
인공지능(AI) 모델의 능력을 평가하는 벤치마크 사상 가장 어려운 문제를 만들었다는 주장이 나왔다. '인류의 마지막 시험(Humanity's Last Exam)'이라는 이 테스트에서 오픈 AI의 'o1'과 딥시크의 'R1'은 정답률 10%에도 미치지 못했다.
뉴욕타임스는 24일(현지시간) 유명한 AI 안전 연구자인 댄 헨드릭스 AI 안전센터 이사가 스케일 AI와 협력, AI 모델의 능력을 평가하는 테스트셋 'HLE'를 구축했다고 보도했다.
이에 따르면 이 벤치마크의 원래 이름은 '인류의 마지막 생존(Humanity's Last Stand)'이었으나. 지나치게 극단적이라는 이유로 교체됐다.
그만큼 난이도는 이제까지 등장한 벤치마크 중 가장 높은 수준이라는 설명이다. 헨드릭스 이사 등은 대학교수와 수상 경력이 있는 수학자를 포함한 50개국 500개 이상의 기관에 소속된 1000여명의 전문가들로부터 가장 높은 수준의 난이도로 구성된 문제를 제공해줄 것을 요청했다.
또 철학부터 로켓 공학까지 3000개의 객관식 및 단답식 질문을 포함하고 있다.한마디로 지구상에서 가장 똑똑한 사람들이 고안해 낸 가장 어려운 문제라는 설명이다.
이제까지 벤치마크에서도 MMLU와 같은 테스트는 꽤 어려운 것으로 평가됐다. 이는 STEM(과학, 기술, 공학, 수학)이나 인문학, 사회과학 등 57개 분야에 대한 다지선다 문제로 구성됐다.
하지만 '클로드 3.5 소네트'가 88.7%, 'GPT-4'가 86.4%의 정답률을 기록하는 등 90점에 가까운 모델이 등장하며, 이제는 변별력이 없어졌다는 평가다.
특히 헨드릭스 이사는 MMLU를 구축하는 데 참여한 인물로, 일론 머스크 CEO가 설립한 xAI의 안전 고문이기도 하다. 머스크 CEO는 그에게 "'이건 학부 수준이다. 나는 세계적 수준의 전문가가 할 수 있는 것들을 원한다"라고 지적했다.
그래서 만든 것이 인류의 마지막 시험이다.
이 테스트셋은 2단계의 필터링 과정을 거쳤다. 먼저, 제출된 문제는 주요 AI 모델이 풀도록 했다.
모델이 답할 수 없는 경우나 개관식에서 찍기보다 점수가 나쁠 경우에만 채택됐다. 이는 인간 전문가에게 전달, 문제를 가다듬고 정답을 확인했다. 최고 수준의 문제를 제출한 전문가는 문제당 500~5000달러(약 71만6000~716만원)를 받았다.

문제 3개를 제출한 케빈 저우 캘리포니아대학교 버클리 이론 입자 물리학 박사는 "질문은 대학원 시험에서 볼 수 있는 상위 범위에 속한다"라고 설명했다.
이 벤치마크로 6개의 첨단 모델을 테스트했다. 그 결과, 모든 모델은 10%를 맞추는 데에도 실패했다. 여기에서도 딥시크의 'R1'은 9.4%의 정답률로, o1의 8.3%를 제치고 1위를 차지했다.
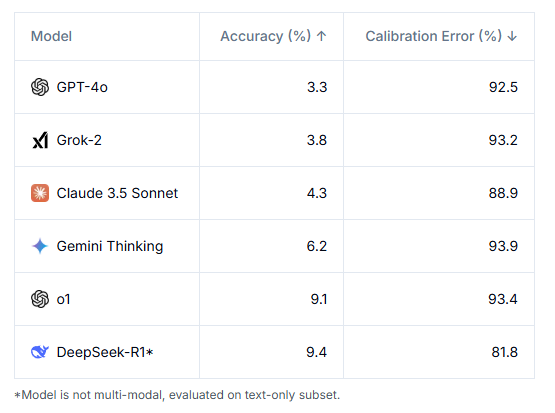
하지만 헨드릭스 이사는 "점수가 빠르게 상승, 연말에는 주요 모델이 50%를 넘어설 가능성이 있다"라고 말했다. 그 시점이 되면 AI가 모든 인간 전문가를 뛰어넘는 수준, 즉 AGI를 달성했다고 보는 것이 타당하다는 설명이다. 동시에 복잡한 경제 시스템을 분석하는 능력이나 더 고차원의 과학 및 수학 문제로 구성된 새 벤치마크를 구축할 필요가 생길 것이라고 내다봤다.
특히 이번 벤치마크에 참여한 서머 유에 스케일 AI 연구 책임자는 "인간조차 아직 답을 모르는 영역에서 AI가 답을 내놓는 벤치마크도 등장할 것"이라는 예측을 내놓았다.
하지만 AI의 가장 큰 문제는 박사급 지식을 갖추기는 했지만, 인간 어린아이라도 풀 수 있는 간단한 문제에 취약한 '불균형성'이다. 이 때문에 아직도 커뮤니티에서는 새 모델이 등장하면 "스트로베리(Streawberry)에 'r'이 몇개인가"라는 질문부터 던진다.
이 때문에 이번 벤치마크에 질문을 제출한 저우 박사도 "AI 모델이 복잡한 문제에 답하는 데 종종 인상적이기는 하지만, 나와 동료들에게 위협이 된다고 생각하지 않는다"라고 말했다.
그는 "시험을 보는 것과 실무 물리학자이자 연구자가 되는 것 사이에는 큰 차이가 있다"라며 "고급 질문에 답할 수 있는 AI조차도 본질적으로 덜 구조화된 연구에는 큰 도움이 되지 않을 경우가 많다"라고 덧붙였다.
이 밖에도 최근에는 인공일반지능(AGI) 달성 여부를 가리기 위한 벤치마크도 주목받고 있다. 오픈AI의 o3 테스트로 유명한 프랑수아 숄레의 'ARC-AGI'와 오픈AI의 자금 지원으로 논란을 빚은 에포크 AI의 '프론티어매스(FrontierMath)' 등이 대표적이다.
임대준 기자 ydj@aitimes.com
- ‘회전하는 도형 안의 공’으로 AI 벤치마킹..."딥시크가 오픈AI보다 뛰어나"
- o3 테스트 담당 연구원, 'AGI 벤치마크' 업그레이드 나서
- 에포크 AI, o3 벤치마크 개발에 오픈AI 자금 지원 사실 감춰 논란
- GPT-4o·클로드도 2% 밖에 풀지 못하는 고난이도 수학 벤치마크 등장
- "시각 언어 모델은 '부정' 이해 못해"...새로운 벤치마크로 문제 해결
- 딥시크' R1', 오픈AI 'o1'과 본격 비교..."오픈 소스·효율성 앞서지만 안전은 문제"
- '딥시크 충격'에 미국 휘청...엔비디아, 미국 주식 사상 최대 손실 기록
- 오픈AI, AI 에이전트 '딥 리서치' 공개...'딥시크' 정확도 2.8배 기록
- 오픈AI·딥시크도 1%대에 그친 강력한 AGI 벤치마크 등장
- "AGI는 일반화 능력 필수...벤치마크도 '무상태 결정' 넘어서야"
- 메타 "인기 벤치마크 ‘SWE-벤치 베리파이드’서 허점 발견"
