
“영상언어모델은 ‘이미지 이해’의 영역인 비전언어모델(VLM)의 개념에서 한단계 더 나아가, 영상의 앞뒤 맥락과 오디오 데이터까지 이해하는 모델입니다. 인공지능(AI)이 사람처럼 사고하도록 만드는 기술로, 이는 로보틱스와 연결됩니다.”
영상이해 인공지능(AI) 전문 트웰브랩스(대표 이재성)는 세계적인 AI 스타트업을 꼽을 때 항상 빠지지 않는 곳이다. 국내보다 미국에서 더 유명하다.
디즈니와 미식축구리그(NFL) 등과 협업 논의 중인 것은 물론, 지난 6월에는 엔비디아 자회사 등으로부터 700억원 규모의 시리즈A 투자 유치에 성공했다.
지난해만 해도 이 회사의 기술은 다소 낯선 편이었다. 그럴 만도 했던 것이 오픈AI나 구글이 본격적으로 멀티모달모델(LMM)을 내놓은 것이 올해부터이기 때문이다.
하지만 트웰브랩스가 이름을 알린 것은 2022년 12월 래디컬 벤처스 등으로부터 1200만달러(약 169억원) 투자 유치에 성공하면서부터다. 또 지난해 11월에는 대형영상언어모델(VLFM, Video Language Foundation Model) '페가수스'를 공개했다.
그리고 이승준 최고기술 책임자(CTO)의 설명은 트웰브랩스의 기술이 멀티모달을 넘어 차세대 AI 기술로 떠오른 세계 모델(LWM)과 일맥상통한다는 점을 보여 줬다.
이 CTO는 우선 “2020년 창업 초기부터 영상이해의 가능성을 높이 평가했다”라며 “무엇보다 데이터 부족과 사전 훈련의 한계를 극복하기 위해서는 견고한 파운데이션 모델의 역할이 중요하다고 생각했다”라고 말했다.
이어 트웰브랩스가 고도화 중인 VLFM은 대형언어모델(LLM)과 VLM에 이은 최첨단 모델이자, 향후 나아갈 방향이라고 밝혔다.
