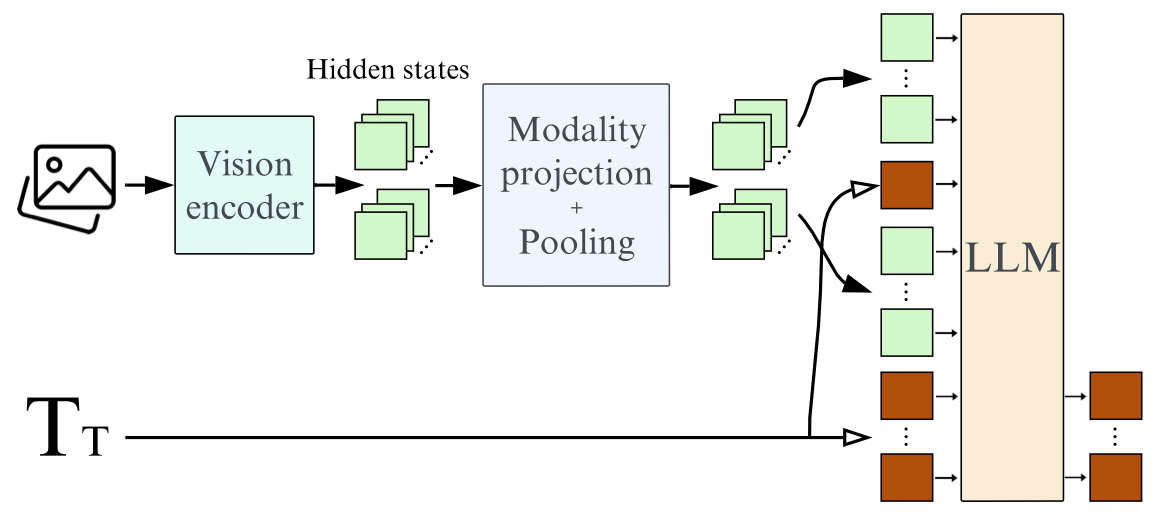
텍스트 처리를 위해 자체 개발한 언어 모델 '스몰LM2(SmolLM2)'와 형태 최적화된 이미지 인코더 '시그립(SigLIP)'을 결합했으며, 훈련 데이터는 '콜드론(Cauldron)'과 '도크매틱스(DocMatix)' 데이터셋에서 큐레이팅했다.
특히, 동급 모델 중에서 메모리 효율성이 가장 뛰어난 것으로 평가받고 있다.
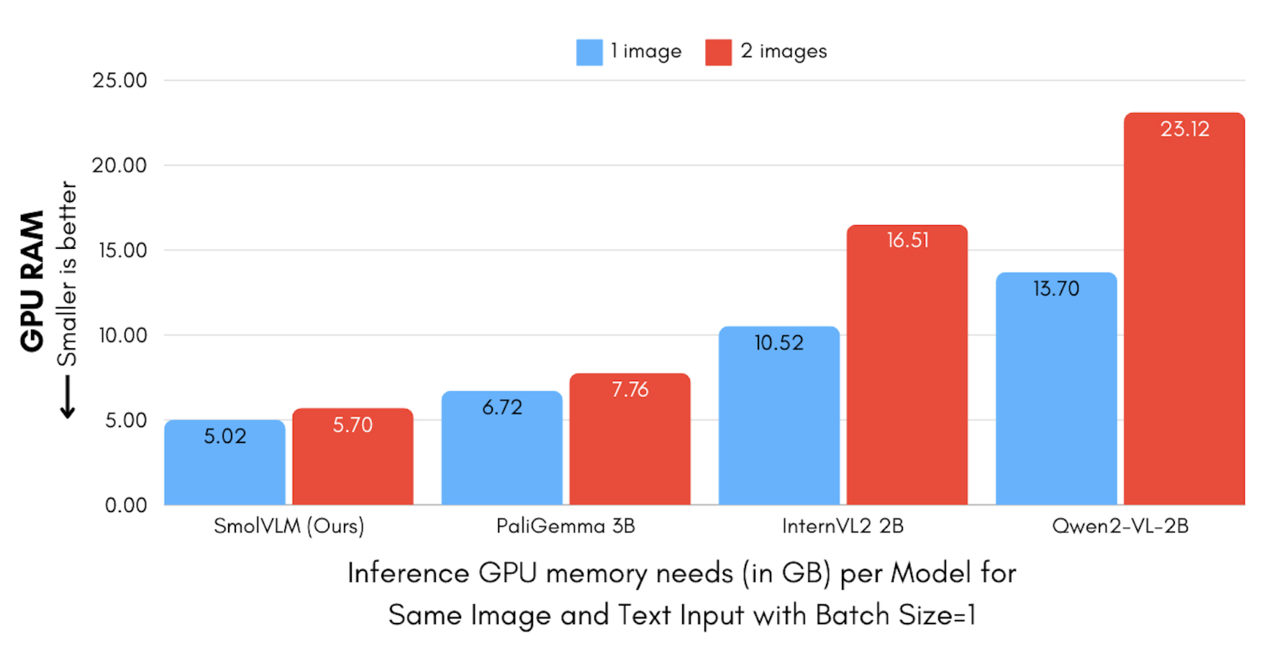
노트북 등 일반적인 장치에서도 효율적으로 실행할 수 있도록 설계된 이 모델은 GPU RAM를 단 5.02GB의 메모리만 사용한다. 반면, 경쟁 모델인 '팔리젬마 3B(PaliGemma 3B)', '큐원VL 2B(QwenVL 2B)', '인턴VL2 2B(InternVL2 2B)'는 각각 6.72GB, 13.70GB, 10.52GB를 요구한다.
스몰VLM의 이미지 인코딩 효율성은 모델 구조에 달려 있다. 예를 들어, 384x384 크기의 이미지 패치를 81개의 토큰으로 인코딩하며, 테스트 프롬프트와 단일 이미지를 1.2k 토큰으로 처리한다.
반면, 큐원2-VL은 동일한 작업에 16k 토큰을 사용한다. 인코딩 차이로 인해 큐원과 인턴VL은 다수 이미지를 처리할 때 메모리 사용량이 급증하지만, 스몰VLM과 팔리젬마의 메모리 사용량은 훨씬 완만하게 증가한다는 설명이다.
