한국과학기술원(KAIST, 총장 이광형)은 황성주 교수 연구팀이 인공지능(AI) 안전성 연구를 통해 AI 모델의 신뢰성과 안전성을 향상하는 두가지 기술을 개발했다고 12일 밝혔다.
AI 모델은 의료 진단과 얼굴 인식, 신용평가 등에서 활용되지만, 불건전한 내용과 욕설, 폭력적인 콘텐츠 등을 포함한 데이터를 학습해 문제가 된다.
황성주 교수 연구팀은 이 문제를 해결하기 위해 두가지 주요 연구를 수행했다. 첫번째는 '뉴립스(NeurIPS 2024)' 워크숍에서 발표한 것으로, 경량 모델을 활용해 AI 모델의 안정성을 효율적으로 검출하는 방안이다. 데이터 증강 기법을 이용해 안전성을 강화한 증류 모델을 개발, 불건전 콘텐츠를 사전 검출해낸다는 설명이다.
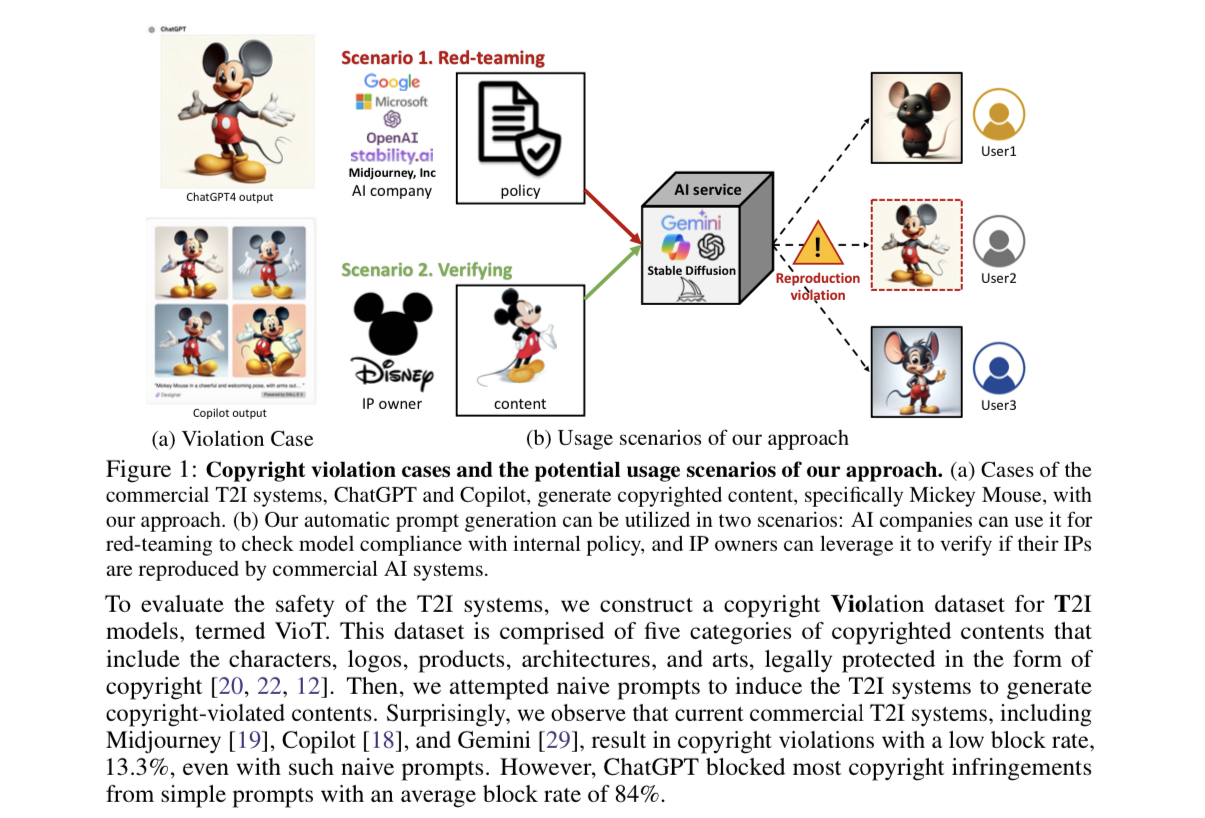
두번째 연구는 'ICML 2024' 워크숍에서 발표한 것으로, '챗GPT'와 같은 텍스트-이미지 생성 AI 시스템이 특정 회사 디자인을 학습해 저작권을 침해하는 문제를 지적했다. 연구팀은 사전에 저작권 안정성을 검증할 수 있는 검사 체계를 제안했다. AI 모델이 생성하는 콘텐츠가 저작권을 침해하지 않도록 사전 차단할 수 있는 기술이라고 전했다.
KAIST는 "앞으로도 지속적 기술 개발과 혁신을 통해 안전하고 신뢰할 수 있는 AI 생태계 구축에 앞장서겠다"라고 전했다.
이번 프로젝트에 참여한 한 연구원은 “AI 안전성은 앞으로의 디지털 시대에 필수적인 요소로, 우리의 연구가 AI 기술의 신뢰성을 높이고 사용자들에게 안전한 환경을 제공하는 데 기여하기를 바란다”라고 말했다.
과학기술정보통신부의 과제로 진행된 해당 연구는 ‘기계학습 모델 보안 역기능 취약점 자동 탐지 및 방어 기술 개발’(과제책임 손수엘 교수)로 2020년 4월부터 오는 2027년 12월말까지 8년 간 진행된다.
한편, 해당 논문은 관련 웹사이트 등에서 만나볼 수 있다.
장세민 기자 semim99@aitimes.com