AI가 혁신적인 성능과 응용력의 발전을 보인 것은 자연어를 이해하고 생성하는 LLM 때문이다. 여기에 시각적인 능력이 추가하면 VLM이 된다. 이승준 CTO는 “VLM은 이미지를 하나 제시하고 관련 질문을 했을 때 옆에서 답변을 제시해 주는 비서라고 볼 수 있다”라고 말했다.
트웰브랩스의 VLFM은 이때 이미지를 넘어 영상까지 이해하고 자연어로 설명하는 기술이다.
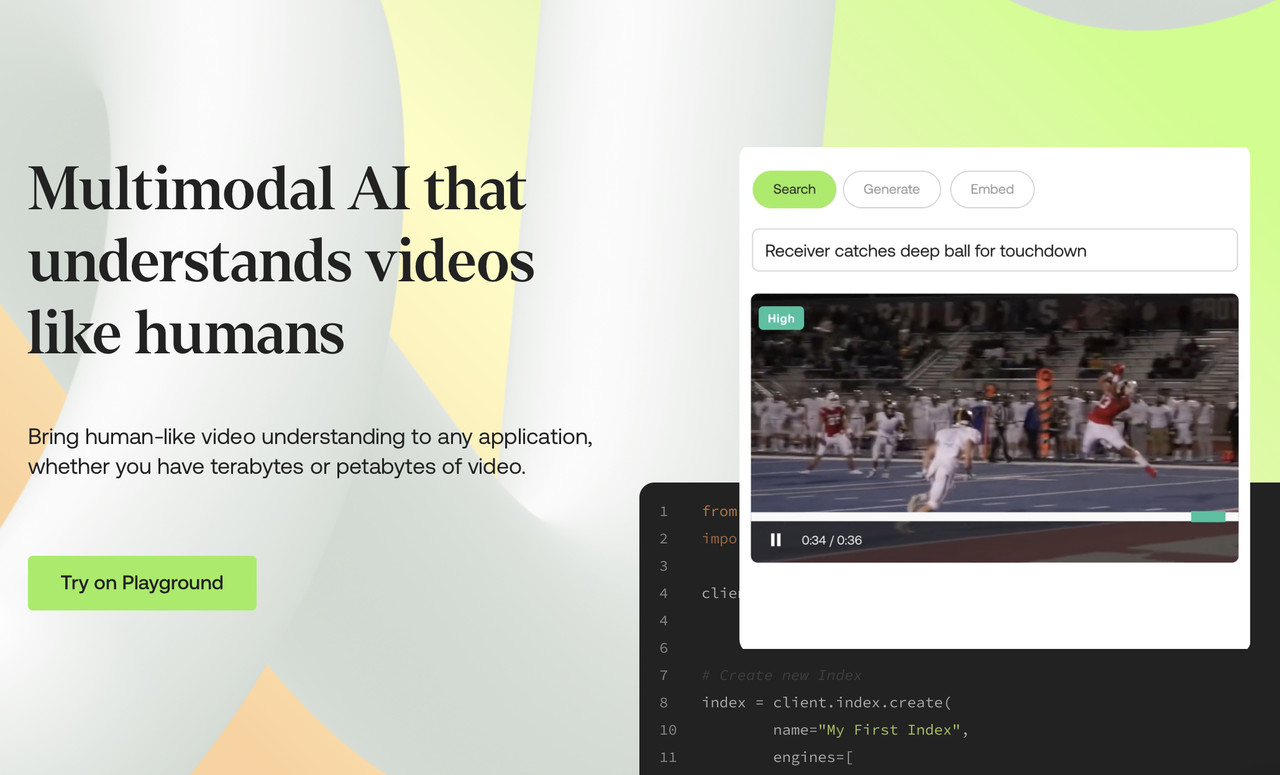
영상은 멈춰 있는 사진과 달리 앞뒤 장면과 맥락, 오디오 정보까지 포함한 복잡한 형태다. 당연히 VLFM은 VLM보다 고차원 작업을 수행한다.
이를 이용한 비즈니스 영역도 무궁무진하다. 디즈니나 NFL과 논의 중인 것이 좋은 예다. 영상의 분류, 영상의 특정 장면 검색 등 스포츠나 미디어 업계에서 수요가 많다. “특정 배우가 등장하는 장면을 분류해 줘” 등과 같은 질문을 처리할 수 있다.
이 때문에 이 CTO는 VLFM은 VLM보다 "더 노련하고 나이가 든 사람"에 비유했다.
사람은 나이를 먹으며 물리법칙과 같은 기본적인 사고 구조를 갖추게 되기 때문이라는 것이다. 예를 들어 ‘물병을 높은 곳에서 떨어뜨리면 깨진다’라는 사실은 그 자체만으로는 유용해 보이지 않을지라도, 세상을 살아가기 위한 기본 지식으로서는 매우 중요한 부분이다.
그리고 이 점이 VLFM이 이해하는 ‘맥락’의 한 부분이다. 앞뒤 장면을 모두 파악, 활용하기 때문이다.
트웰브랩스는 바로 이 부분에 집중했다는 설명이다. “사람은 기본 지식만 갖추면 그다음부터는 스스로 사고하며 세상을 살아갈 수 있다”라며 “트웰브랩스의 VLFM은 이런 기본 지식을 탄탄하게 갖추기 위해 고도화에 집중하고 있다"라고 전했다.
그리고 이렇게 쌓인 모델의 지식으로 인해 추가 데이터 학습을 최소화(퓨샷 러닝)할 수 있다는 설명이다.
이는 트웰브랩스의 지향점과 연결된다. 또 최근 회자되는 세계 모델과도 일맥상통한다.
