시각 언어 모델(VLM)이 '~이 없는'이라는 부정(Negation) 개념을 이해하지 못한다는 지적이 나왔다. 이는 학습 과정에 따른 편향 때문으로, 이를 판단하고 수정하기 위한 새로운 벤치마크와 데이터셋이 등장했다.
MIT와 구글 딥마인드, 옥스포드대학교 연구진은 최근 VLM의 부정 이해력의 평가 및 개선을 위한 '네그벤치(NegBench)' 프레임워크에 대한 논문을 온라인 아카이브에 게재했다.
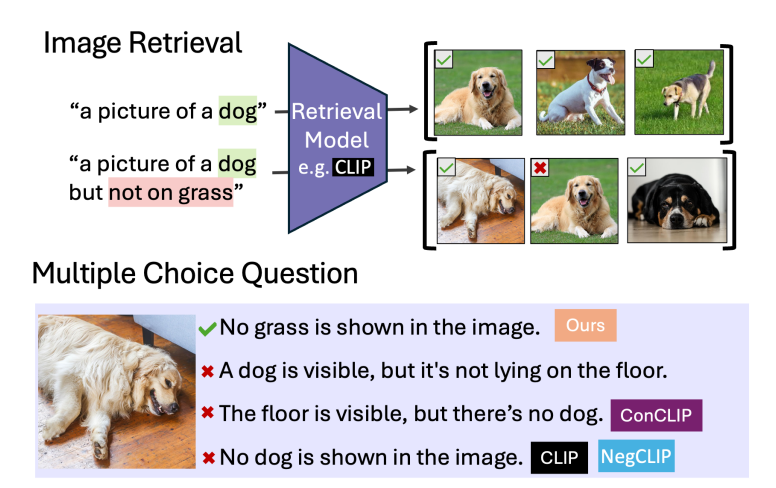
VLM은 이미지 검색이나 캡션 작업, 의료용 사진 판독과 같은 작업에서 중요한 역할을 한다. 그러나 이런 모델은 여전히 부정을 잘 이해하지 못한다는 설명이다. 예를 들어, '창문이 없는 방'이라는 이미지를 찾아달라고 하면, VLM은 '창문이 있는 방' 이미지를 찾아줄 가능성이 크다는 말이다.
이는 학습 데이터셋에 주로 긍정의 예가 포함돼 있기 때문에 부정과 긍정 진술을 동등하게 처리하는 '긍정 편향'이 발생하기 때문이다. '창문이 없는'이라는 상황을 주어져도, VLM은 배운대로 창문을 무조건 떠올린다는 말이다.
심각한 문제를 일으킬 수도 있다. 예를 들어 의료용 사진 분석이나 CCTV를 통한 안전 감시 등에서다. 연구진은 VLM의 성능이 많이 향상됐지만, 부정을 이해하는 능력은 여전히 충분히 연구되지 않았다고 지적했다.
따라서 이미지와 비디오, 의료 데이터 등 18가지 분야의 7만9000개 샘플을 통해 부정 이해를 평가하도록 설계된 새로운 벤치마크를 개발했다고 전했다. 기존 표존 데이터셋에 부정 요소를 추가하고, 새로운 합성 데이터로 부정을 강화했다.
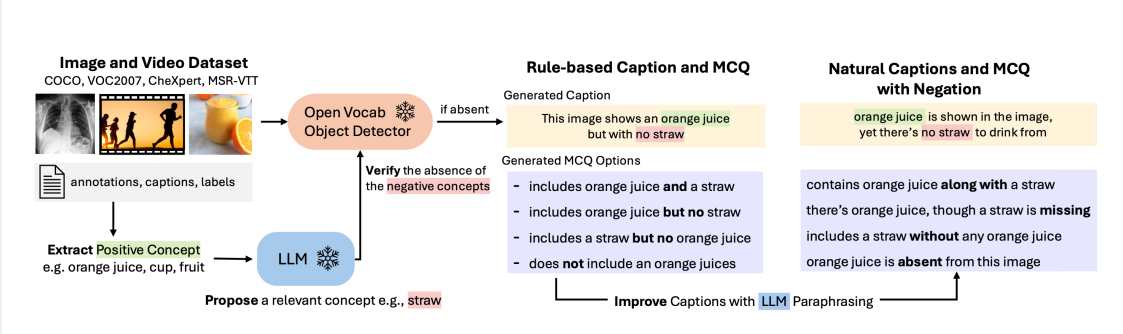
이를 통해 VLM이 ▲검색을 통한 부정 사례를 찾아낼 수 있는지(Retrieval-Neg) ▲부정 캡션이 있는 객관식 문제에서 정답을 가려낼 수 있는지(MCQ-Neg) 등을 테스트한다.
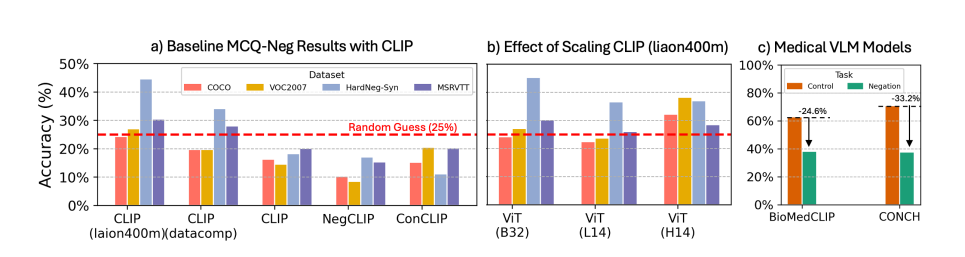
테스트 결과 최신 VLM은 부정에 상당히 어려움을 겪고 있으며, 정확도는 찍기 수준에 그쳤다고 밝혔다.
또 이런 단점을 해결하기 위해 수백만개의 부정 캡션이 포함된 대규모 합성 데이터셋으로 클립(CLIP) 모델을 미세조정했다.
이 모델은 부정 검색 정확도가 10% 증가하고, 특히 객관식 문제에서는 정답률이 40% 향상됐다고 밝혔다.
이에 대해 테크크런치는 부정을 이해하지 못하는 VLM의 문제를 해결한 최초의 작업으로 중요한 문제 해결 사례로 꼽았다.
또 이런 개선은 의학적 진단이나 콘텐츠 검색 등의 분야에서 미묘한 언어 이해가 가능한 강력한 AI 시스템 개발을 가능하게 만든다고 평했다.
임대준 기자 ydj@aitimes.com
