카카오(대표 정신아)는 지난해 개발자 컨퍼런스 ‘이프카카오(if KAKAO)’에서 공개한 인공지능(AI) 모델 ‘카나나’의 연구 성과를 담은 테크니컬 리포트를 아카이브(ArXiv)에 공개했다고 27일 밝혔다.
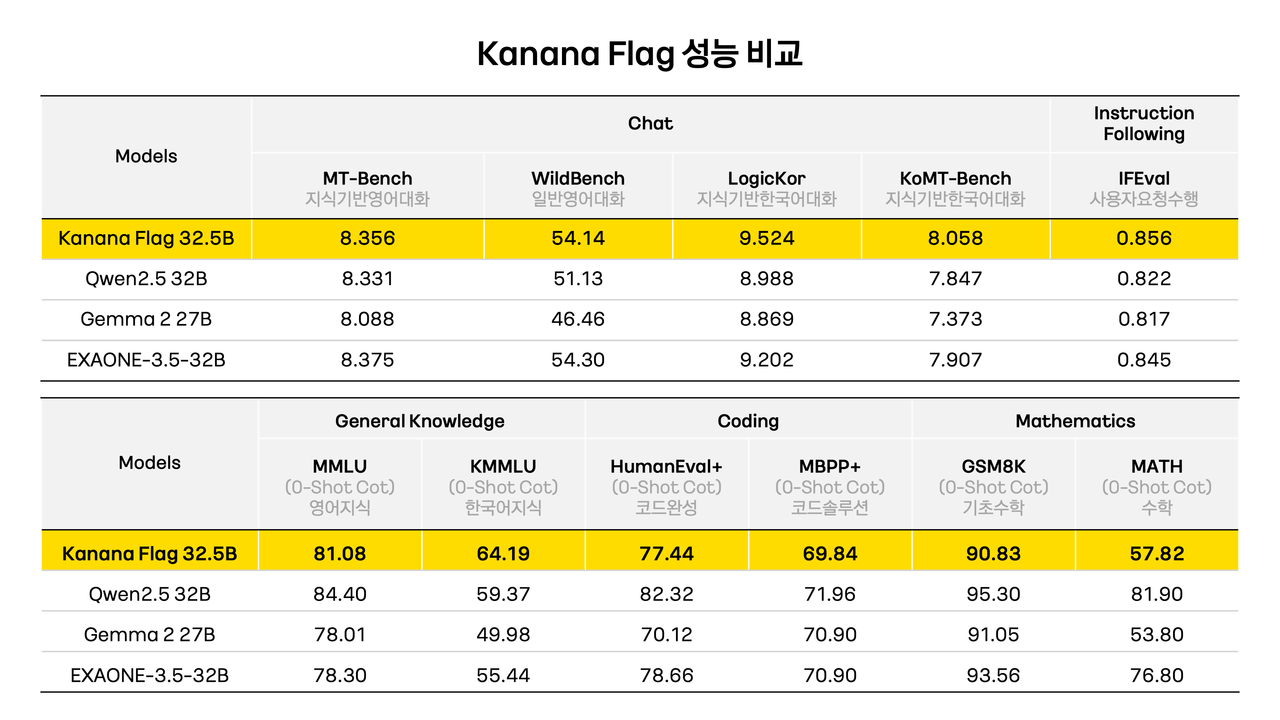
지난해 컨퍼런스에서 개발 중이라고 말했던 '카나나 플래그(Flag)'도 개발이 완료, 한국어와 영어, 코딩, 수학 등에서 유사한 크기의 모델들과 성능을 비교했다.
벤치마크 결과, 카나나 플래그(32.5B)는 비슷한 크기의 '큐원2.5(32B)'보다 한국어 지식과 지식 기반 한국어에서 성능이 앞섰다. 영어, 코딩, 수학 능력을 테스트하는 지표에서는 성능이 떨어지는 것으로 드러났다. 다만, 영어 능력을 평가하는 MT-벤치와 MMLU에서는 별 차이가 없었다.
