
중국의 대표 인공지능(AI) 스타트업 미니맥스가 역대 최대 길이의 컨텍스트 창을 갖춘 오픈 소스 모델을 공개했다. 컨텍스트 창을 기존 최고 수준의 2배가량 확장, 다가오는 AI 에이전트 시대에 대응하겠다는 의도다.
미니맥스는 15일(현지시간) X(트위터)를 통해 장기 컨텍스트 처리와 AI 에이전트 개발을 강화하기 위해 설계된 ‘미니맥스-01(MiniMax-01)’ 시리즈를 오픈 소스로 공개했다고 발표했다. 이 시리즈는 ▲대형언어모델(LLM) ‘미니맥스-텍스트-01’ ▲비전언어모델(VLM)인 ‘미니맥스-VL-01’ 등 두가지로 출시됐다.
미니맥스-01은 '라이트닝 어텐션(lightning attention)' 메커니즘을 활용해 긴 시퀀스 처리에서 계산 복잡도를 크게 줄였다.
기존의 트랜스포머 아키텍처와는 달리, 이 메커니즘은 선형(Linear) 레이어와 소프트맥스(SoftMax) 레이어를 번갈아 배치하여 긴 입력을 빠르고 효율적으로 처리할 수 있다. 선형 레이어는 입력 데이터에서 중요한 특성을 추출하고, 소프트맥스 레이어는 각 입력 값이 얼마나 중요한지를 확률로 바꿔 LLM이 입력의 의미를 추정할 수 있도록 돕는다.
또 최대 계산 용량을 활용하기 위해 '전문가 혼합(MoE)' 아키텍처를 통합했다. 이 모델은 32명의 전문가와 총 4560억개의 매개변수를 가지고 있으며, 이 중 459억개의 매개변수가 토큰마다 활성화된다.
MoE와 라이트닝 어텐션을 효과적으로 활용하기 위해 최적화된 병렬 처리 방법과 계산-통신 중첩(computation-communication overlap) 기술도 개발했다. 이를 통해 수백억개의 매개변수를 가진 모델이 수백만 토큰에 달하는 컨텍스트에서도 효율적으로 학습하고 추론할 수 있다는 설명이다.
미니맥스-텍스트-01은 학습 시 최대 100만 토큰, 추론 시 최대 400만 토큰의 컨텍스트 창을 처리할 수 있다. 이는 기존의 최고 수준인 '제미나이 1.5 프로'의 200만 토큰 컨텍스트 창보다 두배 더 확장된 용량이다. 또 일반적으로 3만2000에서 25만6000 토큰 사이의 다른 모델과 비교하면 무려 20~32배 더 많은 처리 능력을 제공한다.
이처럼 컨텍스트 창을 확장한 것은 AI 에이전트 기능 때문이다. 미니맥스는 "에이전트는 확장된 컨텍스트 처리 기능과 지속적인 메모리를 점점 더 필요로 한다"라며 "우리는 에이전트 관련 애플리케이션의 급증을 지원할 준비가 됐다"라고 밝혔다.
미니맥스-VL-01은 가벼운 비전 트랜스포머(ViT) 모듈을 통합, 4단계 학습 파이프라인을 통해 5120억개의 비전-언어 토큰을 처리한다.