또 작은 메모리 사용량 덕분에 모델의 초기 입력 사전 처리(prefill)를 위한 계산량과 출력 생성 속도에서 뛰어난 성능을 보인다. 큐원2-VL과 비교했을 때, 사전 처리 속도는 3.3~4.5배, 출력 생성 속도는 7.5~16배 더 빠르다.
정지 이미지뿐 아니라 영상 분석에서도 성과를 보인 스몰VLM은 '시네파일(CinePile)' 벤치마크에서 27.14%의 점수를 기록했다. 이는 '인턴VL2 2B'와 '비디오 라바 7B(Video LlaVa 7B)' 사이에 위치하는 경쟁력이다.
현재 스몰VLM은 허깅페이스에서 무료로 다운로드 가능하며, 상업적 용도로도 사용할 수 있다.
박찬 기자 cpark@aitimes.com
- 넥사 AI, 세계에서 가장 작은 비전 언어 모델 ‘옴니비전-968M’ 출시
- 알리바바, 20분 길이 영상 분석 가능한 모델 '큐원2-VL' 출시
- MS, 비전·언어 통합 처리 모델 ‘플로렌스-2’ 출시..."범용성·성능 월등"
- 중국 칭화대, 엣지 디바이스에 최적화된 LMM ‘GLM-엣지’ 공개
- 메타, 엣지 장치용 매개변수 11억 '라마 가드 3' 공개
- 구글, 사진에서 인간 감정까지 읽어내는 VLM '팔리젬마 2' 출시
- 허깅페이스, 휴대폰서 구동하는 '가장 작은' 비전 언어 모델 출시
- 구글, 인기 VLM ‘팔리젬마 2' 업그레이드 버전 출시..."모델 세분화로 유연성 확대"