LWM의 가장 유력한 응용 분야로는 로봇이 꼽힌다. 이 CTO도 로보틱스를 지목했다.
"VLFM이 ‘영상언어액션모델’로 진화하면, 인간처럼 생각하고 행동하는 로보틱스까지 나아갈 수 있게 된다"라고 밝혔다. 영상언어액션모델이란 카메라에 찍힌 영상을 보고 이해해 자연어로 답을 도출하는 대신, 행동(Action)으로 출력하는 것이다.
예를 들어 “물잔을 들어서 내게 넘겨달라”라는 명령어를 실현하기 위해서는 반드시 하드웨어(로봇)가 필요하다. 그리고 정해진 루틴이 아닌 수시로 변하는 명령어를 이해하고 수행하기 위해서는 영상언어액션모델로 나아가야 한다고 설명했다.
그는 “이전 로봇은 명령과 출력을 외워서 행동하는 것에 가까웠다”라며 “이 때문에 각도를 어느 정도 기울여야 하는지, 압력을 어느 정도 줘야 하는지 등을 미리 입력한 것 외에는 수행할 수 없었다”라고 말했다.
하지만 로봇이 영상을 이해하고 있다면, 이를 바탕으로 사고가 가능해진다. 이에 맞춰 ‘각도를 4도 기울여서, 10 정도의 압력으로’와 같은 수치 결과를 출력할 수 있다면 물잔을 집어서 건네줄 수 있는 로봇이 탄생하리라는 전망이다.
이승준 CTO는 “로보틱스는 늘 염두에 둔 분야였다”라며 “사람의 눈과 사고능력을 닮은 모델을 이용한다면 ‘데이터 학습을 최소화하는 로보틱스’를 구현할 수 있다고 생각해 왔다”라고 말했다.
무엇보다 로보틱스 데이터는 수가 매우 적다. 또 로봇 관련 데이터는 많이 보유하고 있지만, 파운데이션 모델이 없는 경우도 많다고 전했다.
물류 창고에 100만대에 달하는 로봇을 배치, 관련 데이터를 대량 보유한 아마존도 비슷한 상황이다. 아마존도 파운데이션 모델을 구축하기 위해 지난 9월 LLM 기반 로봇 AI 스타트업 코베리언트를 인수했다.
이런 경우 트웰브랩스가 1순위로 꼽힌다는 설명이다. 현재 다수의 해외 기업과 협업을 진행 중이다.

이승준 CTO는 "VLFM이 생각지도 못한 많은 수요를 발생시키고 있는 것처럼, 영상언어액션모델도 앞으로 많은 사용처를 갖출 것”이라며 “영화 속 휴머노이드 같은 AI의 최종 진화 형태로 나아갈 수도 있다”라고 말했다.
또 “트웰브랩스는 이런 용어가 생기기도 전부터 해당 기술을 연구해 왔다"라며 "그 덕분에 빠른 시장 진출이 가능한 것”이라고 강조했다.
장세민 기자 semim99@aitimes.com
- 트웰브랩스 “디즈니·NFL 이어 SKT 등 국내외 주요 기업과 협업 논의"
- 트웰브랩스, 최고 권위 AI학회 ‘뉴립스’에서 영상-언어 모델 워크숍 주최
- 트웰브랩스, 엔비디아 등으로부터 700억 규모 시리즈A 투자 유치
- 트웰브랩스, '시리' 개발 주역 김윤 CSO 영입..."멀티모달 AI 강화로 글로벌 선두 도약할 것"
- 아마존, 새 모델 '올림푸스'에 영상 이해 기능 추가..."경쟁사 차별화에 초점"
- 이승준 트웰브랩스 CTO, 포브스 북미 ‘30세 미만 30인’ AI 리더 선정
- 트웰브랩스, 430억 전략적 투자 유치…데이터브릭스·스노우플레이크·데이터브릭스·SKT와 기술 협력