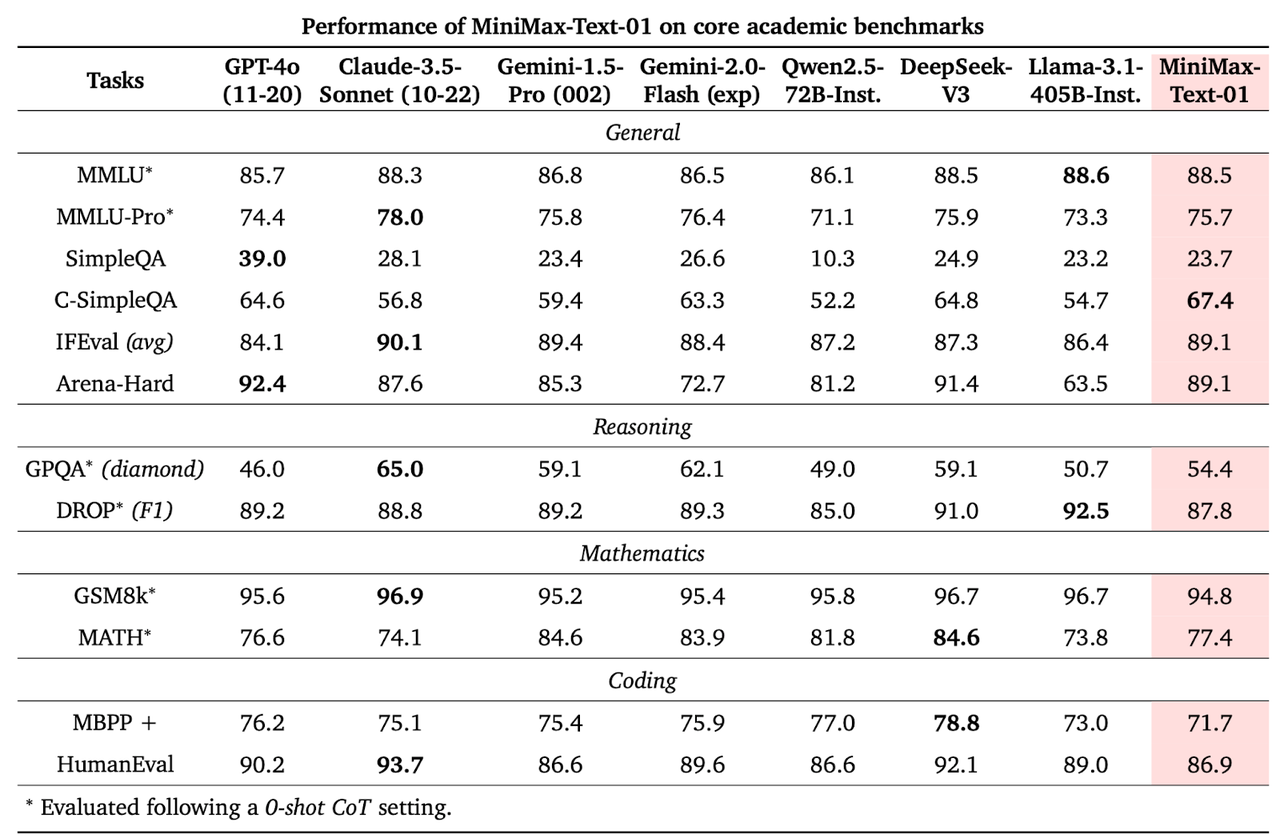
미니맥스-01은 주요 텍스트 및 멀티모달 벤치마크에서 'GPT-4'와 '클로드 3.'5와 같은 최고 모델들과 경쟁하며, 특히 긴 컨텍스트 처리에서 강력한 성과를 보였다.
예를 들어, 미니맥스-텍스트-01은 MMLU에서 88.5%의 정확도를 기록하며 GPT-4와 경쟁할 만한 성능을 발휘했다. 미니맥스-VL-01은 DocVQA에서 96.4%, AI2D 벤치마크에서 91.7%의 정확도를 기록하며 다른 경쟁 모델들을 앞섰다.
특히 미니맥스-텍스트-01은 400만 토큰의 컨텍스트로 수행한 '건초 더미에서 바늘찾기(Needle-In-A-Haystack)' 작업에서 100% 정확도를 달성했다.
이처럼 최근 중국의 오픈 소스 모델은 미국 폐쇄형 프론티어 모델을 빠르게 따라잡고 있다. 대표적인 것이 지난해 말 출시된 오픈 소스 최강 성능의 '딥시크-V3'다.
미니맥스 역시 중국을 대표하는 'AI 4마리 호랑이' 중 하나로, 이전에는 '스타워즈' 패러디로 유명해진 동영상 생성 모델을 출시한 바 있다.
현재 미니맥스-01 모델은 허깅페이스와 깃허브에서 다운로드할 수 있으며, 사용자는 이를 하이루오 AI 챗(Hailuo AI Chat)에서 직접 사용해 볼 수 있다. 또 개발자들은 미니맥스의 API를 통해 이 모델을 활용할 수 있다.
박찬 기자 cpark@aitimes.com