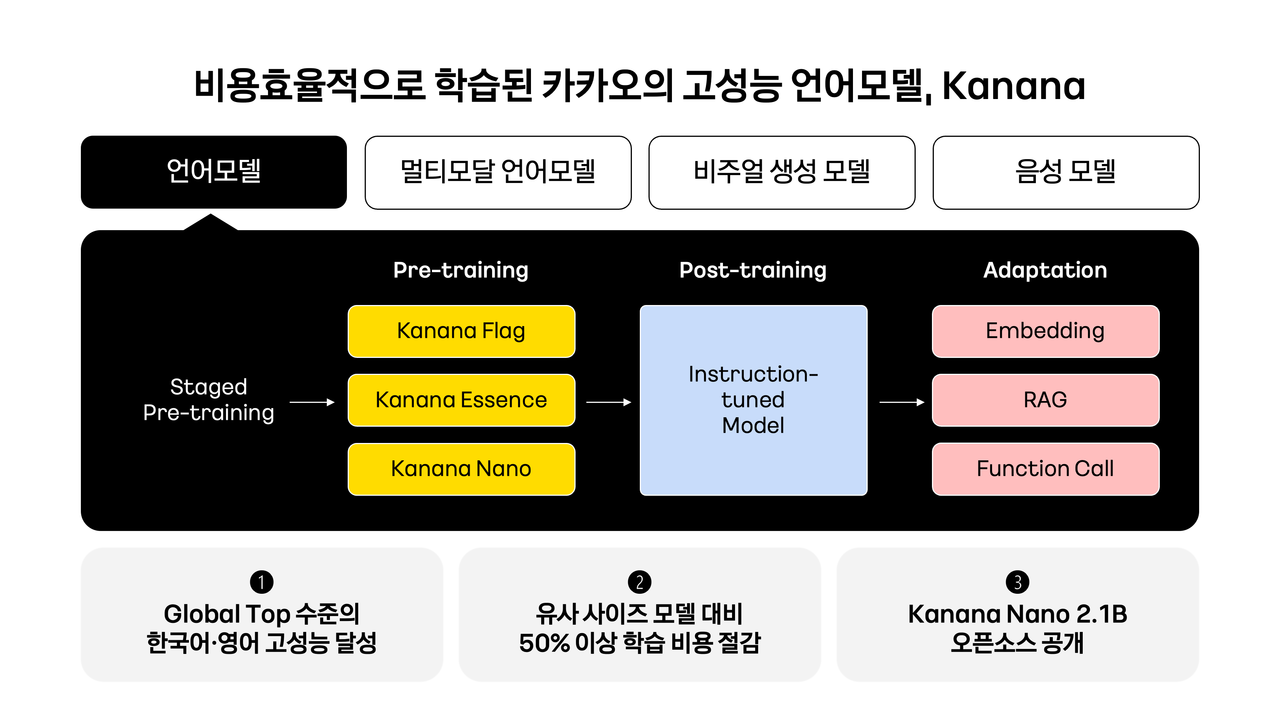
카카오는 '비용 효율성'이 카나나의 강점이라고 주장했다. 개발 과정에서 학습 자원 최적화를 통해 유사 사이즈의 모델 대비 50% 이상 비용을 절감했다고 밝혔다.
학습 효율을 극대화하기 위해 ▲단계별 사전학습(Staged pre-training) ▲가지치기(Pruning) ▲증류(Distillation) ▲깊이 업스케일링(DUS) 등을 적용했다.
카카오는 향후 카나나 모델에 강화 학습(RL)과 연속 학습(CL) 등 기술을 접목해 추론과 수학, 코딩 능력을 강화할 예정이다. 또 정렬(Alignment) 기술을 고도화, 사용자 요청의 수행 정확도를 높일 계획이다.
"이를 통해 음성, 이미지, 영상 등 다양한 형태로 소통 가능하도록 지속적 모델 고도화를 이어가며, 일상에 실질적인 가치를 더하는 기술로 자리잡을 수 있도록 기술 경쟁력을 강화해 갈 예정"이라고 전했다.
한편, 카카오는 테크니컬 리포트 공개와 동시에 소형모델 ‘카나나 나노 2.1B’ 베이스 모델과 인스트럭트(Instruct) 모델, 임베딩(Embedding) 모델을 깃허브에 오픈 소스로 공개했다.
이는 온디바이스 환경에서도 활용 가능한 크기로, 비슷한 로벌 모델에 견줄만한 성능을 갖췄다고 전했다. 지난달 카카오 공식 테크블로그를 통해 공개한 바와 같이, 한국어와 영어 처리 능력에서 뛰어난 결과를 보여준다.
카카오는 이번 오픈 소스 공개를 통해 AI 기술의 접근성을 높이고, 연구자와 개발자들이 다양한 응용을 시도할 수 있도록 모델의 업데이트를 지속 지원할 계획이다.
김병학 카나나 성과리더는 “모델 최적화와 경량화 기술을 바탕으로 라마, 젬마 등 글로벌 AI 모델과 견줄 수 있는 고성능의 자체 언어모델 라인업을 효율적으로 확보하게 됐다"라며 "이번 오픈 소스 공개를 통해 국내 AI 생태계 활성화에 기여할 수 있을 것으로 기대한다”라고 말했다.
또 “앞으로도 효율과 성능 중심의 실용적이고 안전한 AI 모델을 개발해가며, 지속적 기술 혁신을 통해 AI 경쟁력을 강화해 갈 계획”이라고 덧붙였다.
박수빈 기자 sbin08@aitimes.com
